


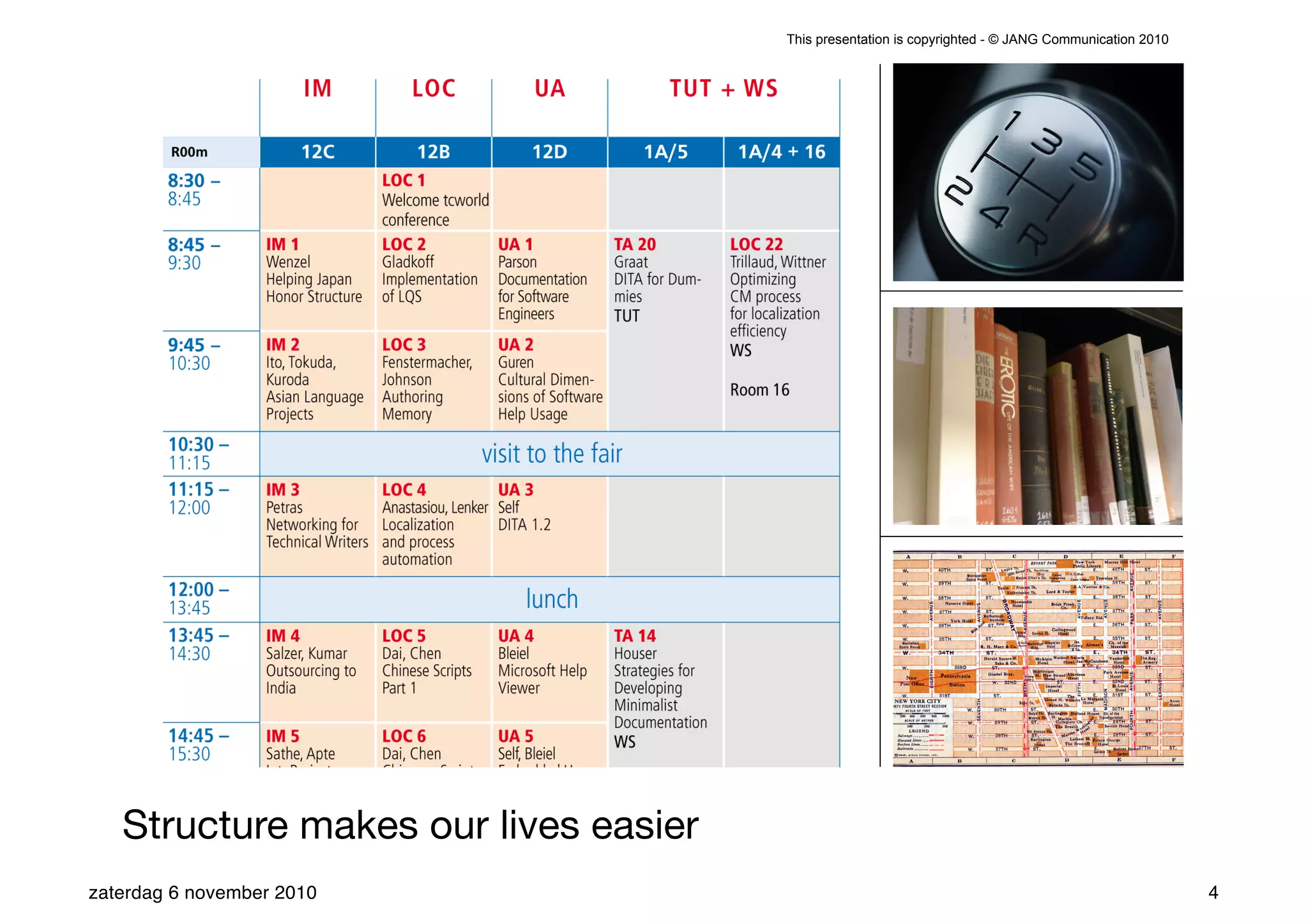


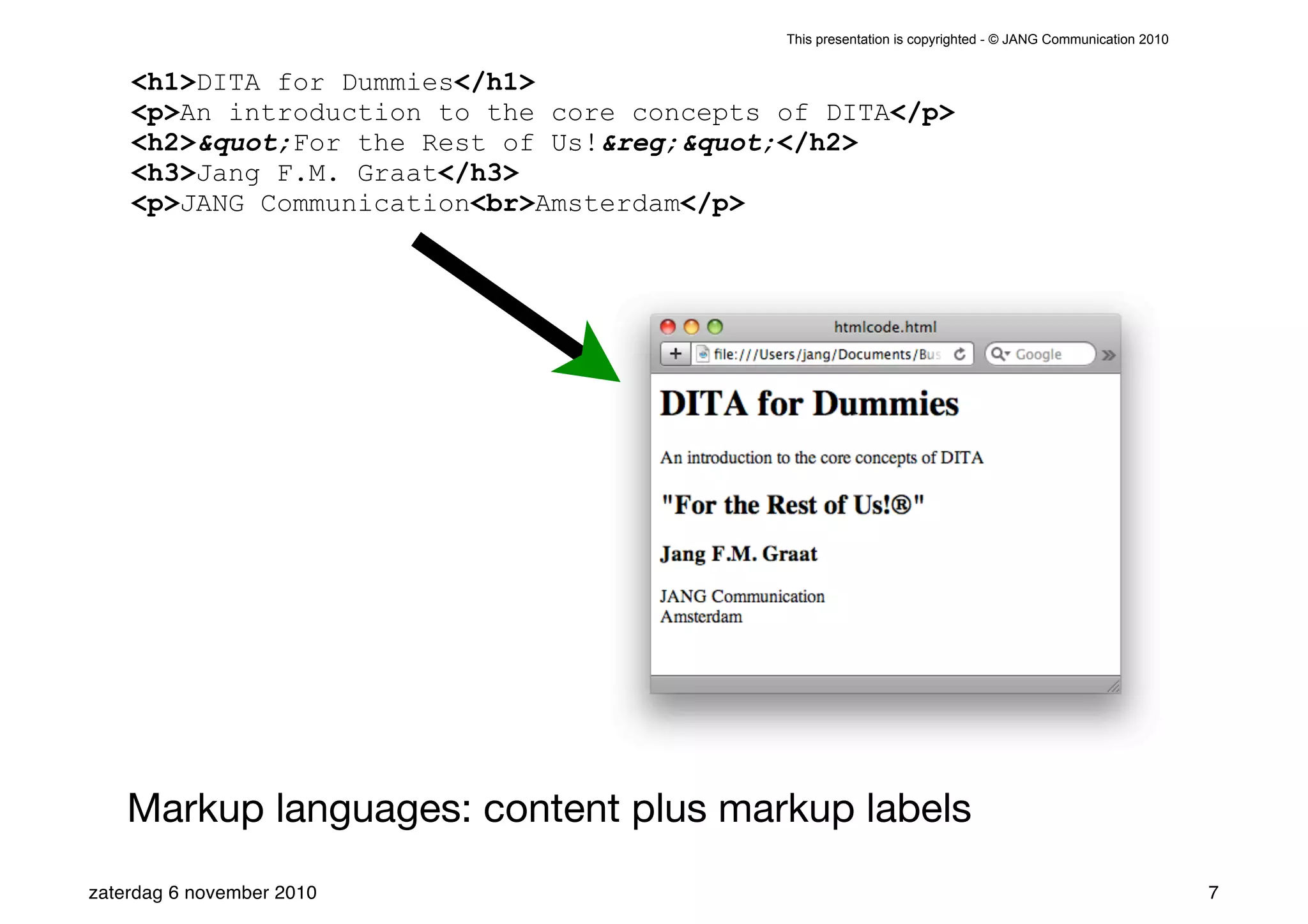
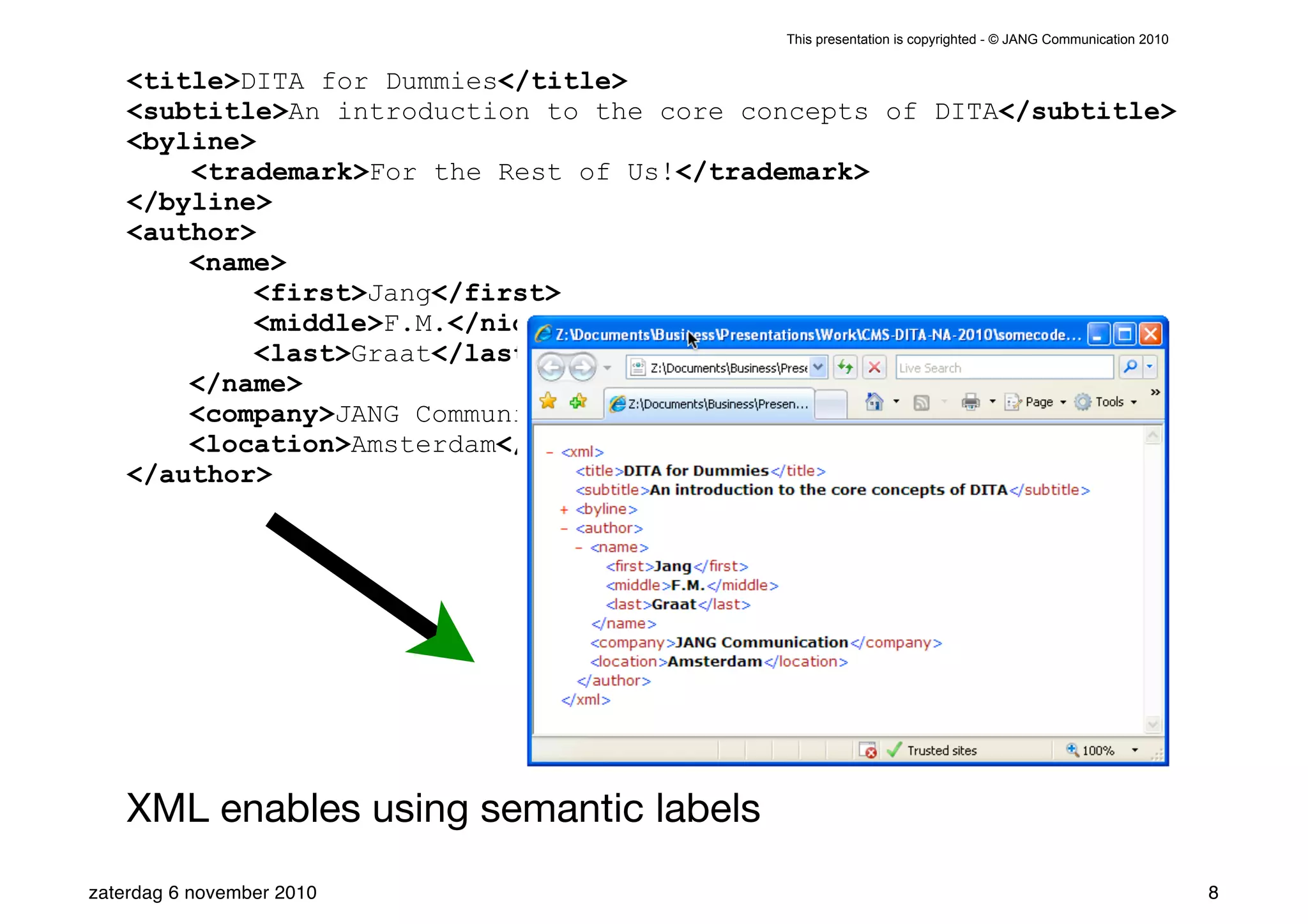









