Downloaded 15 times






















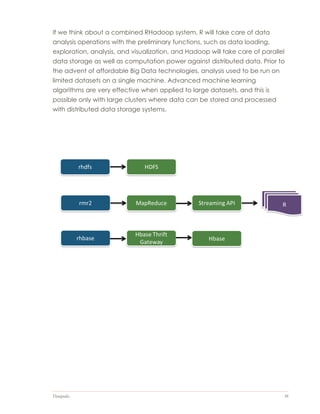
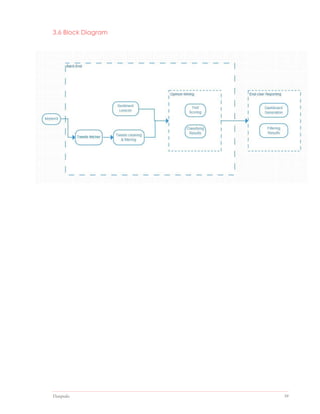
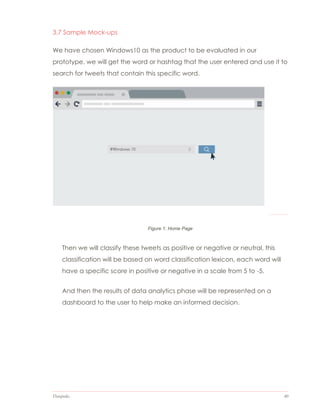
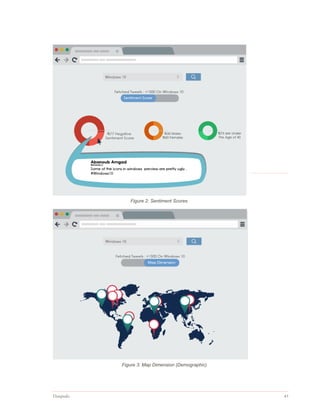















The document outlines the design and implementation of a web application aimed at simplifying the product purchasing decision-making process through the analysis of big data from product reviews and social media. It discusses the project's justification, scope, methodologies, and the technologies utilized, including R, Apache Hadoop, and PHP for data analytics and presentation. The report emphasizes the need for an integrated tool to streamline information collection and enhance user experience in choosing products.












































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)












![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)









