EntertainmentAI: New Ways of Engaging with Video @CognitiveAI Meetup #CAIM
•
1 like•625 views

http://thepostersession.com/ http://tagasauris.com

Recommended
Recommended
More Related Content
More from Lora Aroyo
More from Lora Aroyo (20)
Recently uploaded
Recently uploaded (20)
EntertainmentAI: New Ways of Engaging with Video @CognitiveAI Meetup #CAIM
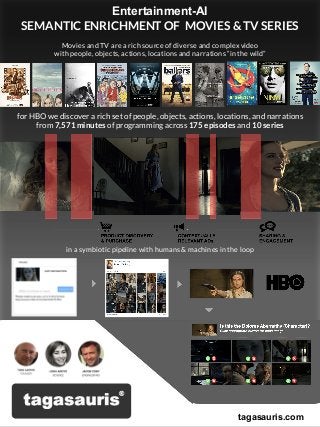
- 1. for HBO we discover a rich set of people, objects, actions, locations, and narrations from 7,571 minutes of programming across 175 episodes and 10 series Movies and TV are a rich source of diverse and complex video with people, objects, actions, locations and narrations “in the wild” in a symbiotic pipeline with humans & machines in the loop tagasauris.com Entertainment-AI SEMANTIC ENRICHMENT OF MOVIES & TV SERIES
- 3. Entertainment-AI COMMERCIALIZING VIDEO MICRO-MOMENTS AI Factory* Augmented Intelligence & Data Network Effects. *U.S. Patent #13/863,751 DYNAMIC SEMANTIC PUBLISHING STACK Linked Media, technology architecture, modeled on state-of-the-art research, combining both human & artificial intelligence