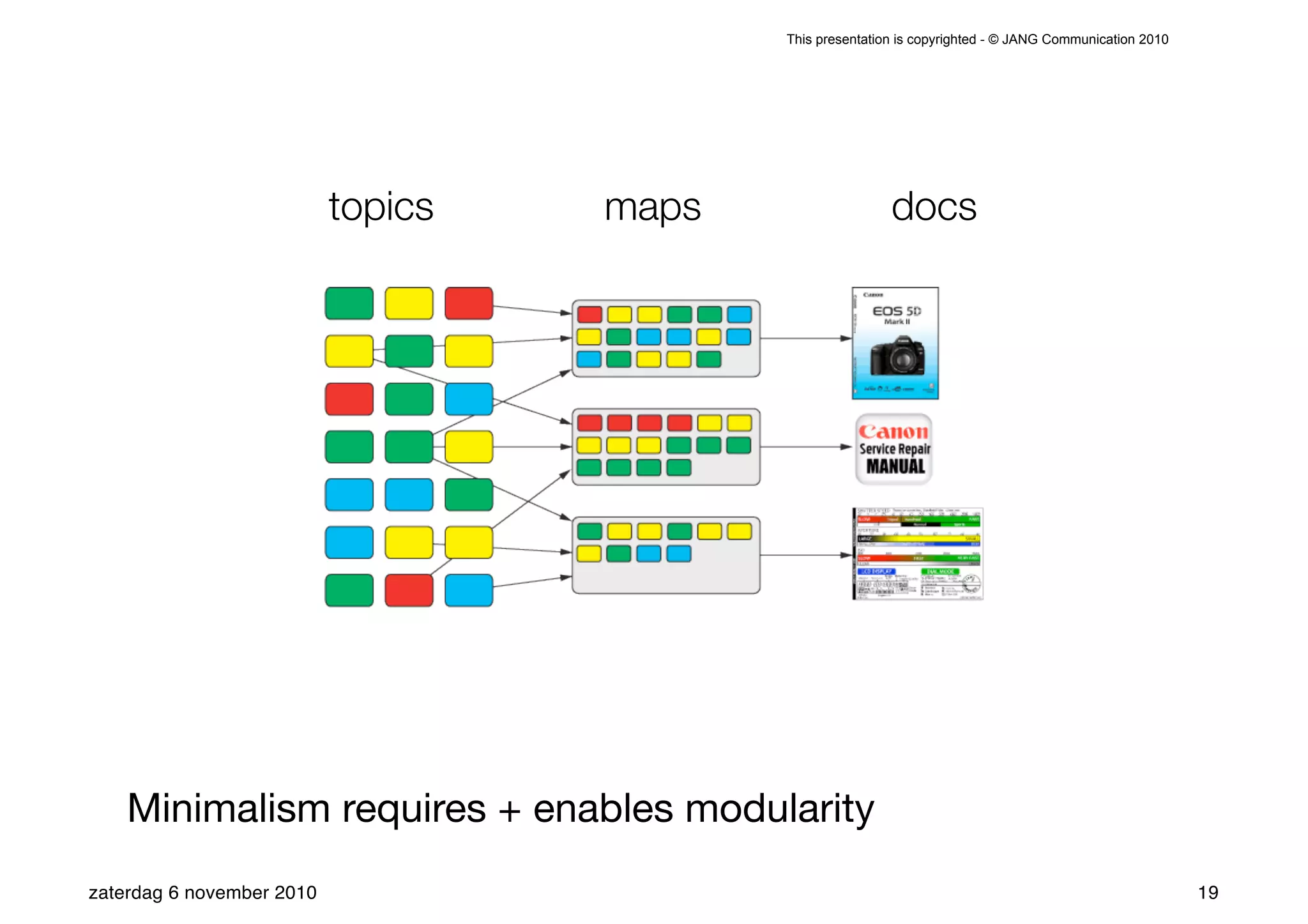



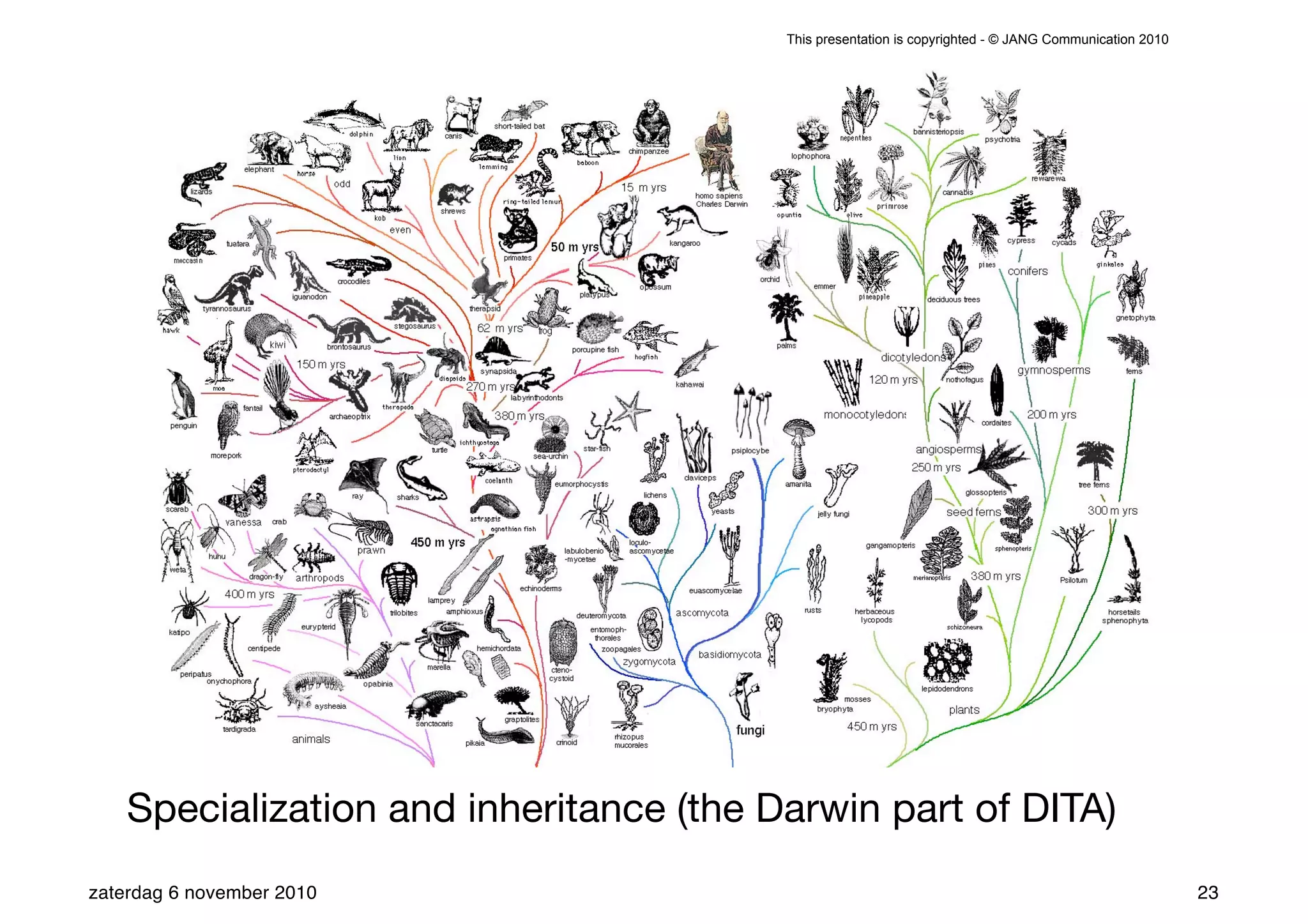
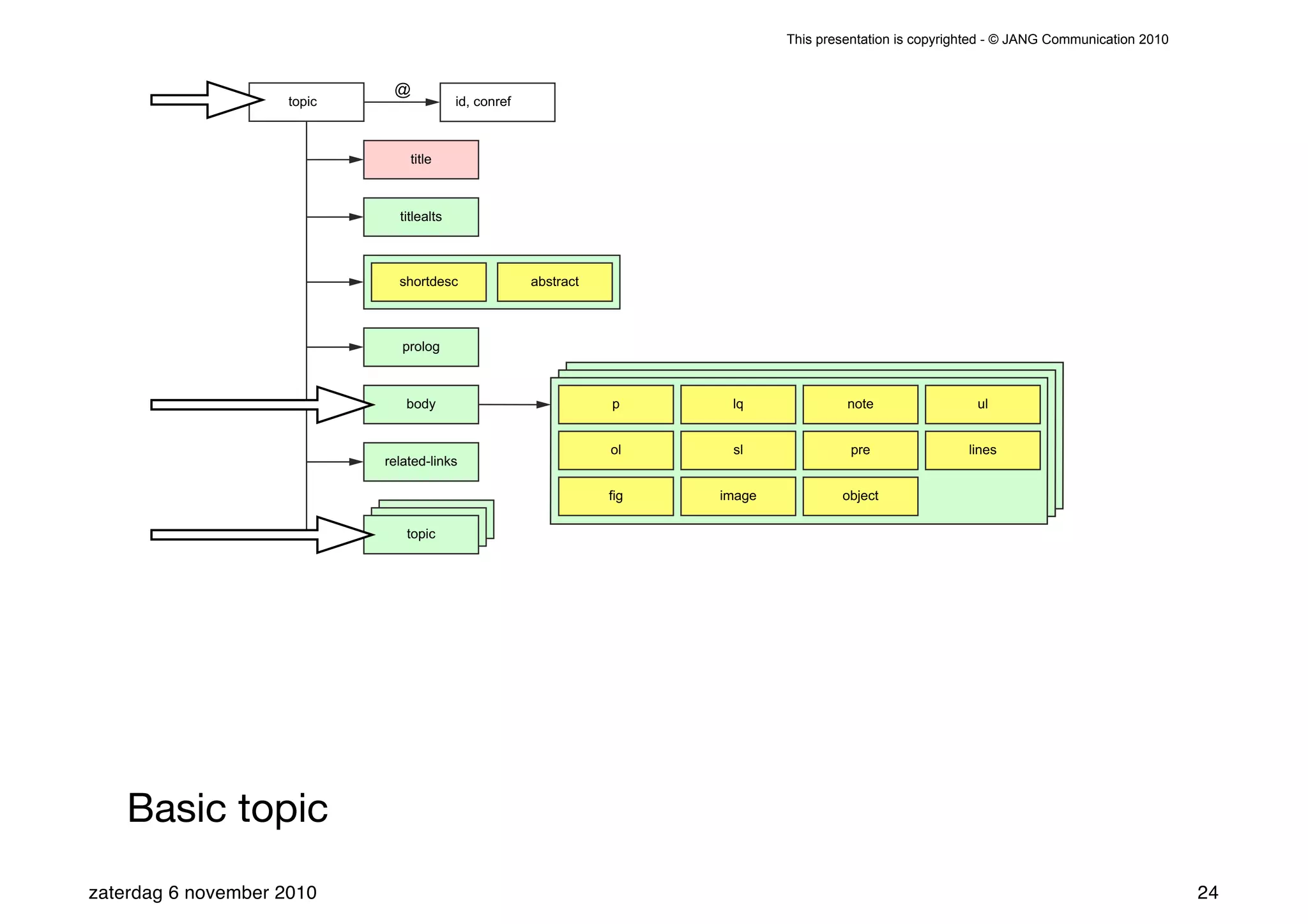
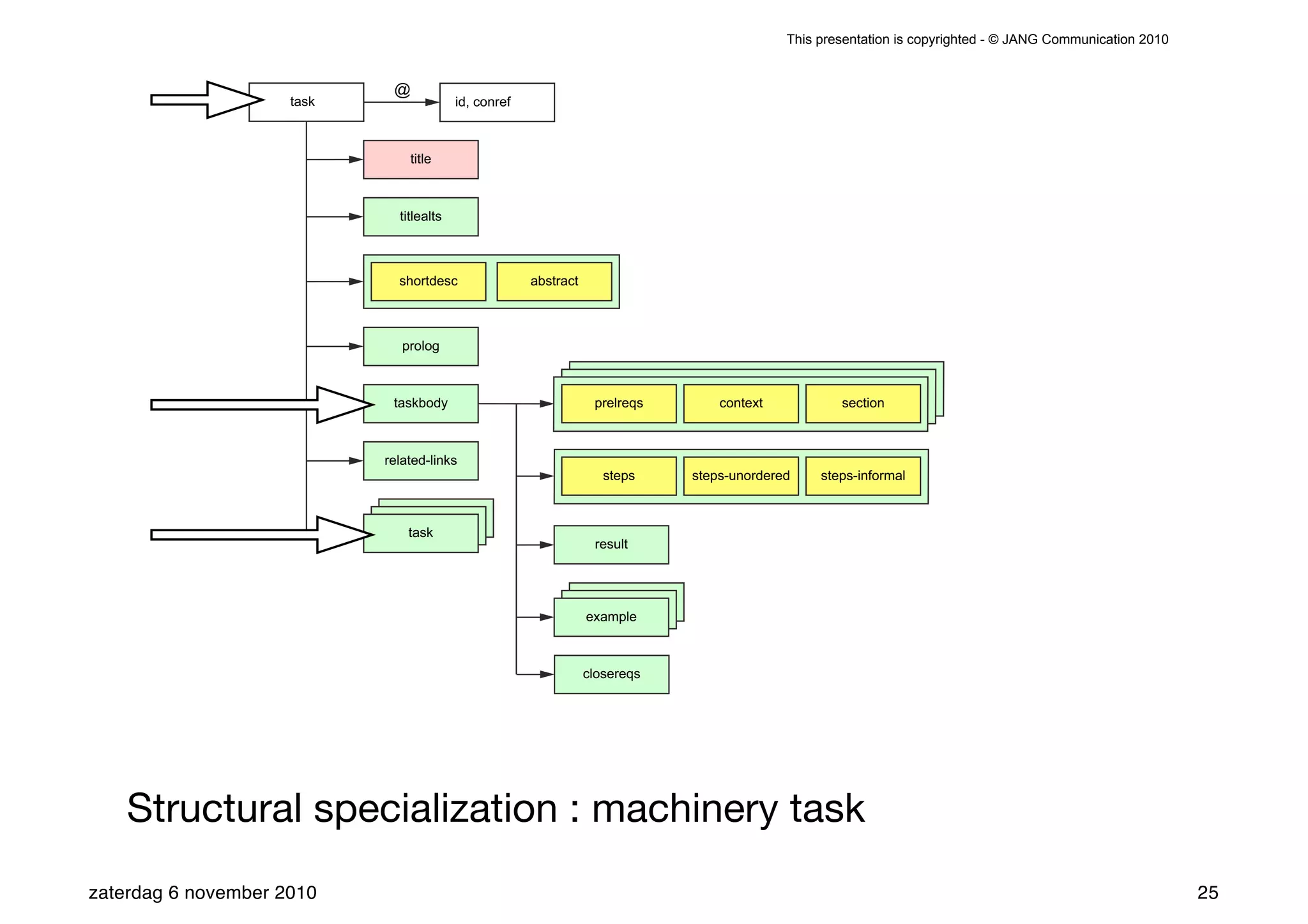
