Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Tokyo Institute of Technology
PDF, PPTX
96 views
Graph Convolution Networks For Text Classification
Graph Convolution Networks For Text Classification
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 23
2
/ 23
3
/ 23
4
/ 23
5
/ 23
6
/ 23
7
/ 23
8
/ 23
9
/ 23
10
/ 23
11
/ 23
12
/ 23
13
/ 23
14
/ 23
15
/ 23
16
/ 23
17
/ 23
18
/ 23
19
/ 23
20
/ 23
21
/ 23
22
/ 23
23
/ 23
More Related Content
PDF
Windowsにおけるメール環境の構築
by
Tokai University
PPTX
Recurrent Neural Network
by
KozoChikai
PDF
Mxnetによるデープラーニングでセミの抜け殻を識別する
by
dokechin
PDF
Predicting Power Relations between Participants in Written Dialog from a Sing...
by
Hiroshi Matsumoto
PDF
Graph Convolutional Networks for Classification with a Structured LebalSpace
by
Kazusa Taketoshi
PDF
Disconnected Recurrent Neural Networks for Text Categorization
by
harmonylab
PPTX
Graph conv
by
TakuyaKobayashi12
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
Windowsにおけるメール環境の構築
by
Tokai University
Recurrent Neural Network
by
KozoChikai
Mxnetによるデープラーニングでセミの抜け殻を識別する
by
dokechin
Predicting Power Relations between Participants in Written Dialog from a Sing...
by
Hiroshi Matsumoto
Graph Convolutional Networks for Classification with a Structured LebalSpace
by
Kazusa Taketoshi
Disconnected Recurrent Neural Networks for Text Categorization
by
harmonylab
Graph conv
by
TakuyaKobayashi12
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
Similar to Graph Convolution Networks For Text Classification
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PPTX
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
PDF
[DL輪読会]Convolutional Sequence to Sequence Learning
by
Deep Learning JP
PPTX
Graph Convolutional Network 概説
by
KCS Keio Computer Society
PDF
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
PDF
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
PPTX
Neural Concept Network v0.2 (ja)
by
AkihiroYamamoto
PDF
拡がるディープラーニングの活用
by
NVIDIA Japan
PDF
Relation Classification via Convolutional Deep Neural Network (Zeng et al.)
by
marujirou
PPTX
Knowledge_graph_alignment_with_entity-pair_embedding
by
Ace12358
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
Text Categorization
by
cympfh
PPTX
Neural Concept Network v0.3 (ja)
by
AkihiroYamamoto
PPTX
Combinatorial optimization with graph convolutional networks and guided
by
Shuntaro Ohno
PPTX
Combinatorial optimization with graph convolutional networks and guided ver20...
by
Shuntaro Ohno
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
SakataMoriLab GNN勉強会第一回資料
by
ttt_miura
[DL輪読会]Convolutional Sequence to Sequence Learning
by
Deep Learning JP
Graph Convolutional Network 概説
by
KCS Keio Computer Society
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
Learning Convolutional Neural Networks for Graphs
by
Takuya Akiba
Neural Concept Network v0.2 (ja)
by
AkihiroYamamoto
拡がるディープラーニングの活用
by
NVIDIA Japan
Relation Classification via Convolutional Deep Neural Network (Zeng et al.)
by
marujirou
Knowledge_graph_alignment_with_entity-pair_embedding
by
Ace12358
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
Text Categorization
by
cympfh
Neural Concept Network v0.3 (ja)
by
AkihiroYamamoto
Combinatorial optimization with graph convolutional networks and guided
by
Shuntaro Ohno
Combinatorial optimization with graph convolutional networks and guided ver20...
by
Shuntaro Ohno
Graph Convolution Networks For Text Classification
1.
Graph Convolution Networks for Text
Classification Liang Yao, Chengsheng Mao, Yuan Luo
2.
GCNに関して • GCNが有効な理由のひとつ • 各ノードが持つ特徴量だけではなく、ノード間の関係も学習に含まれる •
1 message passingは • layer構造が一つの場合に対応するのでは? • #layer >2の場合、あまり精度が変わらない • ノード間でお互いに影響しうる情報が #layer 2で収束しているためかも • ノード間の影響力がそれほど強くない • 更に、考えるとこの結果はデータ依存の結果ではないか? • Streaming 処理ができれば嬉しいな。
3.
背景 • 文書分類問題 • 文書に一個あるいは複数のラベルをつけること •
応用 • news filtering、spam detectionなど • 文書表現 • bag-of-words、n-grams、word2vec • 最近は、DL modelを使った文書表現の学習も盛んになっている • 意味的な情報や構文的情報は学習可能 • (コーバス範囲での)単語共起関係は無視されるため、non-consecutive semanticsと long-distanceは学習不可能
4.
本研究 • GCNを使った文書分類手法を提案 • GCNを使うことによって、単語間、単語と文書間、文書間の関係もモ デリングに考慮することが可能に •
結果 • 従来手法より優れた文書分類結果が得られた • 文書分類と同時に、単語と文書のembeddingを得ることが可能に • ラベル付きデータの割合が少ない場合でも、良い結果が得られた • ソースコード: https://github.com/yao8839836/text_gcn
5.
関連研究(1) • 特徴量エンジニアリング • bag-of-words •
n-grams • 文書自体を単語グラフに変換 => グラフ分類問題 • 本研究では、文書の表現を自動的に学習 • アルゴリズム • 深層学習技術の活用 • word embedding based modelの構築 • word embeddingをモデルの前処理として行う • 本研究では、結果として出力される • 既存deep neural networkの利用 : (CNN, RNN, LSTM) • 単語のlocal consecutive関係は学習できる • しかし、コーパス範囲でのグローバル的な関係は考慮されない
6.
