SET dynamodb.throughput.read.percent=0.8;
!
CREATE EXTERNALTABLE IF NOT EXISTS users (
id string,
seg string,
created bigint
)
stored as rcfile
location 's3://path/to/my/user/table';
!
CREATE EXTERNAL TABLE if not exists
users_from_dynamodb (
id string,
seg string,
created bigint)
STORED BY
'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES (
"hive.jdbc.update.on.duplicate" = "true",
"dynamodb.table.name" = "our_special_user_table_name",
"dynamodb.column.mapping" = "id:id,seg:seg,created:created");
!
INSERT OVERWRITE TABLE users SELECT * FROM users_from_dynamodb;
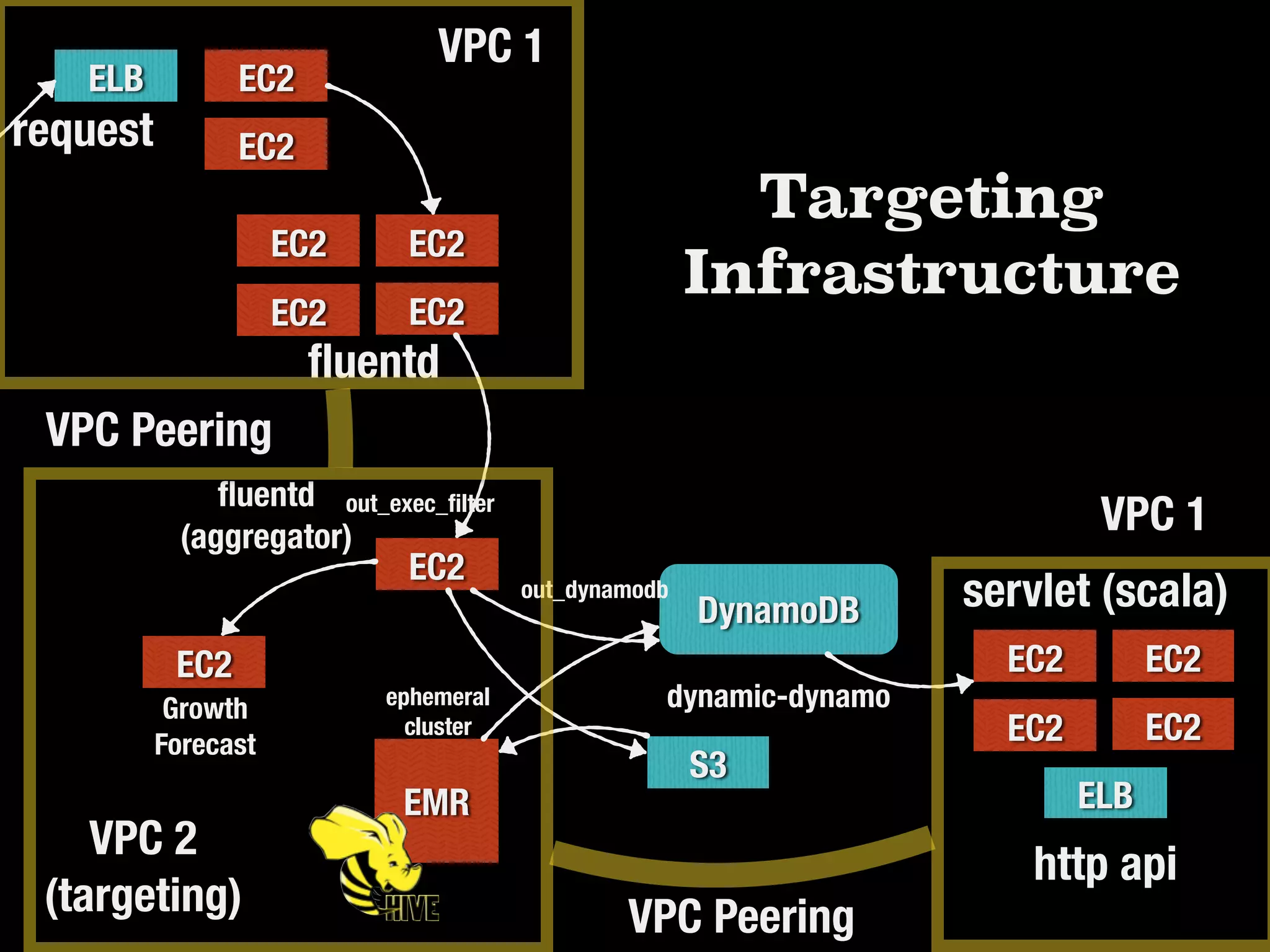