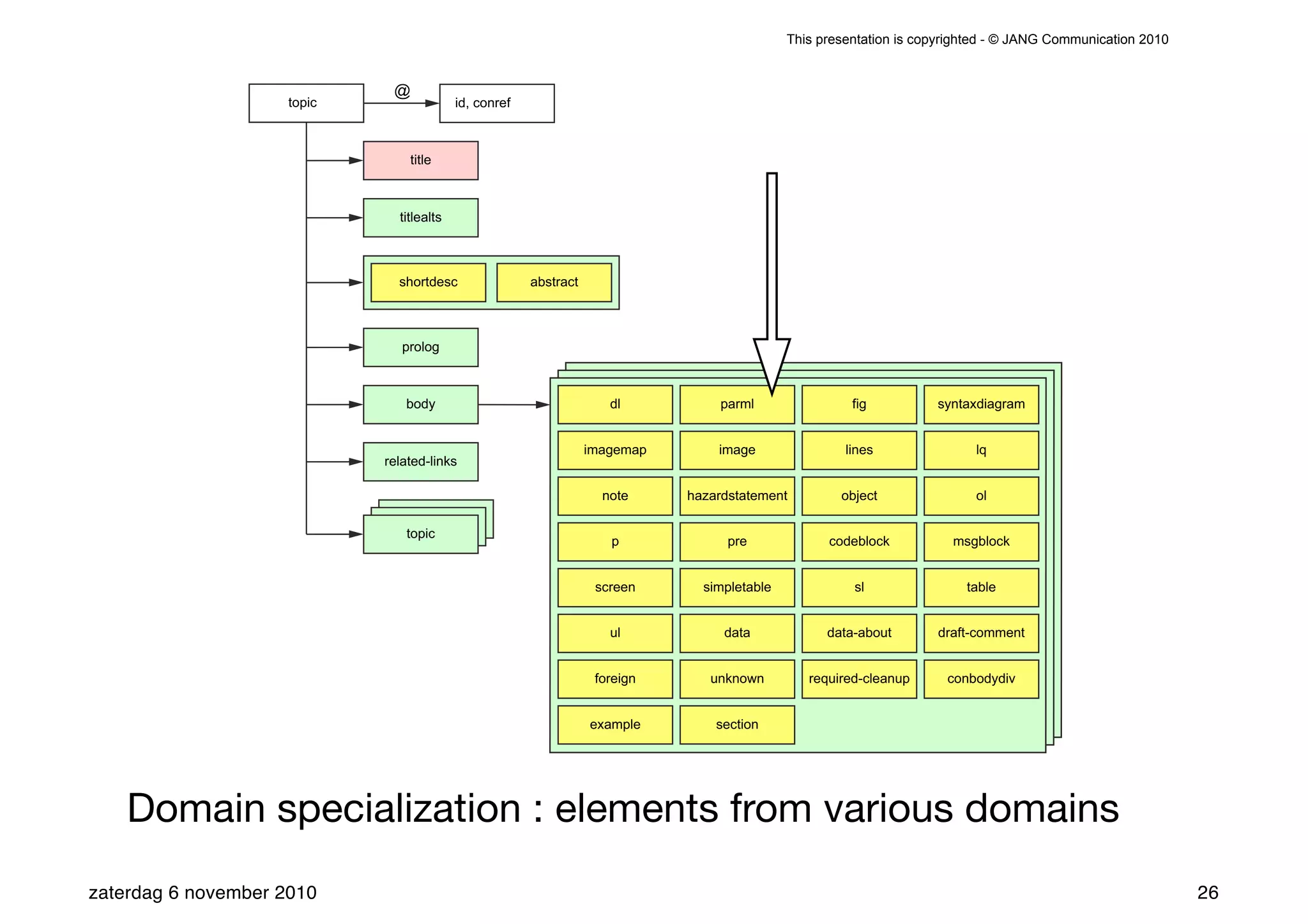




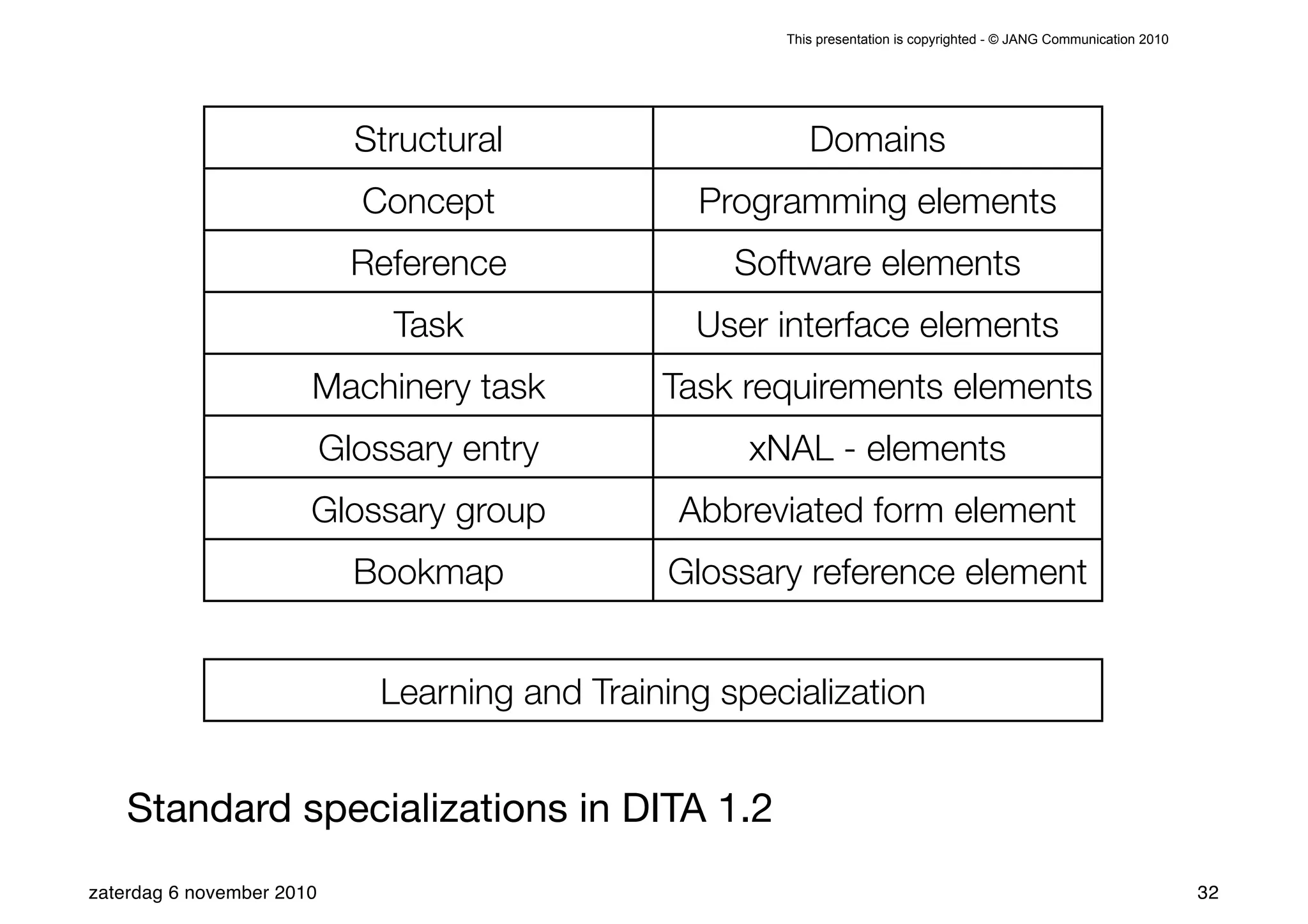


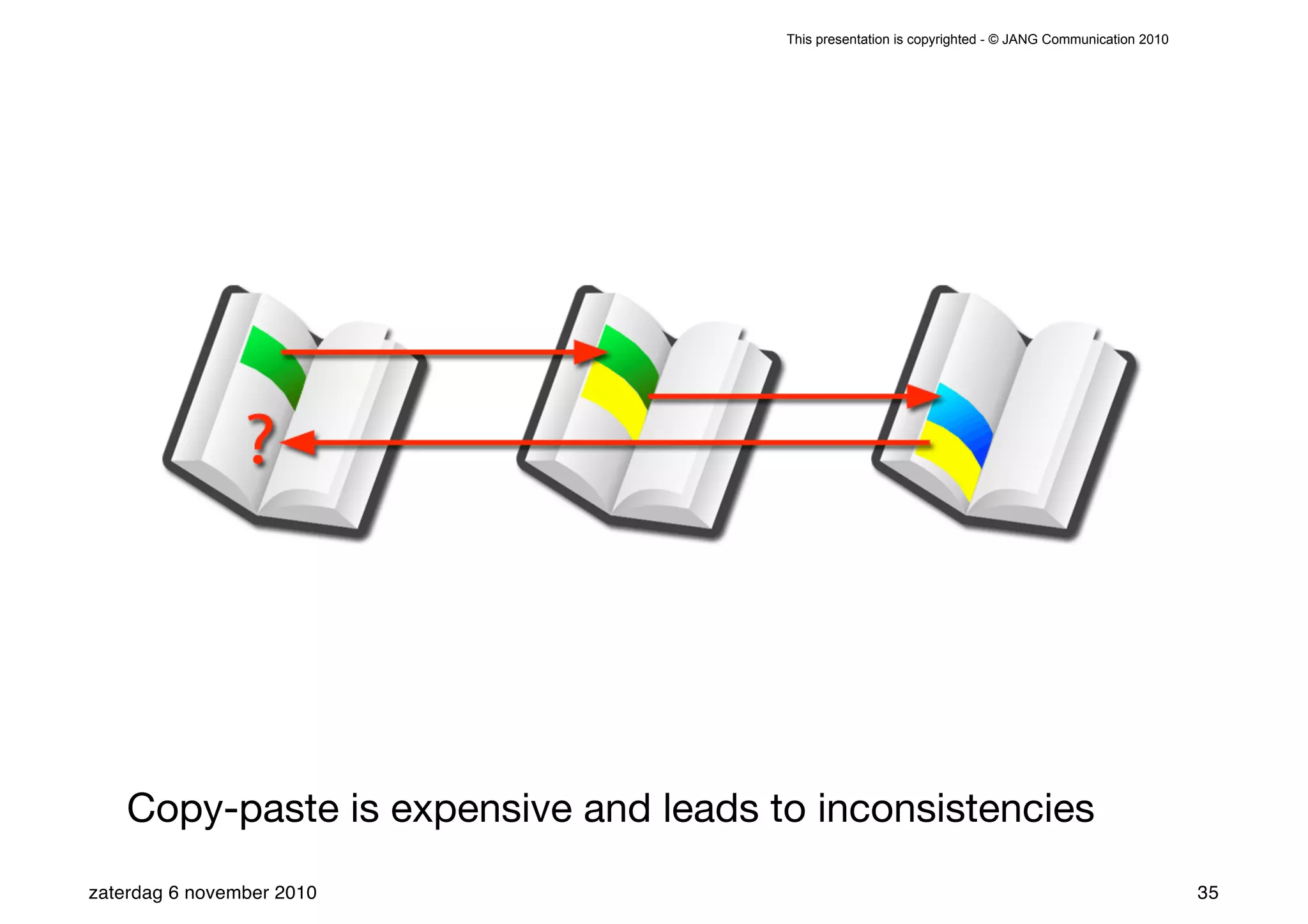

