The document summarizes research on using predictive modeling to predict how well people perform specific exercises at the gym based on data from wearable sensors. It describes applying classification tree and random forest models to a dataset containing sensor data from participants performing bicep curls. Classification trees work by recursively splitting the data into partitions to predict the exercise class, while random forests create many classification trees and have the trees vote to make predictions. The models were able to accurately predict the exercise class based on the sensor data.




![5
fileUrl <- "http://groupware.les.inf.puc-rio.br/static/WLE/Wear
ableComputing_weight_lifting_exercises_biceps_curl_variations.csv"
download.file(fileUrl, destfile="./data.csv")
}
# Insert the dataset in R enviroment by converting all null values
# to missing values (NA's)
data <- read.csv("data.csv", header = TRUE, sep = ",", quote = """, na
.strings=c("NA",""))
There are 39242 observations and 159 variables in the dataset. It is important to
check if all variables are useful or if we can ignore some, in order to produce a more
accurate prediction model.
Firstly, we can ignore the first 6 variables as they don't include any actual measure
data. Then it's very important to have a look on how many missing values each
column has. It appears that 100 variables consist of more than 98%
missing values. On the other hand, the remaining 59 have almost none. It is clear
that we have to ignore all 100 variables with the missing values and the first 6
variables. So the final "processed" dataset will consist of 53 variables. The
following script includes the appropriate R code
# Create a dataframe with the sum of missing values per column
data.na <- as.data.frame(apply(X=data,2,FUN=function(x) length(which(is
.na(x)))))
names(data.na) <- "Missing Values"
# Keep the columns that contain Non-missing values (NA's)
data1 <- data[,colSums(is.na(data)) < 2]
# Delete the first 7 columns, because they are not important for the pr
edictive
# modelling
data1 <- data1[,7:59]
# Exclude remaining rows that contains missing data
data1 <- na.omit(data1)
So the final dataset consists of 39241 observations and 53 variables. It is also
important to check how many observations of each class outcome exist. There are
more than 11000 observations with class "A" as outcome and around 6500-7500
observations for each of the rest classes (B,C,D,E) which is not bad (enough cases
from each class).](https://image.slidesharecdn.com/b848aa52-cecb-4258-8742-6a07da5b67b7-150702052628-lva1-app6891/85/Final-Project-6-320.jpg)





![12
testing dataset will be used only once, in order to test the prediction model that
we've build on the training dataset. It is mandatory, as it is common to build a good
prediction model on a dataset (low in the sample error) but the same model
performs poorly on new data (out of sample error). This is known as over-fitting.
# set seed (in order all results to be fully reproducible) and create a
75-25 %
# partition for our data based on class variable
set.seed(1)
inTrain = createDataPartition(data1$classe, p = 3/4)[[1]]
# Assign the 75% of observations to training data
training1 = data1[inTrain,]
# Assign the remaining 25 % of observations to testing data
testing1 = data1[-inTrain,]
The fist prediction model was build by using the classification/Decision Trees
algorithm. In particular rpart method of the caret package was used in R. Then we
plotted the decision tree.
# Set seed (in order all results to be fully reproducible) and apply a
prediction
#Model with all variables
set.seed(1)
model.all <- train(classe ~ ., method="rpart", data = training1)
# Plot the Classification/Decision Tree
fancyRpartPlot(model.all$finalModel)](https://image.slidesharecdn.com/b848aa52-cecb-4258-8742-6a07da5b67b7-150702052628-lva1-app6891/85/Final-Project-13-320.jpg)
![13
In order to check the accuracy rate of the model, we print the confusion Matrix. The
accuracy rate (around 50%) is low, so a further investigation is necessary. It is a
good idea to try a new algorithm on the training data.
# Apply the prediction
prediction <- predict(model.all, newdata= training1)
# Check the accuracy of the prediction model by printing the confusion
matrix.
