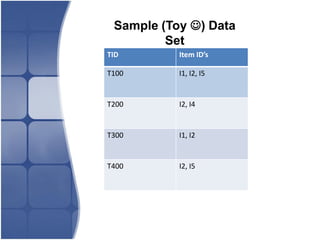
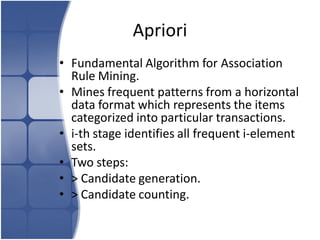
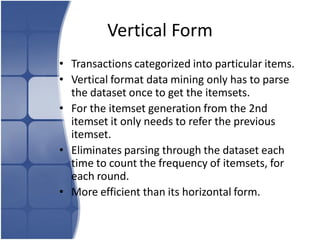
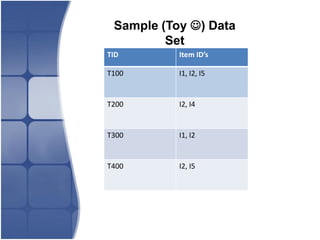
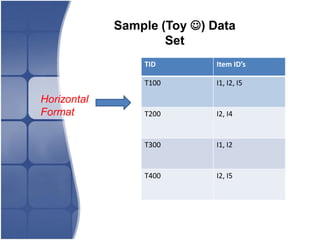
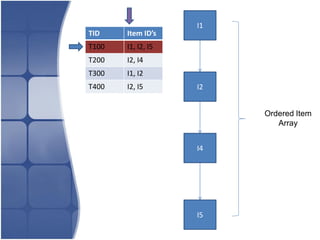
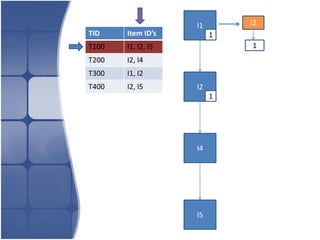
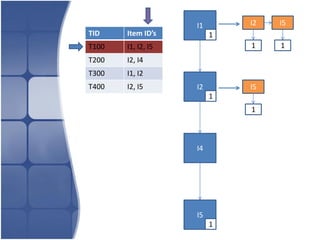
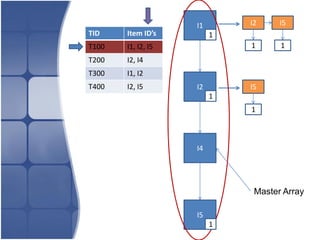
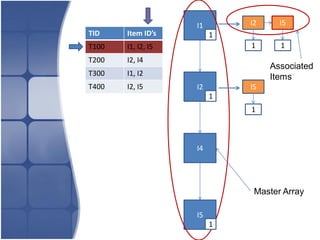
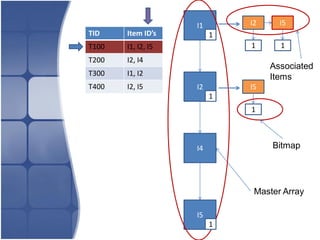
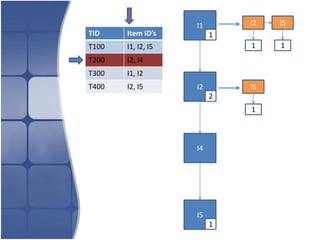
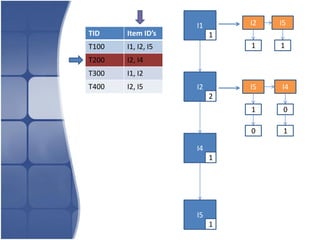
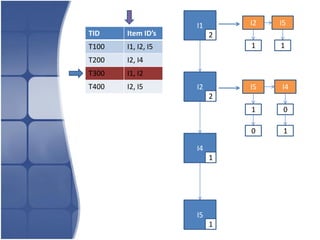
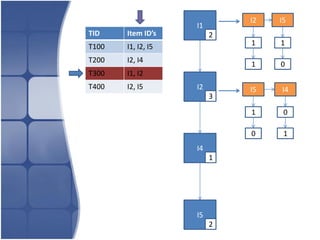
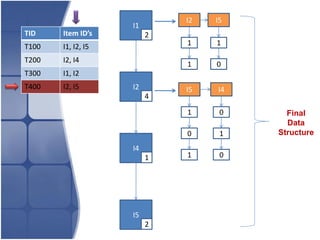
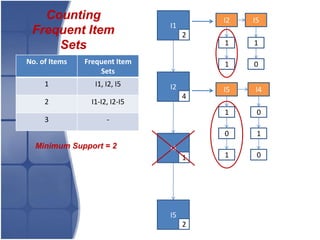
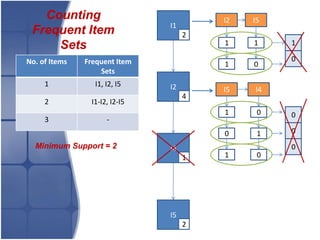
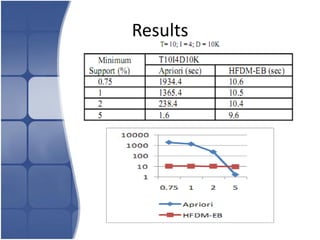
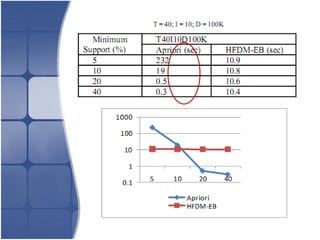
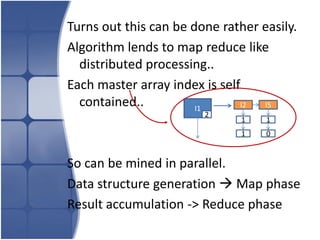
The document proposes leveraging the efficiencies of bitmap operations and vertical data formats to perform association rule mining in a distributed environment. It describes how a horizontal transactional dataset can be converted to a vertical bitmap structure by mapping each item to its transactions in a single pass. This vertical bitmap structure then facilitates efficient mining of frequent itemsets. The algorithm is amenable to distributed processing by mapping each item index to separate processes for parallel mining, followed by result aggregation. Further optimizations like using C instead of Java and bitmap compression techniques are suggested to improve performance.