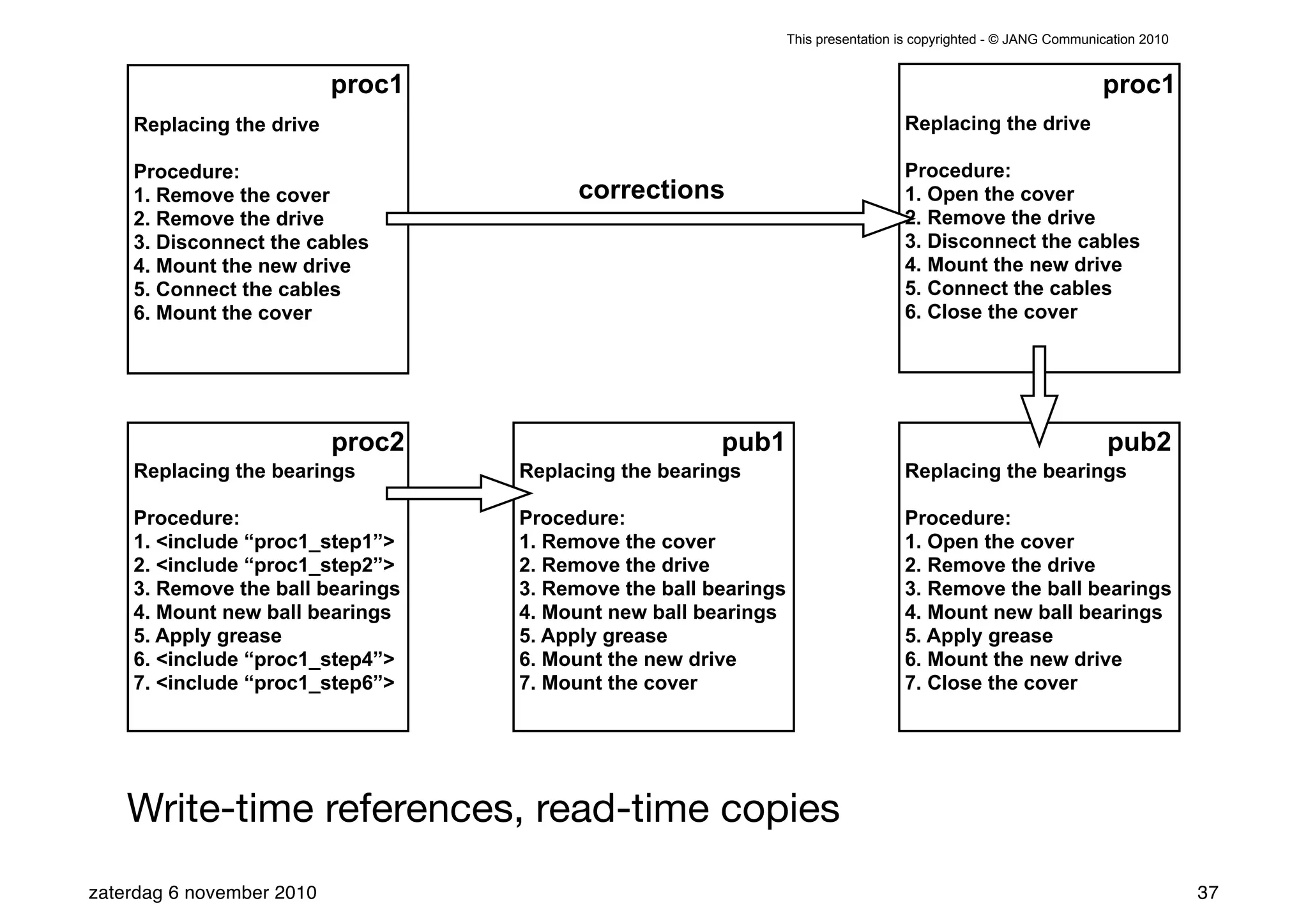

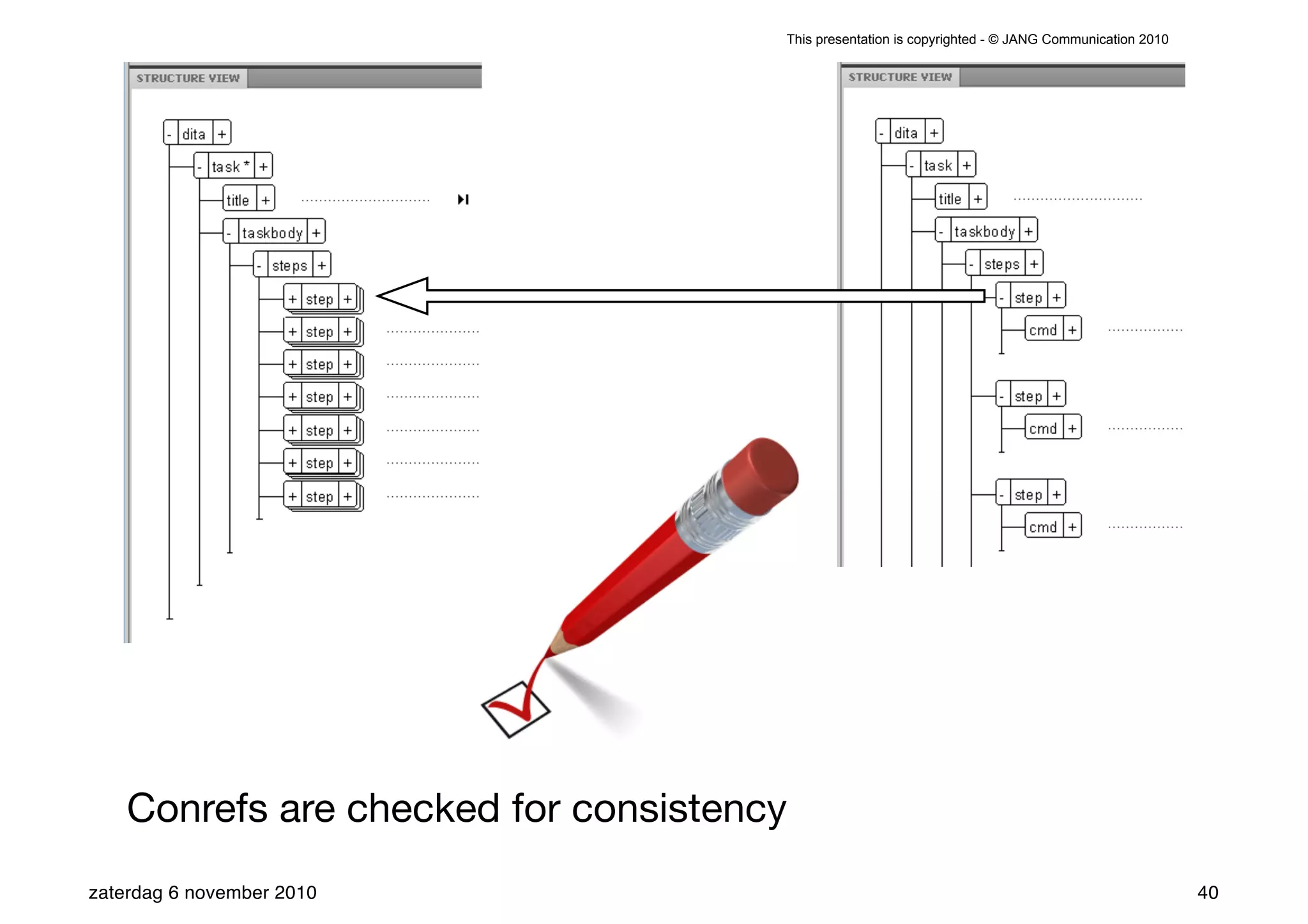






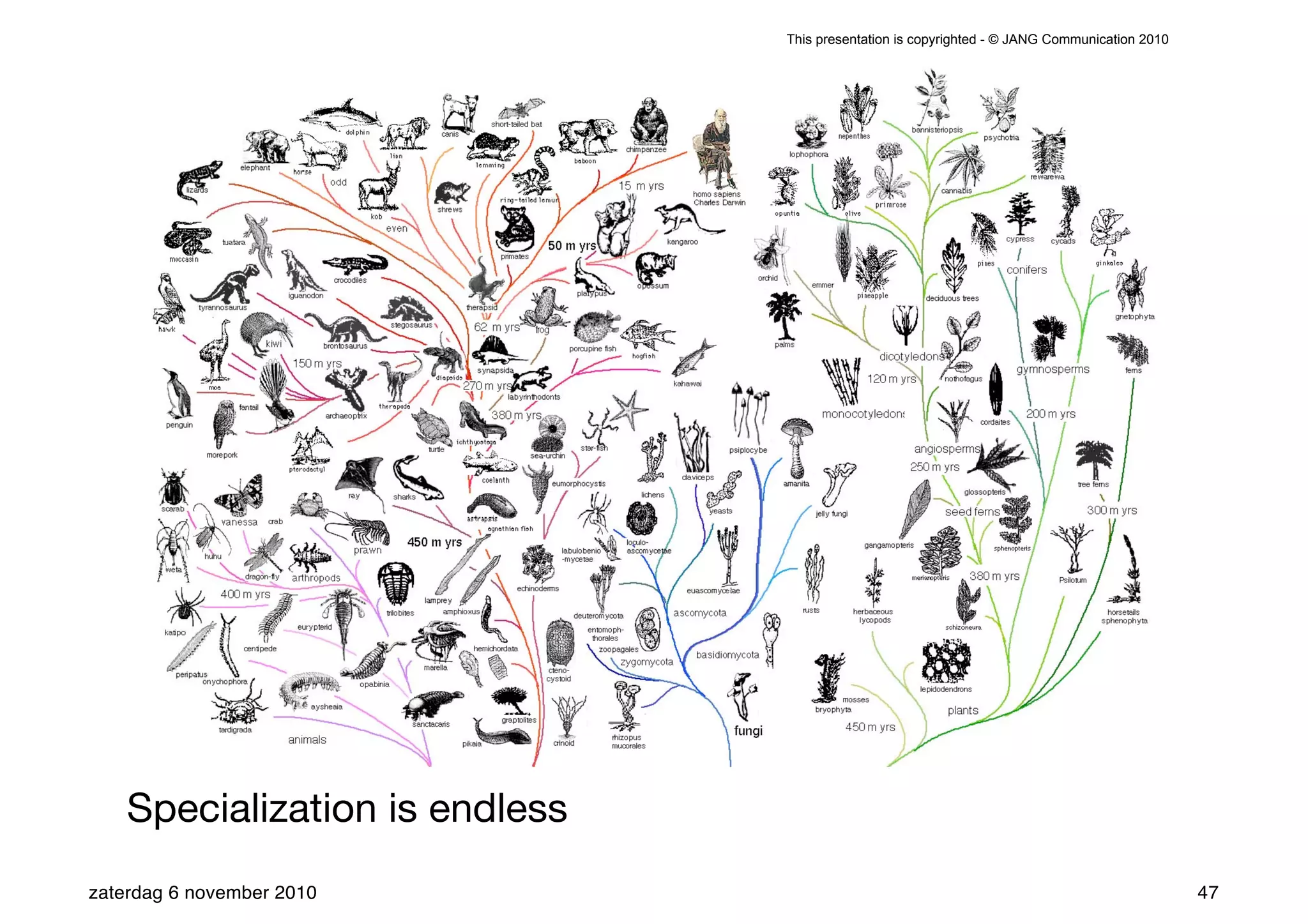



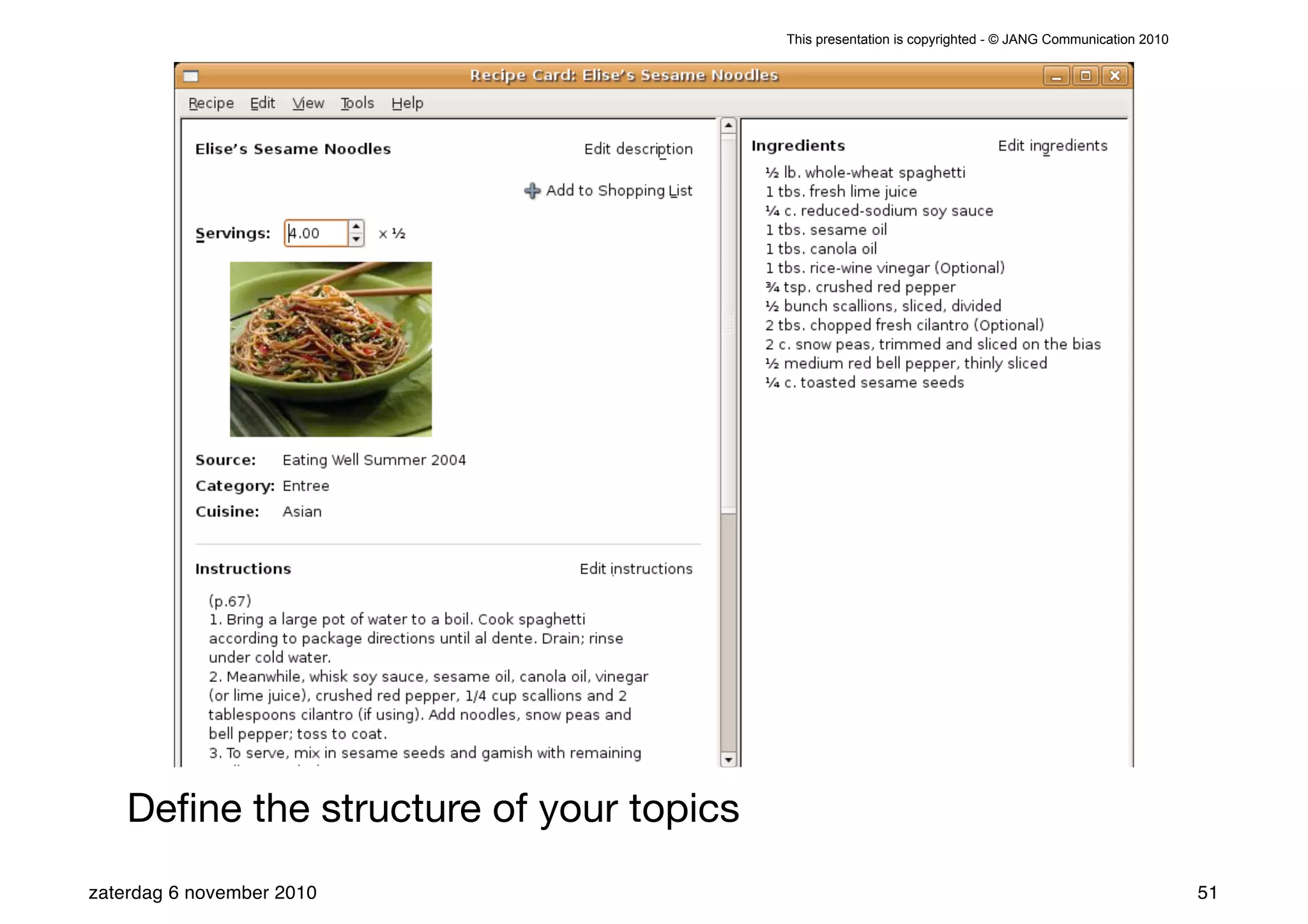
