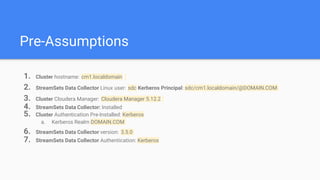
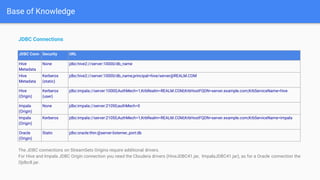
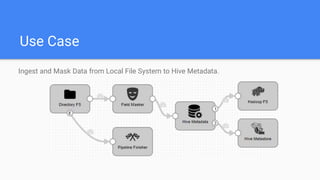
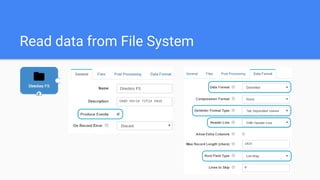
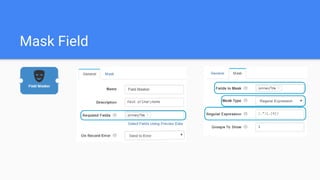
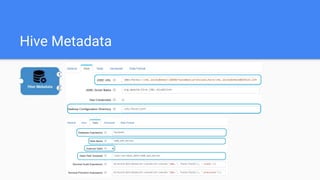
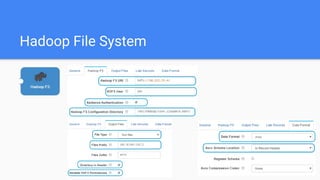
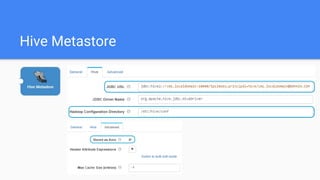
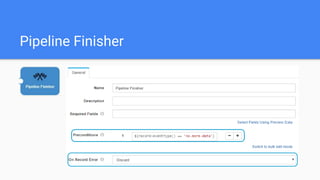
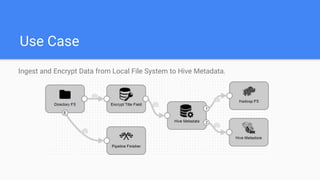
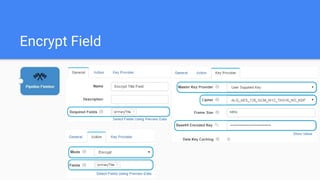
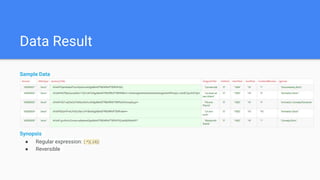
This document outlines the implementation of a GDPR-compliant solution within Cloudera architecture using StreamSets Data Collector, focusing on data discovery, governance, and protection without incurring additional financial costs. It details the prerequisites for cluster setup, JDBC connections for Hive and Impala, and provides use cases for both data masking and encryption when ingesting data from local files to Hive metadata. The approach aims to balance data protection with utilization by employing various methods to handle sensitive information appropriately.