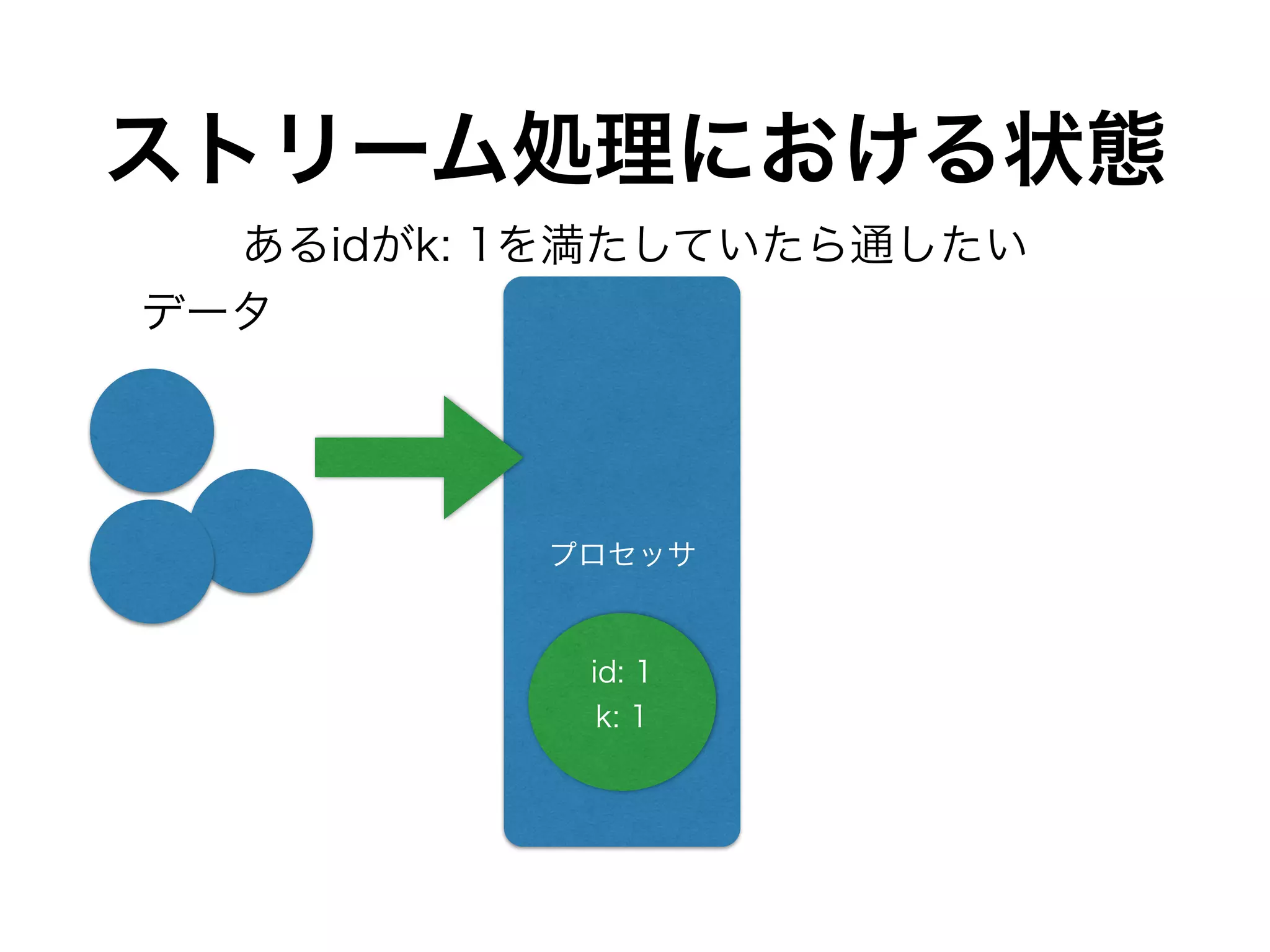
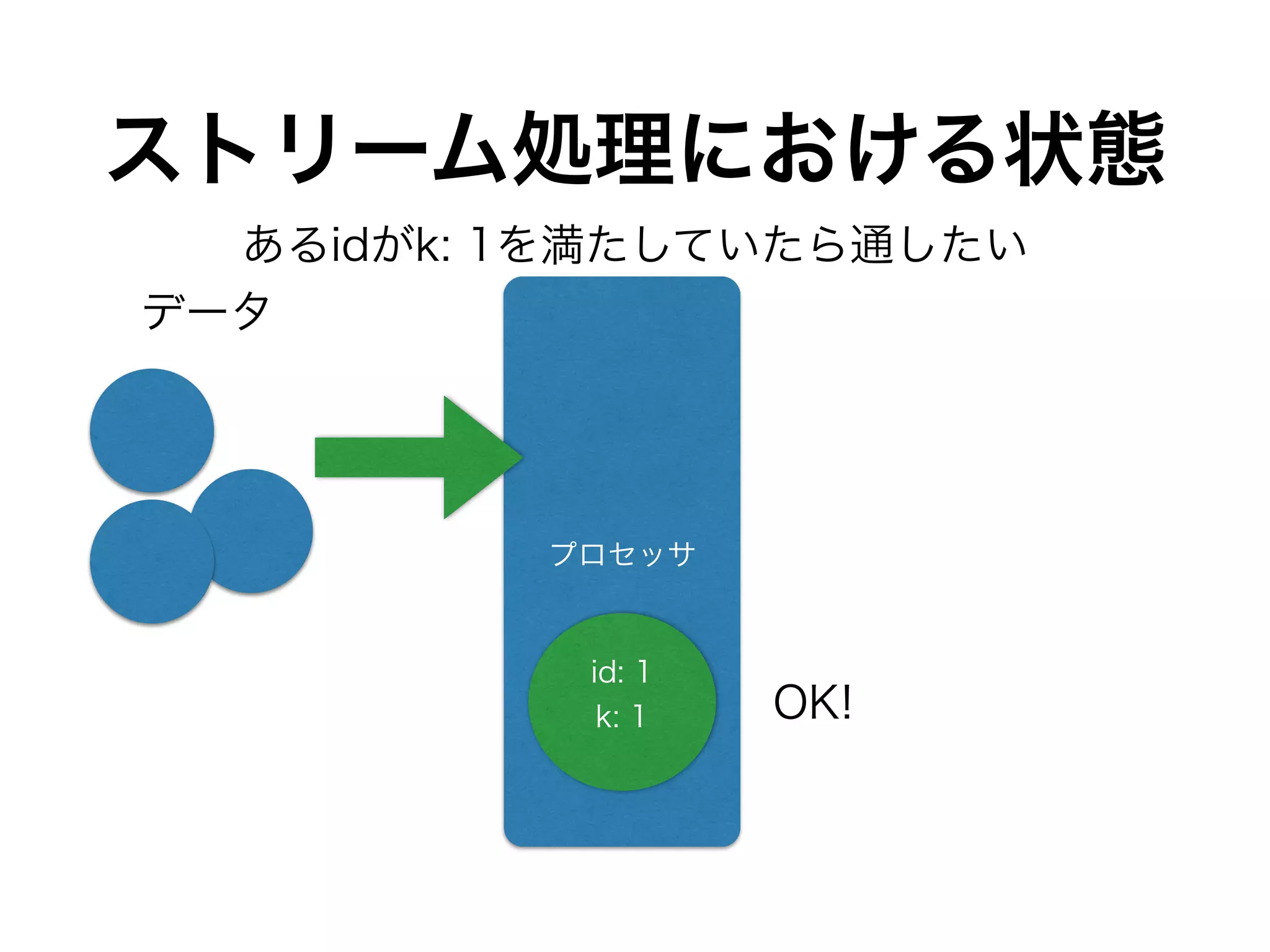
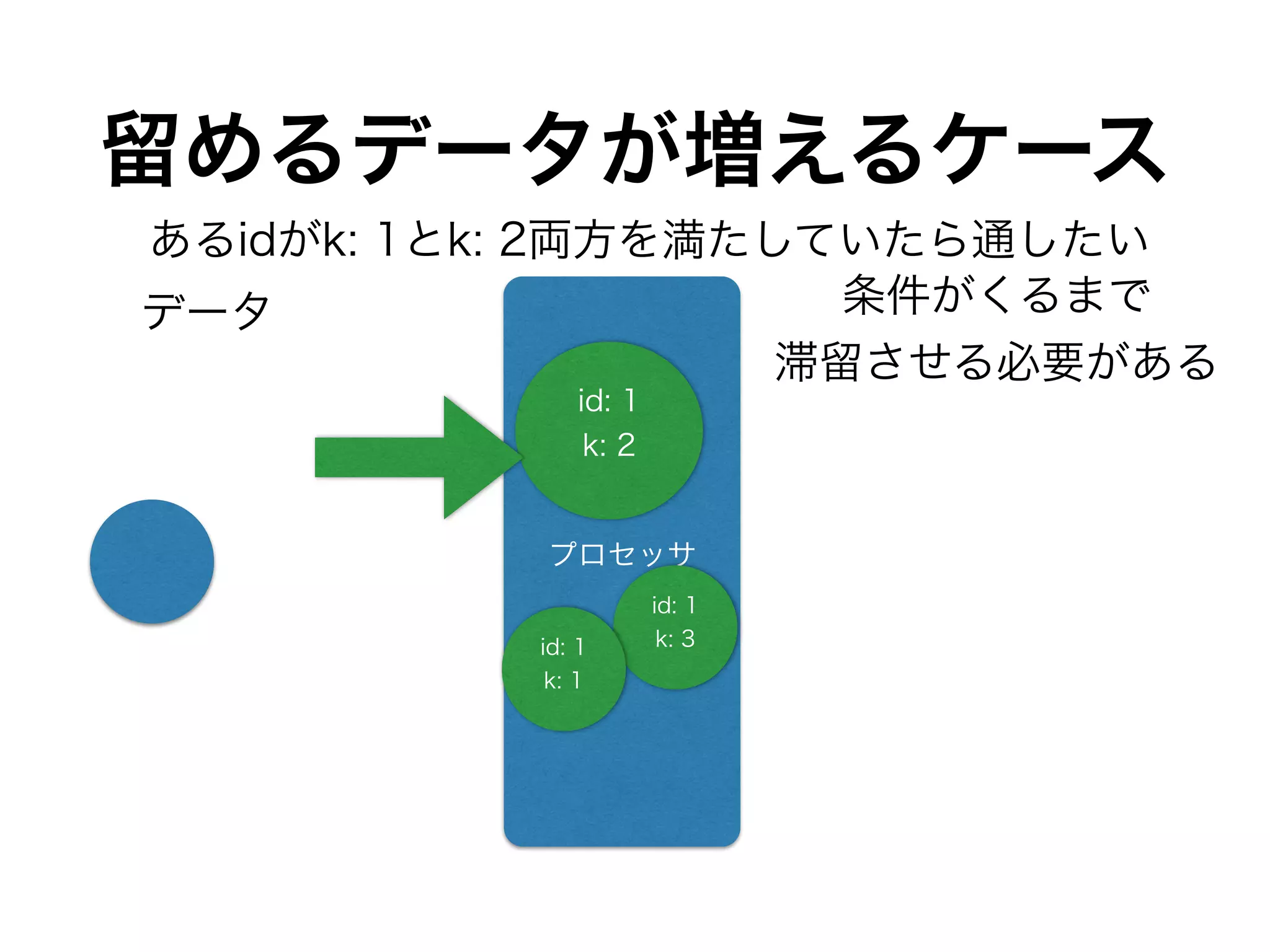
