Downloaded 51 times












![Environment Layer
class EnvironmentStateActor(
environmentProxyActorRef: ActorRef, databaseInstance: Database
) extends Actor with ActorLogging {
import EnvironmentStateActor._
import EnvironmentStateFactory._
import EnvironmentStateLifecycleStrategy._
import EnvironmentStateRepository._
var environmentState: Option[EnvironmentState] = None
override def receive: Receive =
receiveLocalCommand orElse
receiveRemoteCommand
object EnvironmentStateLifecycleStrategy { ... }
object EnvironmentStateFactory { ... }
object EnvironmentStateRepository { ... }
}
16](https://image.slidesharecdn.com/developingareal-timeenginetstug-150821133429-lva1-app6891/75/Developing-a-Real-time-Engine-with-Akka-Cassandra-and-Spray-16-2048.jpg)
![Environment Layer
class EnvironmentActor(
environmentProxyActor: ActorRef, executorActorRef: ActorRef, bootActorRef: ActorRef
) extends Actor with ActorLogging {
import EnvironmentActor._
import EnvironmentLifecycleStrategy._
var environmentState: Option[EnvironmentState] = None
override def receive: Receive =
receiveEnvironmentState orElse
receiveFraudRequest
def forkedMaquetteContext(fraudRequest: FraudRequest): Option[MaquetteContext] = {
val forkedMaquetteContextOption = for {
actualEnvironmentState <- environmentState
actualBaseMaquetteContext <- actualEnvironmentState.maquetteContextMap.
get(fraudRequest.evaluationType)
actualForkMaquetteContext = actualBaseMaquetteContext.
copy(fraudRequest = fraudRequest)
} yield actualForkMaquetteContext
forkedMaquetteContextOption
}
}
17](https://image.slidesharecdn.com/developingareal-timeenginetstug-150821133429-lva1-app6891/75/Developing-a-Real-time-Engine-with-Akka-Cassandra-and-Spray-17-2048.jpg)






![Executor Layer
object QueryParser extends JavaTokenParsers {
def parseQuery(queryString: String): Try[Query] = {
parseAll(queryStatement, queryString) ...
}
object QueryGrammar {
lazy val queryStatement: Parser[Query] =
selectClause ~ fromClause ~ opt(whereClause) ~ ";" ^^ {
case selectComponent ~ fromComponent ~ whereComponent ~ ";" =>
Query(selectComponent, fromComponent, whereComponent.getOrElse(Where.Empty))
}
}
object SelectGrammar { ... }
object FromGrammar { ... }
object WhereGrammar { ... }
object StaticClauseGrammar { ... }
object DynamicClauseGrammar { ... }
object InterpolationTypeGrammar { ... }
object DataTypeGrammar { ... }
object LexicalGrammar { ... }
}
24
Note: An example of a Rule parser is not shown as it is a trade secret.](https://image.slidesharecdn.com/developingareal-timeenginetstug-150821133429-lva1-app6891/75/Developing-a-Real-time-Engine-with-Akka-Cassandra-and-Spray-24-2048.jpg)









![Akka Steams
• “Akka Streams is an implementation of Reactive Streams,
which is a standard for asynchronous stream processing
with non-blocking backpressure.”
