

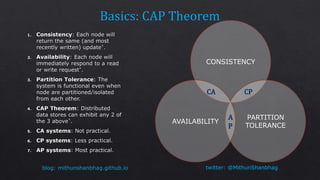




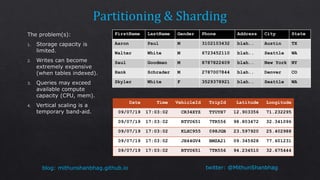
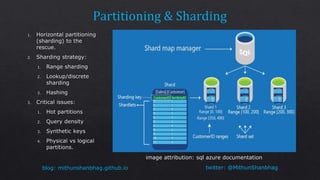
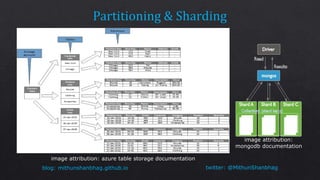


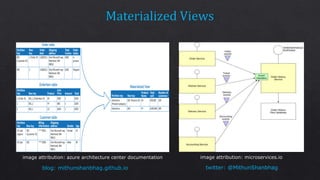

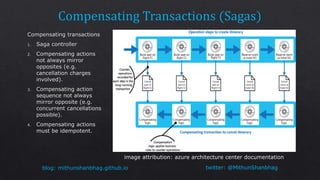
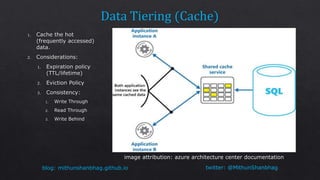
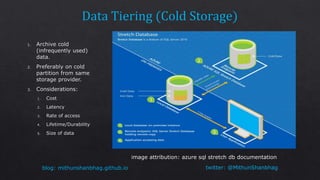


The document discusses consistency levels in distributed databases and the tradeoffs between consistency, availability, and partition tolerance. It explains that strong consistency guarantees like linearizability come at the cost of lower availability and partition tolerance, while eventual consistency provides the lowest latency at the cost of strong consistency guarantees. The document also provides examples of data stored using different databases and consistency levels.










![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





































