This document provides a case study analysis of the second-hand car market for Ford Fiestas in a specific postal code. It examines factors like age, mileage, and engine power that affect car prices. Descriptive statistics are used to analyze relationships between variables and identify their effects on price. Correlation and regression analyses are conducted to develop a model for determining how strongly certain factors influence overall car prices. The analysis provides average prices for Fiestas based on transmission type, color, and engine size to identify which attributes are correlated with higher or lower typical costs.



![Section 1
Introduction
We want to forecast the typical used car pricing for Ford fiesta in postal code B74JP gathered from
population. We summarize car data in an organized way by explaining the relationship between
different variables in a sample. To ascertain which elements, have the greatest influence on price
and which ones have no impact at all, we anticipate various correlations.
The Source of our data is https://heycar.co.uk/used-cars. After extracting relevant data from our
source to an excel file, the major limitation was of missing values and manipulation of those values
was crucial to accurately analyze data and interpret its output coherently. We are cleaning data
without changing the real context of the data by either adding or deleting values or removing
anomalies. In our dataset, we filter out blank or missing values to check the number of missing
values in our dataset. Then for this dataset we have deleted all the missing values as they were low
in number, and they were not making much of an impact on the meaning of the dataset. In this
dataset, we are adopting simple random sampling because it gives each person or member of a
group an equal and just chance of being chosen by randomly selecting a small portion of persons