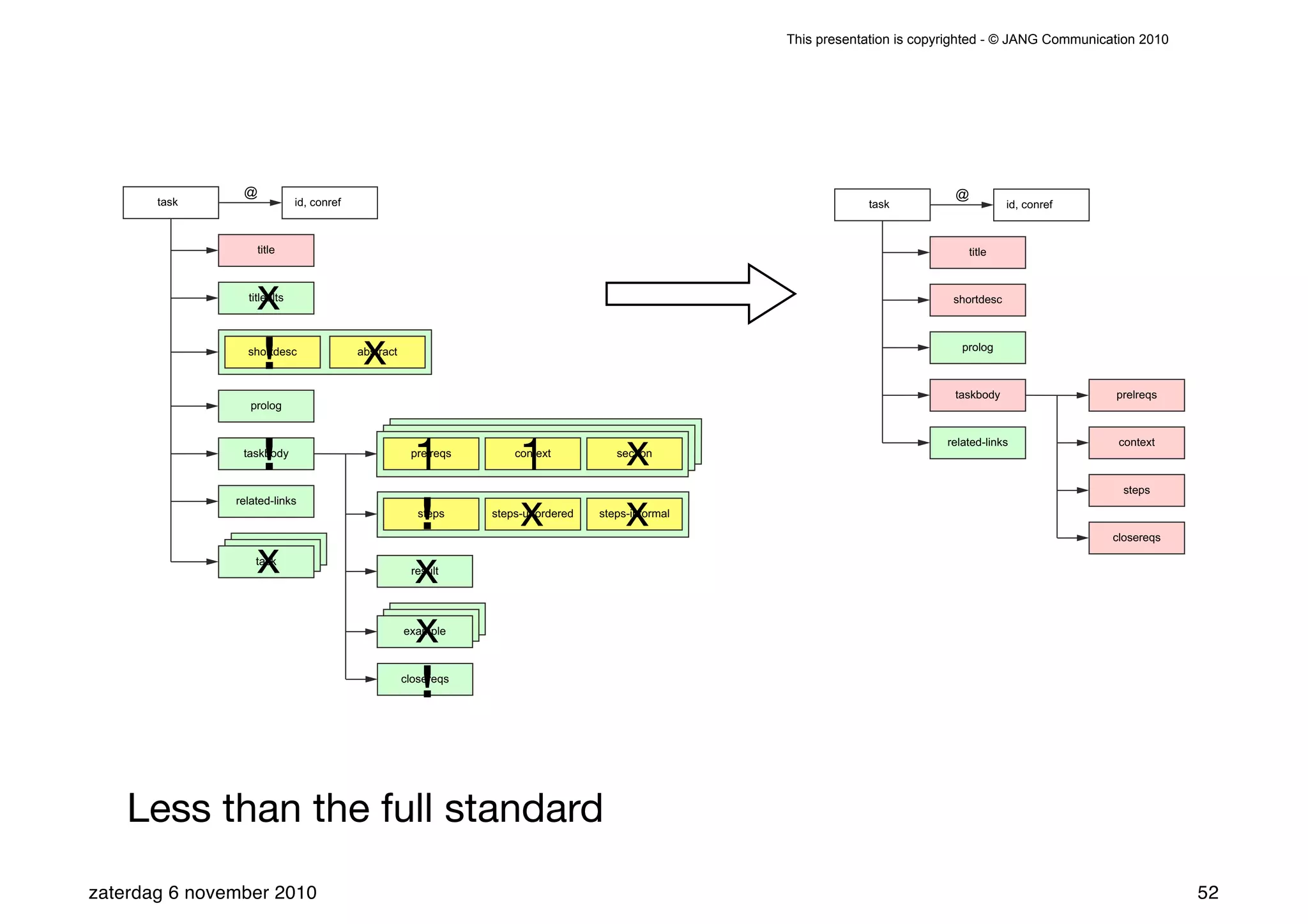





The presentation introduces the core concepts of DITA (Darwin Information Typing Architecture), focusing on its structural, minimalist, specialized, and constrained components. It emphasizes the importance of a clear structure, efficient content reuse through conrefs, and the necessity of defining constraints to avoid chaos in documentation. Key principles discussed include minimalism in content creation, specialization for user-specific needs, and the benefits of modular documentation using XML standards.















