関連研究(2) • Graph Neural
Networks • Grid structure • Bruna 2014, Henaff, Bruna and LeCun 2015など • Graph structure • GCN関連研究 • GCNを使った自然言語処理では、大体文書間の関係を用いてグラ フを作成している • 本研究では、グラフノードとして、単語と文書、両方を用いる
7.
提案手法: グラフ作成(1) • 単語、文書をノードとするグラフの構築 •
理由:(コーパス範囲で)グローバル単語共起関係が学習可能になるため • 各ノード初期状態特徴量: X = 単位ベクトル (one-hot) • 単語と文書間エッジ • 単語の出現関係 • 重み:TF-IDF • 単語と単語間エッジ • 単語同士の共起関係 • 重み:PMI (Point-wise mutual information、自己相互情報量) • self-loop エッジ重み:1
8.
提案手法: グラフ作成(2) • PMI
(Point-wise mutual information、自己相互情報量) • PMIが正の値の場合 (PMIが正値の場合のみ、エッジ生成) • xとyが一緒に出現しやすい. (独立よりも)共起しやすい傾向にある. • PMIが負の場合 • xとyが一緒に出現しにくい. (独立よりも)共起しにくい傾向にある. • PMIが0の場合 • xとyの関連がない. それぞれ独立に出現する. • 正の値, 負の値の絶対値が大きいほど傾向が強い.
9.
提案手法: 出力関数 • 単語、文書をノードとするグラフを用いてGCN
modelを 学習する • 出力関数 • X: 特徴量、W0 / W1: モデルパラメータ、A: 隣接行列
10.
提案手法: 損失関数 • 単語、文書をノードとするグラフを用いてGCN
modelを 学習する • Loss Function • Ydf : ラベル付き文書集合
11.
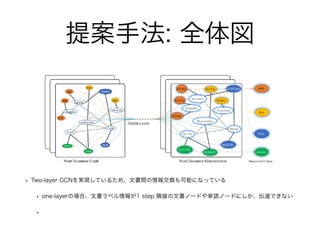
提案手法: 全体図 • Two-layer
GCNを実現しているため、文書間の情報交換も可能になっている • one-layerの場合、文書ラベル情報が1 step 隣接の文書ノードや単語ノードにしか、伝達できない •
12.
実験: 目的 • 主に2方面 •
文書分類タスクにおいて、十分な性能を出しているの か? 教師データが少ない場合でも、上手く分類できる? • モデル学習で、同時に行なわれた単語、文書embedding 結果は有効な結果なのか?
13.
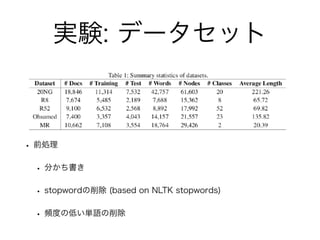
実験: データセット • 前処理 •
分かち書き • stopwordの削除 (based on NLTK stopwords) • 頻度の低い単語の削除
14.
実験: 設定 • Layer
1の embedding size : 200 • window size : 20 (共起計算で使う) • Learning rate : 0.02 • Dropout rate : 0.5 • 最適化: 200 epochs by Adam
15.
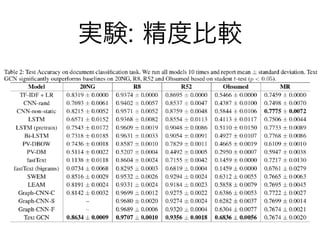
実験: 精度比較
16.
考察 • TextGCNが有効である理由 • The
text graph can capture both document-word relations and global word-word relations • 各ノードが持つ情報は自分自身と隣接ノードの情報をもとに計算されるため • 単語ノード • bridge、 key path • 隣接文書のラベル情報を集めて、次の文書に伝える役割を果たす • 例外として、MRにおいては、LSTMに負ける結果となっている • 理由1: TextGCNは単語共起関係を考慮しているが、順序関係が無視されているため • 理由2: MRデータは、スパースなデータになっている (文書が短いので#edgesが少ない)
17.
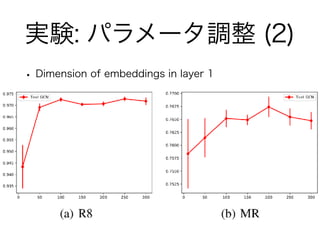
実験: パラメータ調整 (1) •
Window size of co-occurrence
18.
実験: パラメータ調整 (2) •
Dimension of embeddings in layer 1
19.
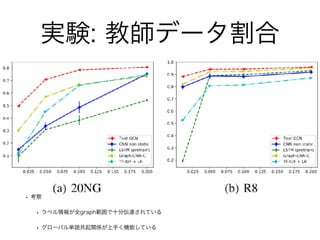
実験: 教師データ割合 • 考察 •
ラベル情報が全graph範囲で十分伝達されている • グローバル単語共起関係が上手く機能している
20.
実験: 文書分類可視化
21.
実験: 単語可視化
22.
実験: 文書カテゴリの詳細
23.
まとめと課題 • まとめ • Text-GCNを提案した •
グラフデータの作成で、単語の共起関係を応用 • 結果として、既存手法より良い精度を持つモデルが作成できた • 課題 • attention mechanismの利用 • 教師なし学習への拡張
Download





























![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)











