Downloaded 157 times



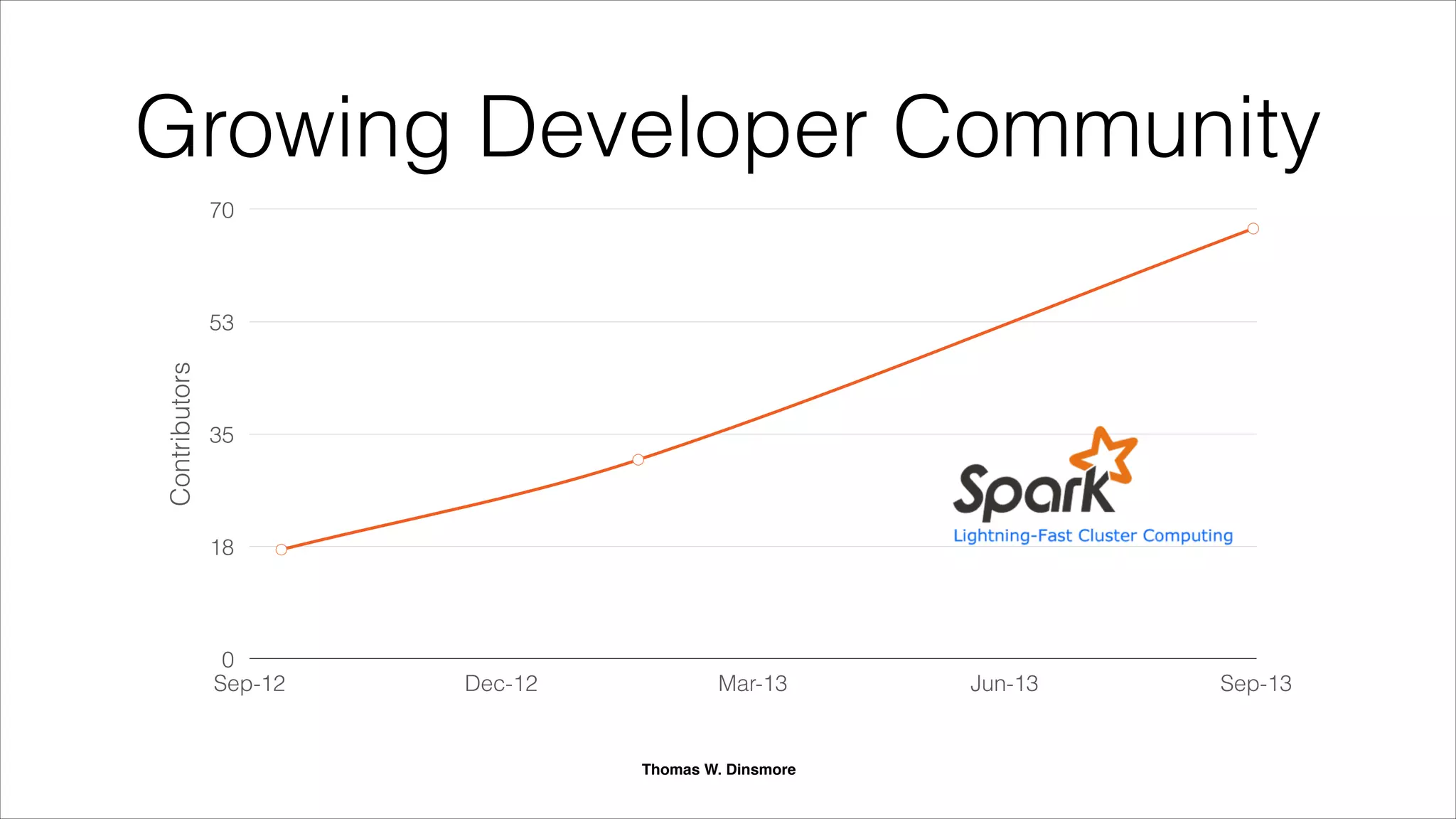
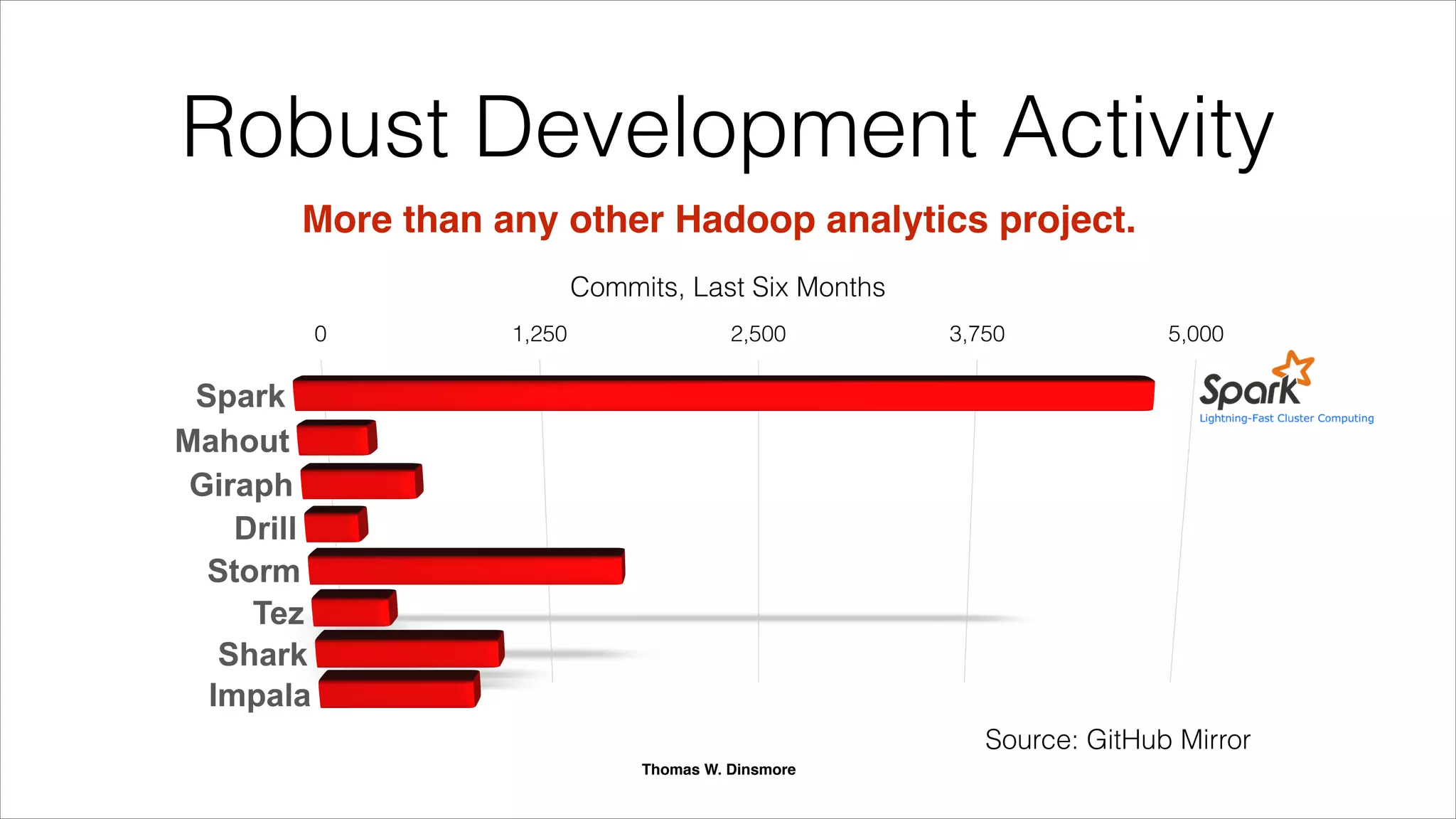






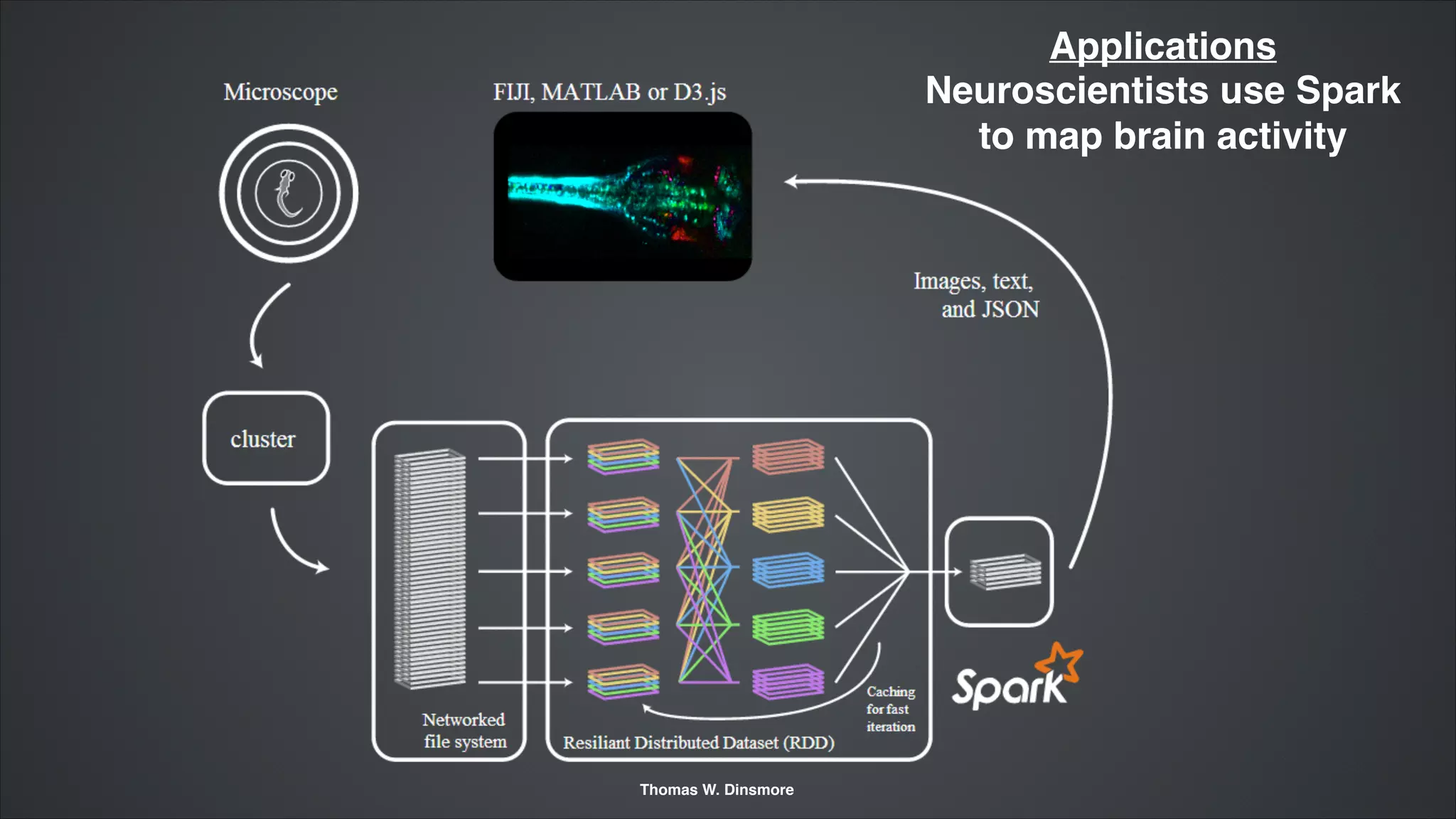














Apache Spark is an emerging open-source distributed in-memory analytics engine designed for advanced analytics on large datasets, compatible with Hadoop. It addresses limitations of MapReduce by allowing data to be processed in memory and offers a unified platform for various analytics use cases, including machine learning and streaming. Supported by major companies and actively developed, Spark is considered a leading successor to MapReduce with significant performance improvements.










































































