Download to read offline


![[Overview] Introduction Autshumato Project Text Anonymisation Processing of Data Future Work Introduction Autshumato Project Text Anonymisation Future Work 18 May 2010](https://image.slidesharecdn.com/groenewald-100805012646-phpapp02/85/Processing-Parallel-Text-Corpora-for-Three-South-African-Language-Pairs-in-the-Autshumato-Project-2-320.jpg)












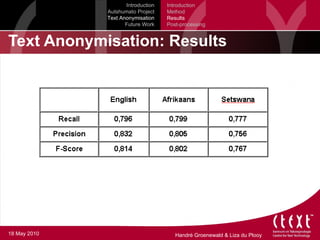




The document discusses the Autshumato Project which aims to develop machine translation tools for South African languages. There are 11 official languages in South Africa but most information is only available in English. The project is developing parallel text corpora for language pairs using statistical machine translation. It also describes the development of a text anonymization tool to allow sensitive information to be removed from documents so translation data can be shared while protecting privacy. The anonymization process identifies named entities using rules and gazetteers and replaces them to preserve syntactic context for machine learning. Future work includes expanding the anonymization system by improving entity identification.














