34
implicit val system = ActorSystem("reactive-tweets")
implicit val materializer = ActorMaterializer()
val authors: Source[Author, Unit] =
tweets
.filter(_.hashtags.contains(akka))
.map(_.author)
authors.runWith(Sink.foreach(println))](https://image.slidesharecdn.com/developingareal-timeenginetstug-150821133429-lva1-app6891/75/Developing-a-Real-time-Engine-with-Akka-Cassandra-and-Spray-34-2048.jpg)









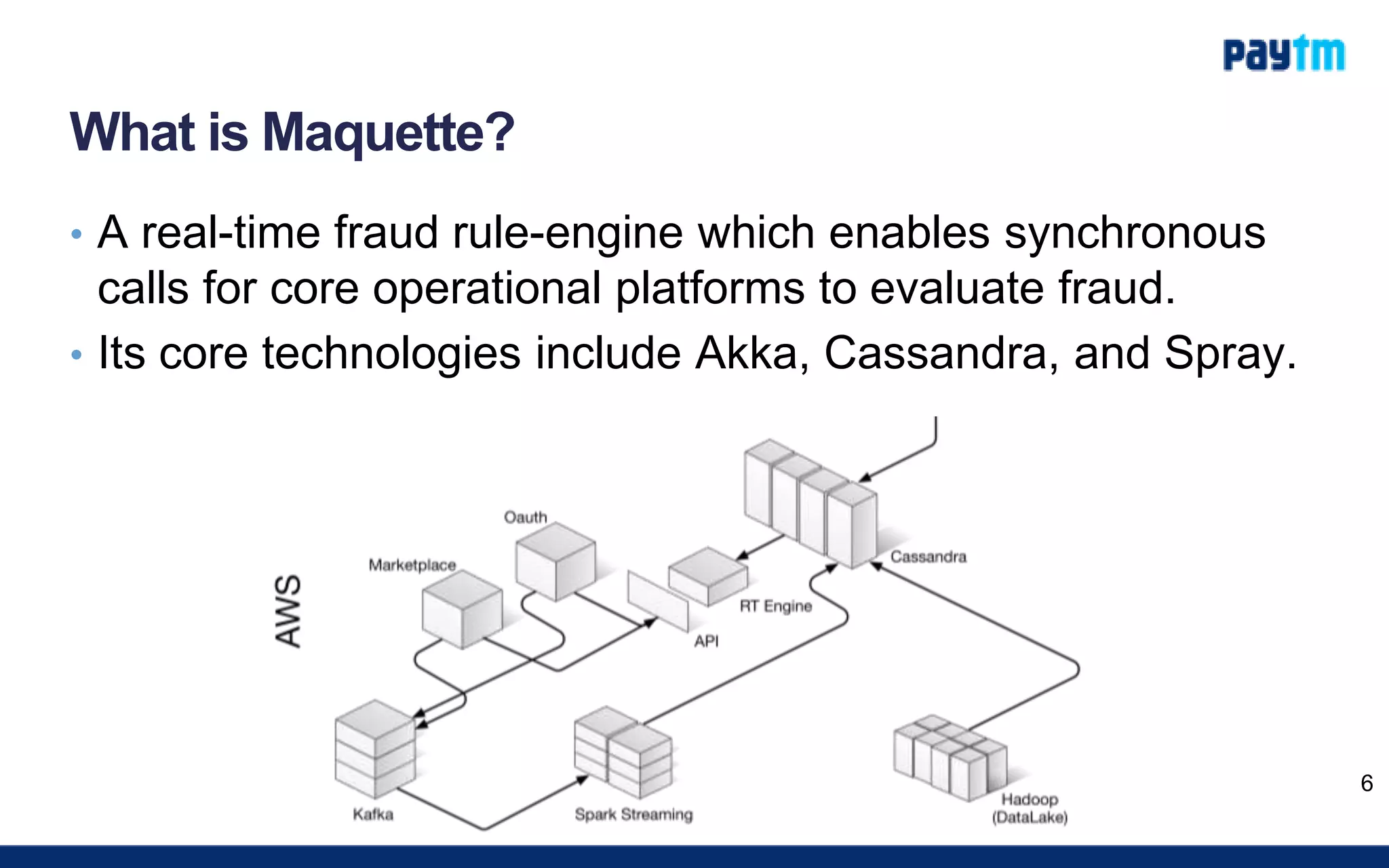
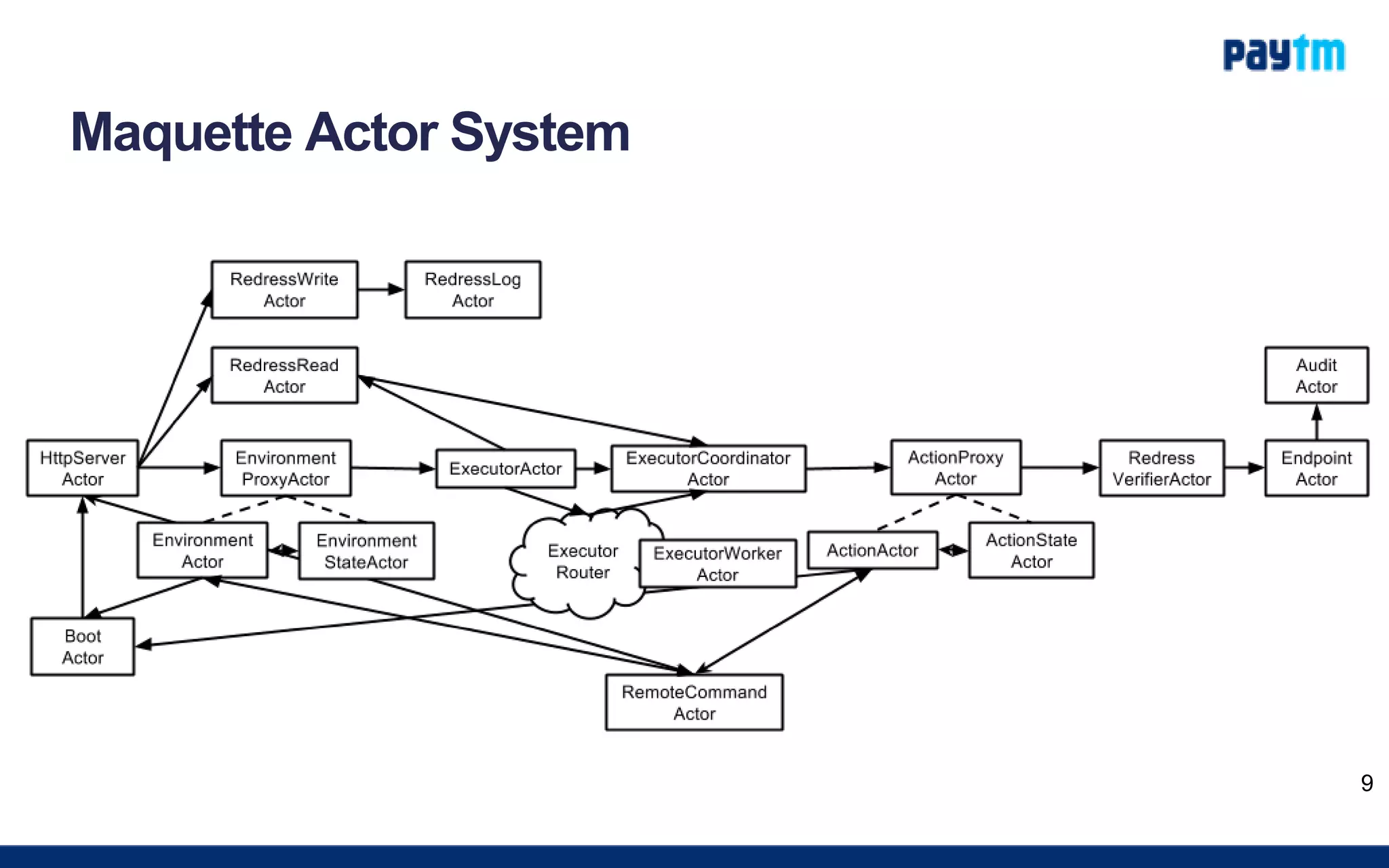
The document outlines the development of a real-time fraud rule engine named Maquette utilizing Akka, Cassandra, and Spray for building scalable and resilient applications. It provides details on the architecture, environment, and execution layers of the engine, emphasizing the importance of these technologies in managing high-performance tasks and handling complex data queries. Additionally, it includes performance metrics, usage tips, and resources for further learning about reactive programming and the technologies involved.























































