or members from the total population. (“Random Sampling - Overview, Types, Importance,
Example”) Also, simple random sampling is required while finding the intervals in which the
average of the whole population lies. [2]https://corporatefinanceinstitute.com/resources/data-
science/random-sampling/
We are examining 5-year car data since it will not only provide us knowledge from that time period
about which cars are popular based on their performance but also help us to predict more
accurately. Consequently, it will be simpler for us to decide which to buy or sell.](https://image.slidesharecdn.com/descriptiveanalysis-221215211641-93b6a86d/75/Descriptive-Analysis-docx-4-2048.jpg)
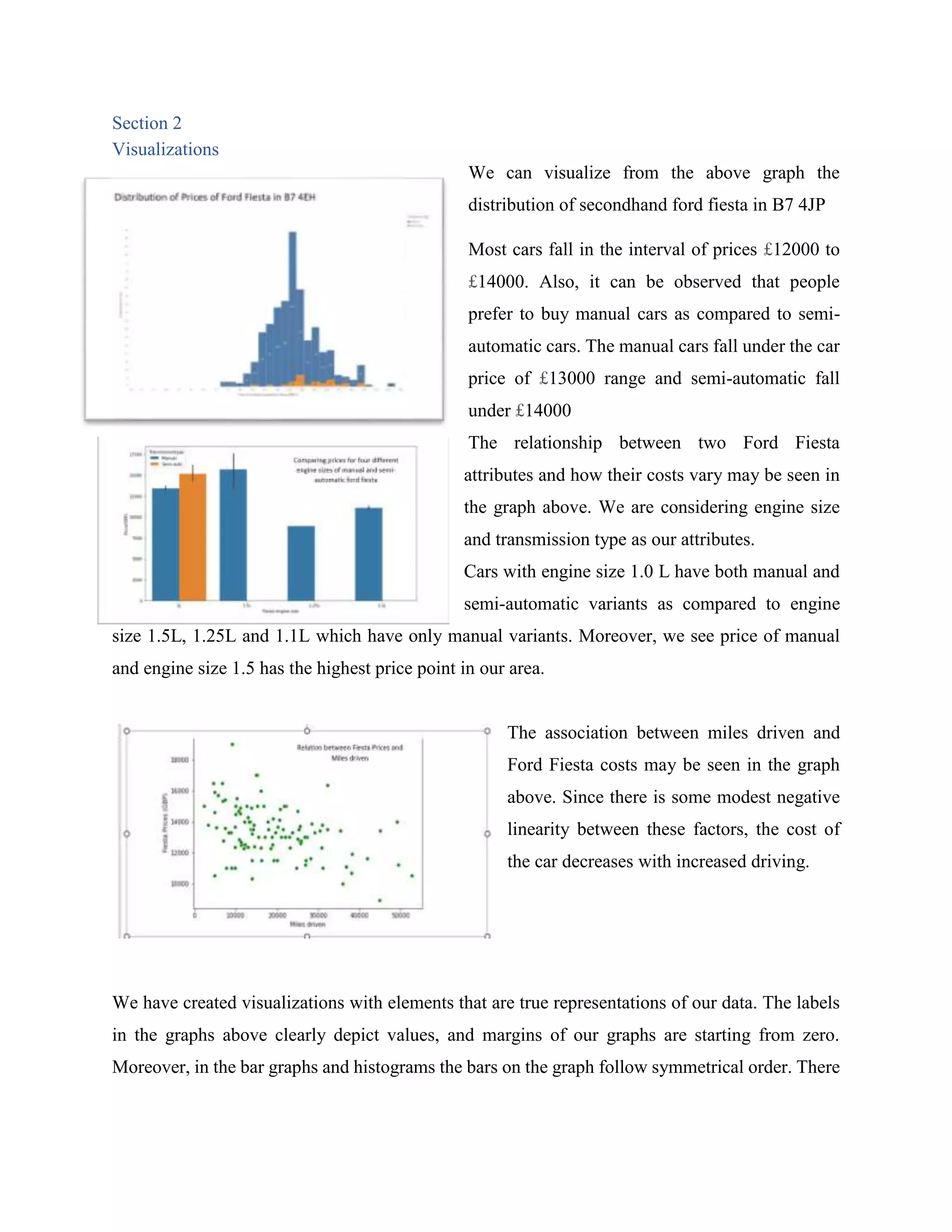




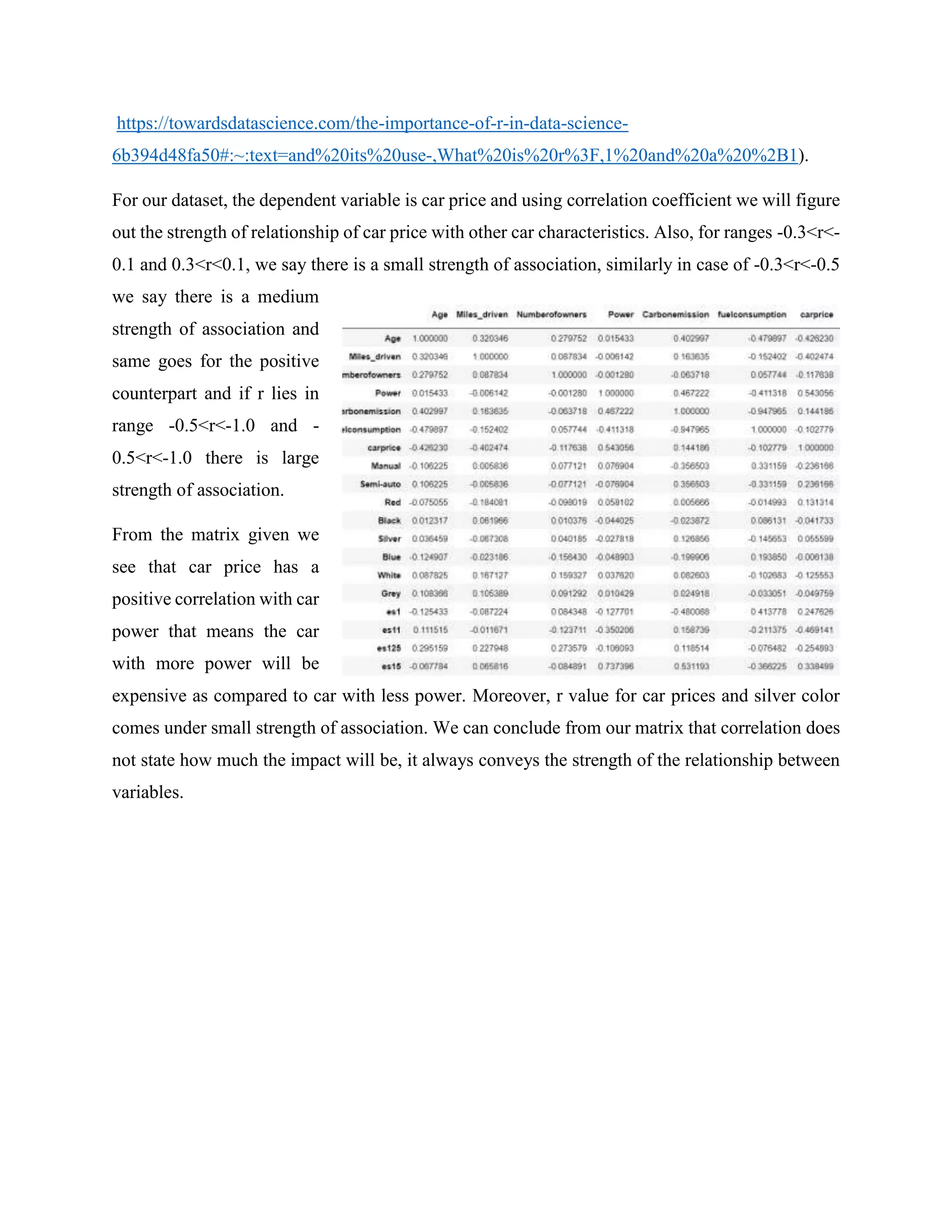
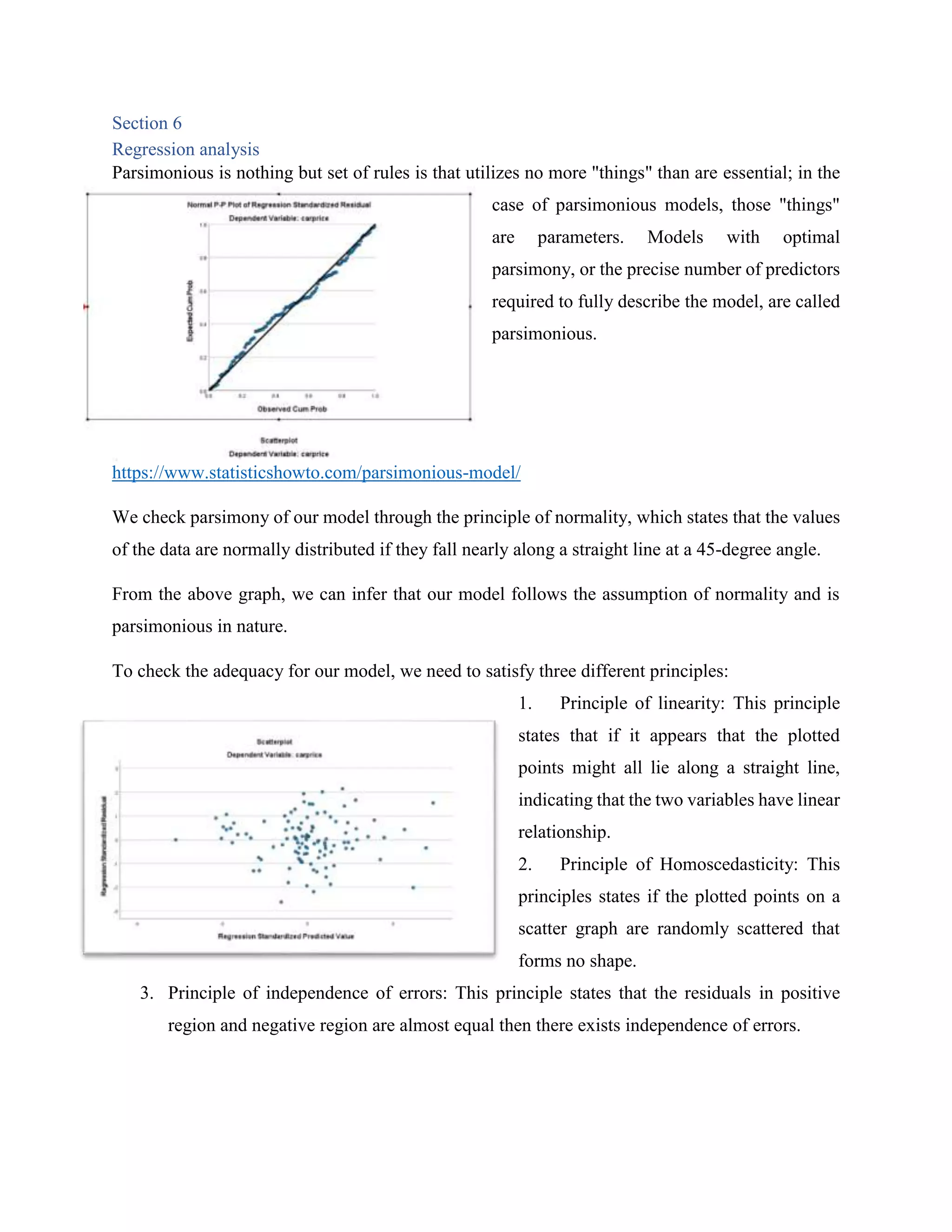































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)