





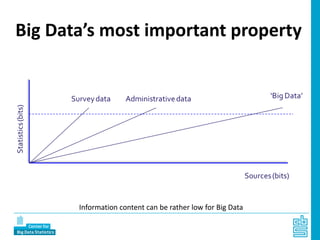



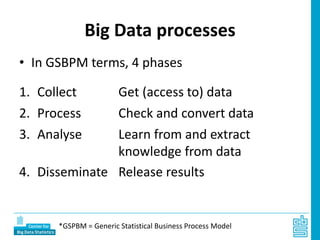

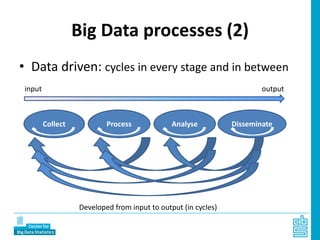




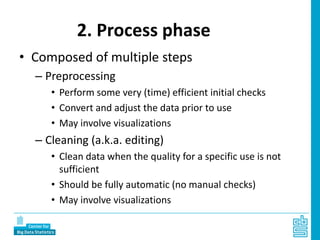




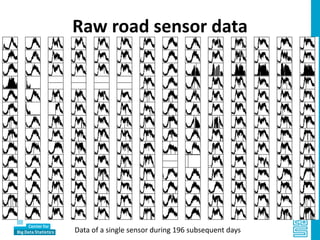

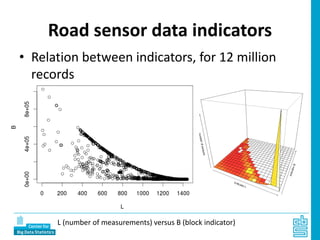


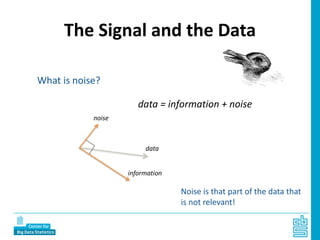
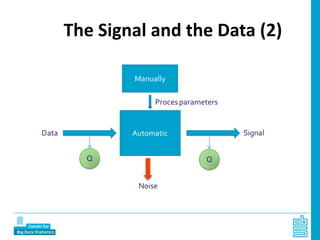


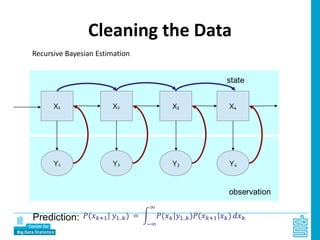
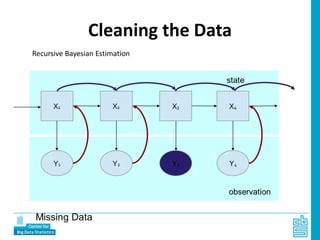
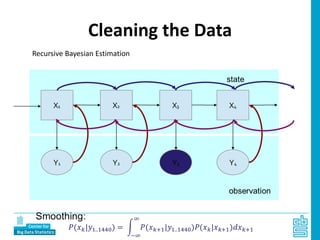


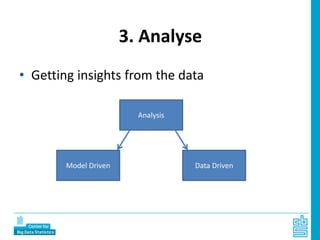
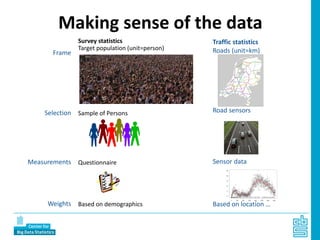

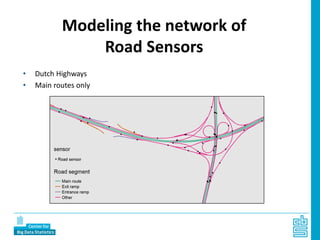
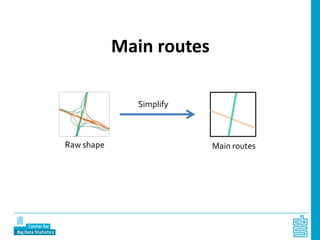
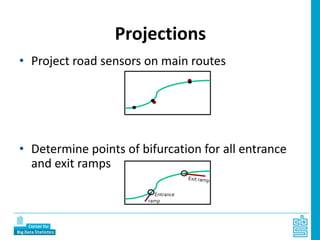
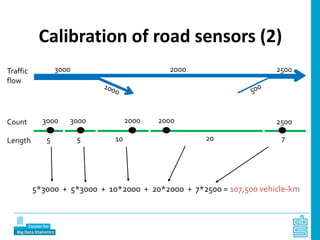






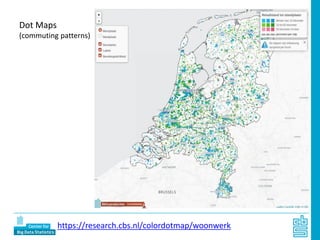
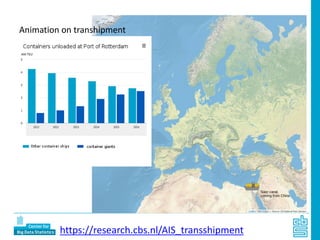


Piet Daas and Marco Puts from Statistics Netherlands presented on big data methods and techniques. They discussed the four phases of working with big data: collect, process, analyze, and disseminate. They provided examples of each phase using road sensor data to measure traffic, scraping company websites to identify innovative firms, and using aerial images to detect solar panels. They emphasized the need to preprocess and clean big data due to its noisy nature. When analyzing big data, they discussed dealing with imbalanced datasets, such as through oversampling rare cases. They concluded by showing examples of visualizing big data results as dot maps and animations.



























































