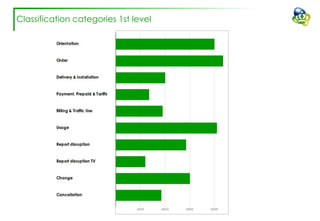
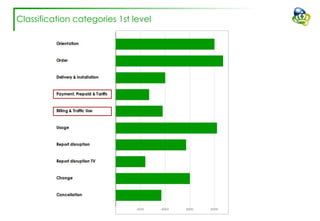
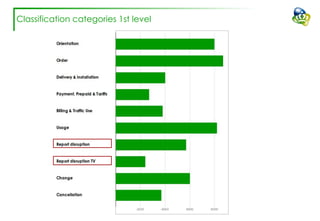
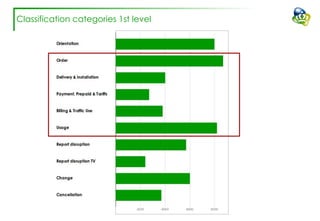
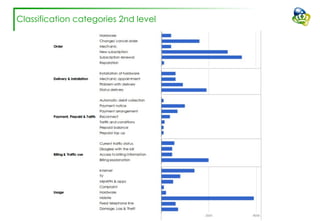
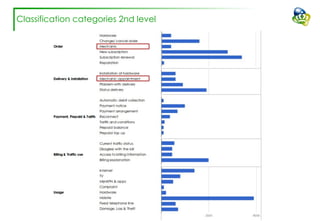
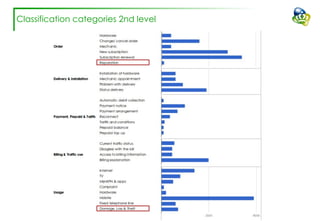
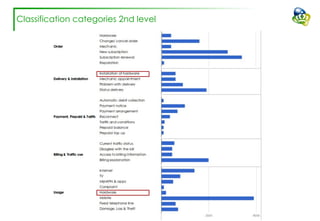
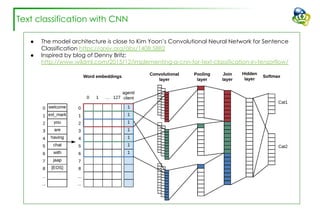
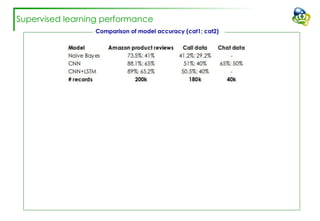
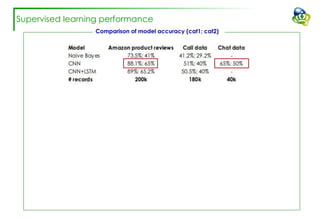
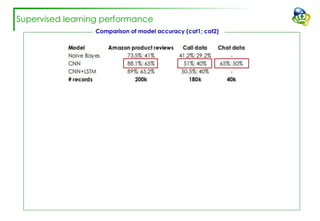
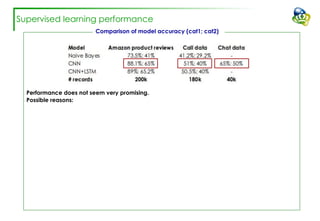
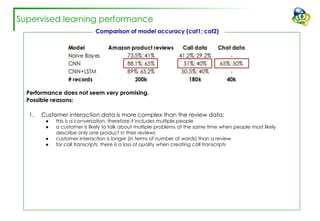
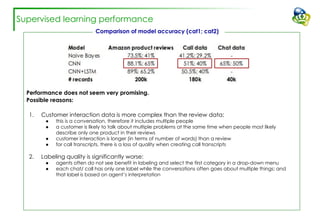
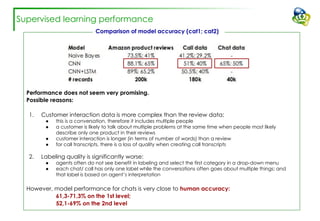
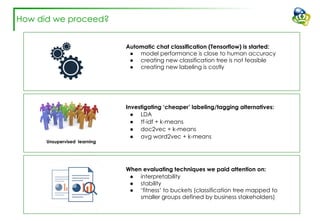
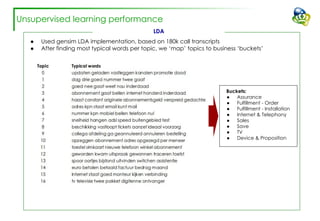
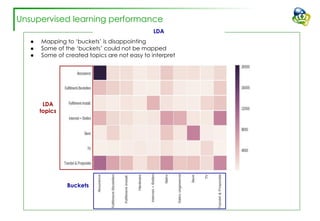
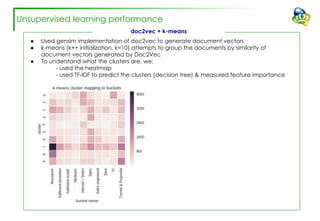
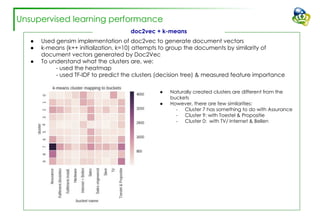
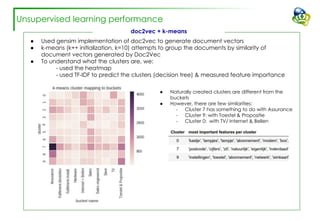
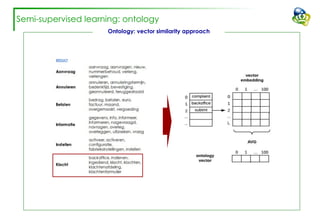
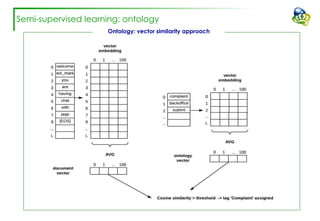
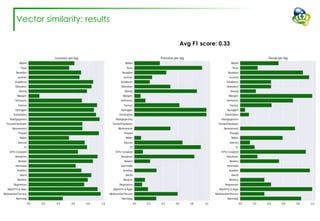
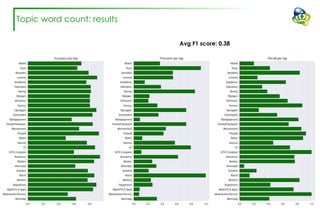
The document discusses efforts to improve the classification accuracy of customer contact transcriptions through various supervised and unsupervised learning algorithms, given challenges with manual classification accuracy and data complexity. Despite testing a range of models, including CNN and LSTM, the results showed limited promise, leading to exploration of alternative strategies like LDA and doc2vec for topic modeling. The outcomes indicated the need for better-defined categories and improved labeling strategies, with some unsupervised methodologies providing insights but lacking stability and interpretability.



































![[PythonPH] Transforming the call center with Text mining and Deep learning (C...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonphtransformingthecallcenterwithtextmininganddeeplearningcasestudyuber-180929062748-thumbnail.jpg?width=640&height=640&fit=bounds)



