print(confusionMatrix(prediction, training1$classe), digits=4)
## Confusion Matrix and Statistics
##
## Reference
## Prediction A B C D E
## A 7600 2375 2373 2122 762
## B 137 1898 156 893 740
## C 612 1422 2604 1809 1495
## D 0 0 0 0 0
## E 20 0 0 0 2414
##
## Overall Statistics
##
## Accuracy : 0.4932
## 95% CI : (0.4875, 0.4989)
## No Information Rate : 0.2844
## P-Value [Acc > NIR] : < 2.2e-16](https://image.slidesharecdn.com/b848aa52-cecb-4258-8742-6a07da5b67b7-150702052628-lva1-app6891/85/Final-Project-14-320.jpg)
![14
##
## Kappa : 0.3379
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: A Class: B Class: C Class: D Class: E
## Sensitivity 0.9081 0.33327 0.50731 0.0000 0.44613
## Specificity 0.6377 0.91886 0.78032 1.0000 0.99917
## Pos Pred Value 0.4989 0.49634 0.32788 NaN 0.99178
## Neg Pred Value 0.9458 0.85173 0.88232 0.8361 0.88899
## Prevalence 0.2844 0.19350 0.17440 0.1639 0.18385
## Detection Rate 0.2582 0.06449 0.08848 0.0000 0.08202
## Detection Prevalence 0.5175 0.12993 0.26984 0.0000 0.08270
## Balanced Accuracy 0.7729 0.62607 0.64381 0.5000 0.72265
Now we apply the random forest algorithm (with randomForest package in R) in
order to build our prediction model for the training dataset. The "in the sample
error" is almost 0%, which is great but it may indicates over-fitting. It is important
to check the out of sample error as well.
# Set seed (in order all results to be fully reproducible) and apply th
e random
# forest algorithm in the training dataset
set.seed(1)
modrf <- randomForest(classe ~. , data=training1)
# Create the prediction vector for the class in the training dataset
predictionsrf1 <- predict(modrf, training1, type = "class")
# Check the accuracy of the prediction model by printing the confusion
matrix.
confusionMatrix(predictionsrf1, training1$classe)
## Confusion Matrix and Statistics
##
## Reference
## Prediction A B C D E
## A 8369 0 0 0 0
## B 0 5695 0 0 0
## C 0 0 5133 0 0
## D 0 0 0 4824 0
## E 0 0 0 0 5411
##
## Overall Statistics
##
## Accuracy : 1
## 95% CI : (0.9999, 1)
## No Information Rate : 0.2844
## P-Value [Acc > NIR] : < 2.2e-16](https://image.slidesharecdn.com/b848aa52-cecb-4258-8742-6a07da5b67b7-150702052628-lva1-app6891/85/Final-Project-15-320.jpg)
![15
##
## Kappa : 1
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: A Class: B Class: C Class: D Class: E
## Sensitivity 1.0000 1.0000 1.0000 1.0000 1.0000
## Specificity 1.0000 1.0000 1.0000 1.0000 1.0000
## Pos Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000
## Neg Pred Value 1.0000 1.0000 1.0000 1.0000 1.0000
## Prevalence 0.2844 0.1935 0.1744 0.1639 0.1838
## Detection Rate 0.2844 0.1935 0.1744 0.1639 0.1838
## Detection Prevalence 0.2844 0.1935 0.1744 0.1639 0.1838
## Balanced Accuracy 1.0000 1.0000 1.0000 1.0000 1.0000
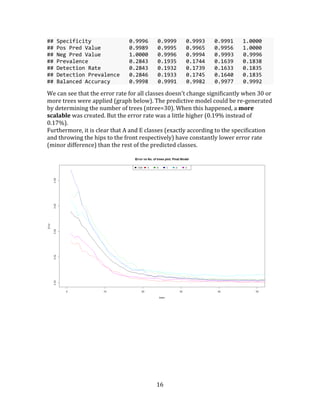
The average "out of sample error" is around 0.17%. The 95% confidence interval
for error rate is between 0.28% and 0.1%.
# Create the prediction vector for the class in the testing dataset
predictionsrf <- predict(modrf, testing1, type = "class")
# Check the accuracy of the prediction model by printing the confusion
matrix.
confusionMatrix(predictionsrf, testing1$classe)
## Confusion Matrix and Statistics
##
## Reference
## Prediction A B C D E
## A 2789 3 0 0 0
## B 0 1895 1 0 0
## C 0 0 1706 6 0
## D 0 0 4 1602 3
## E 0 0 0 0 1800
##
## Overall Statistics
##
## Accuracy : 0.9983
## 95% CI : (0.9972, 0.999)
## No Information Rate : 0.2843
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.9978
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: A Class: B Class: C Class: D Class: E
## Sensitivity 1.0000 0.9984 0.9971 0.9963 0.9983](https://image.slidesharecdn.com/b848aa52-cecb-4258-8742-6a07da5b67b7-150702052628-lva1-app6891/85/Final-Project-16-320.jpg)