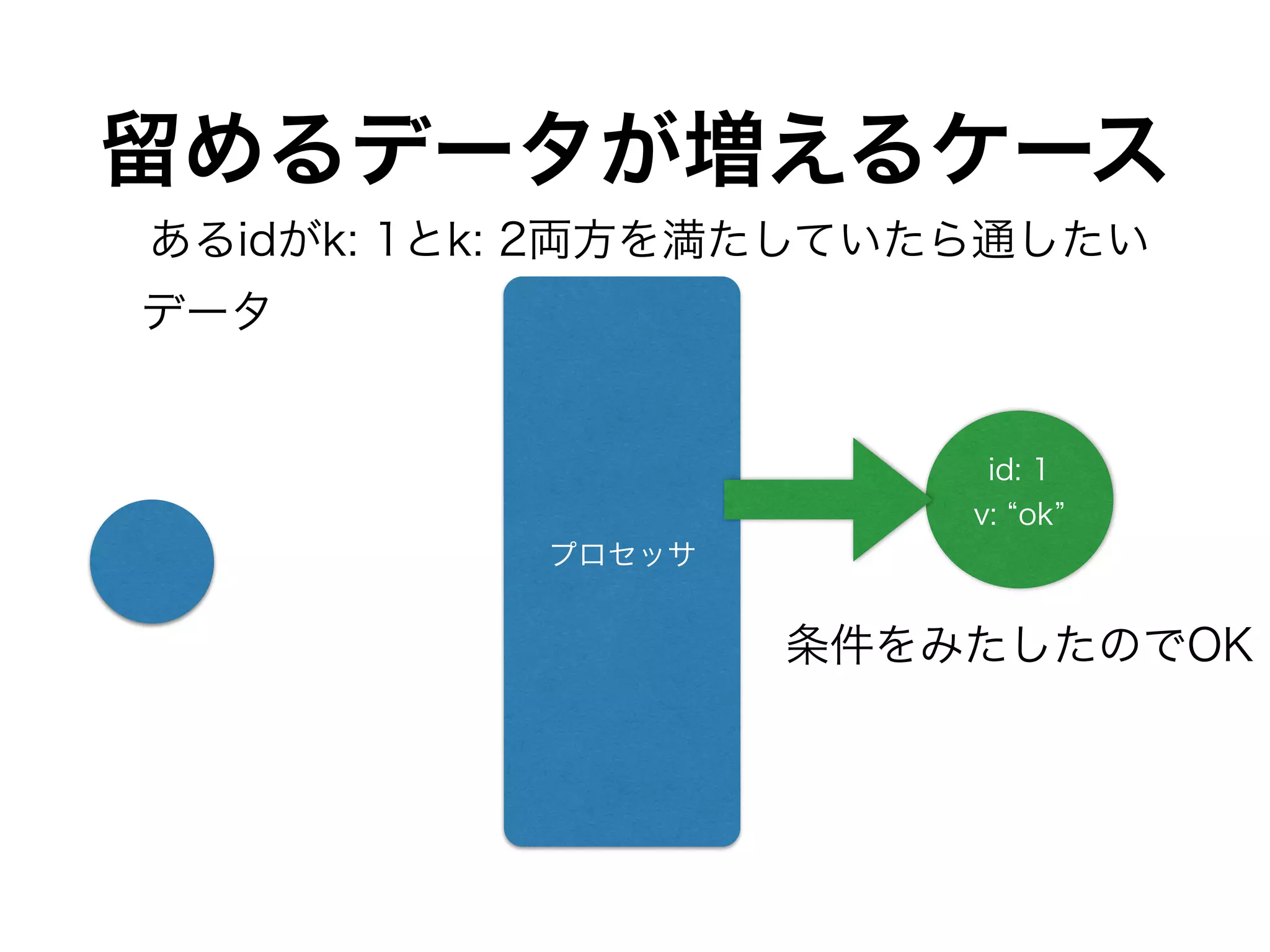
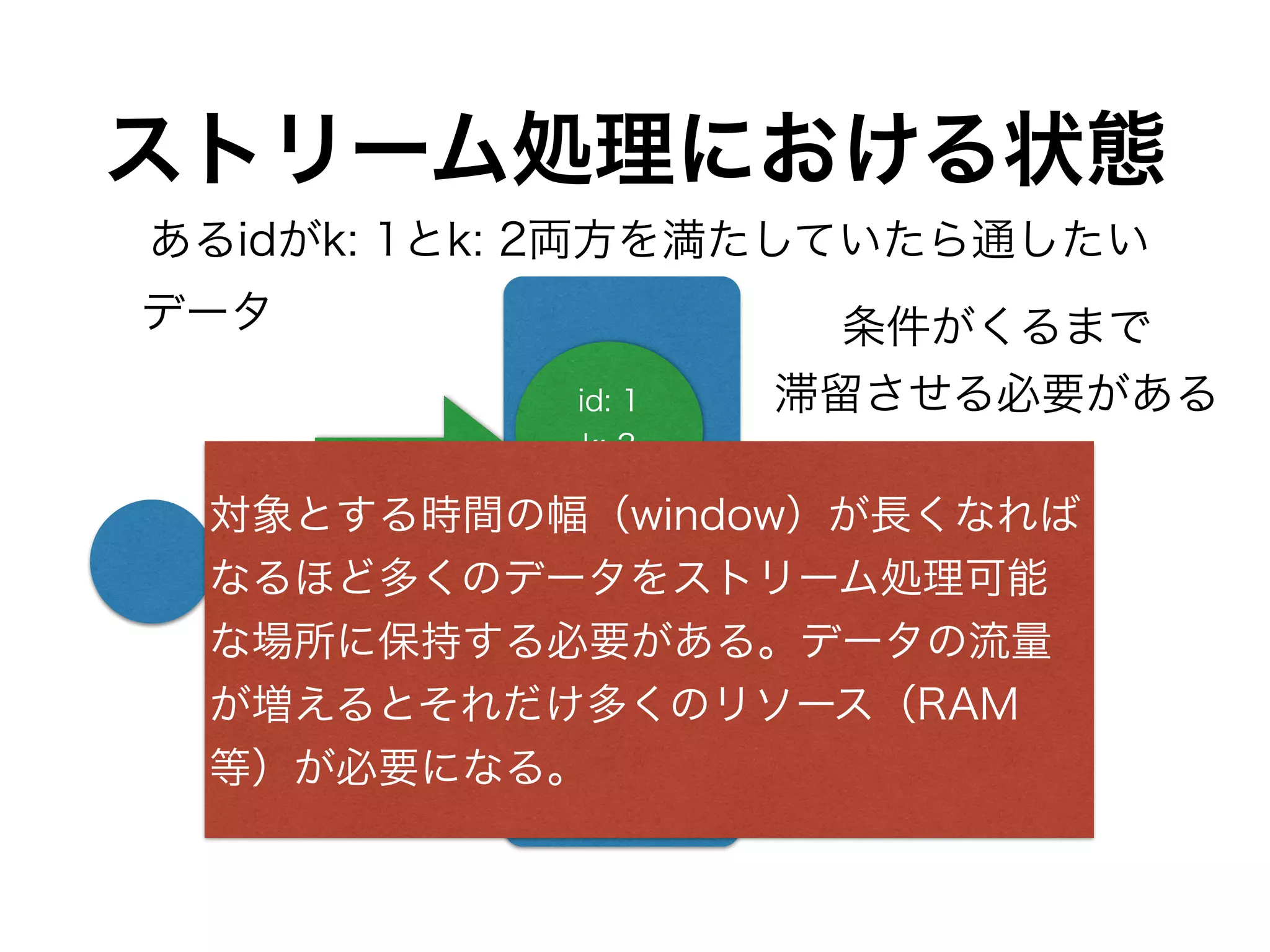
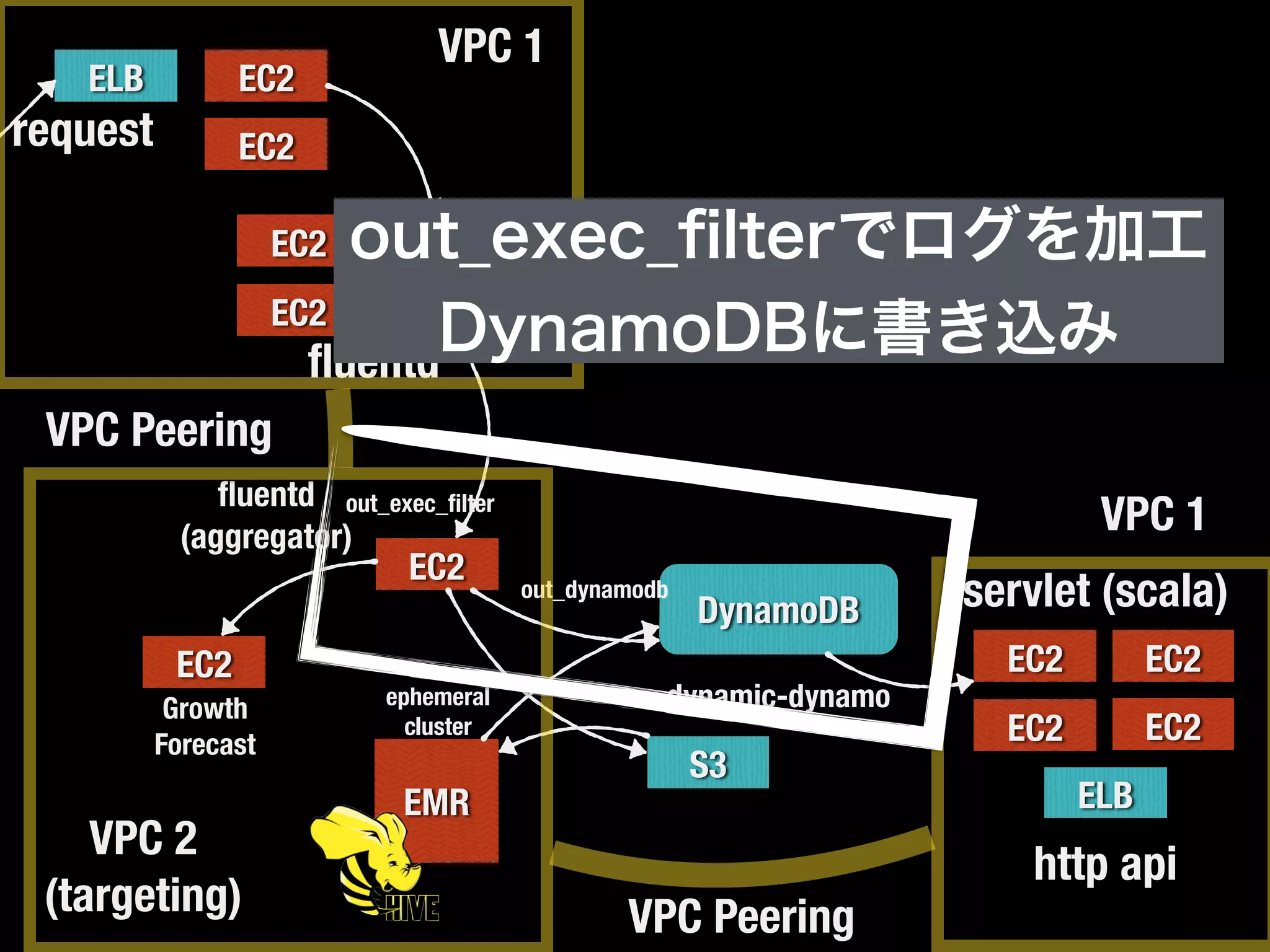
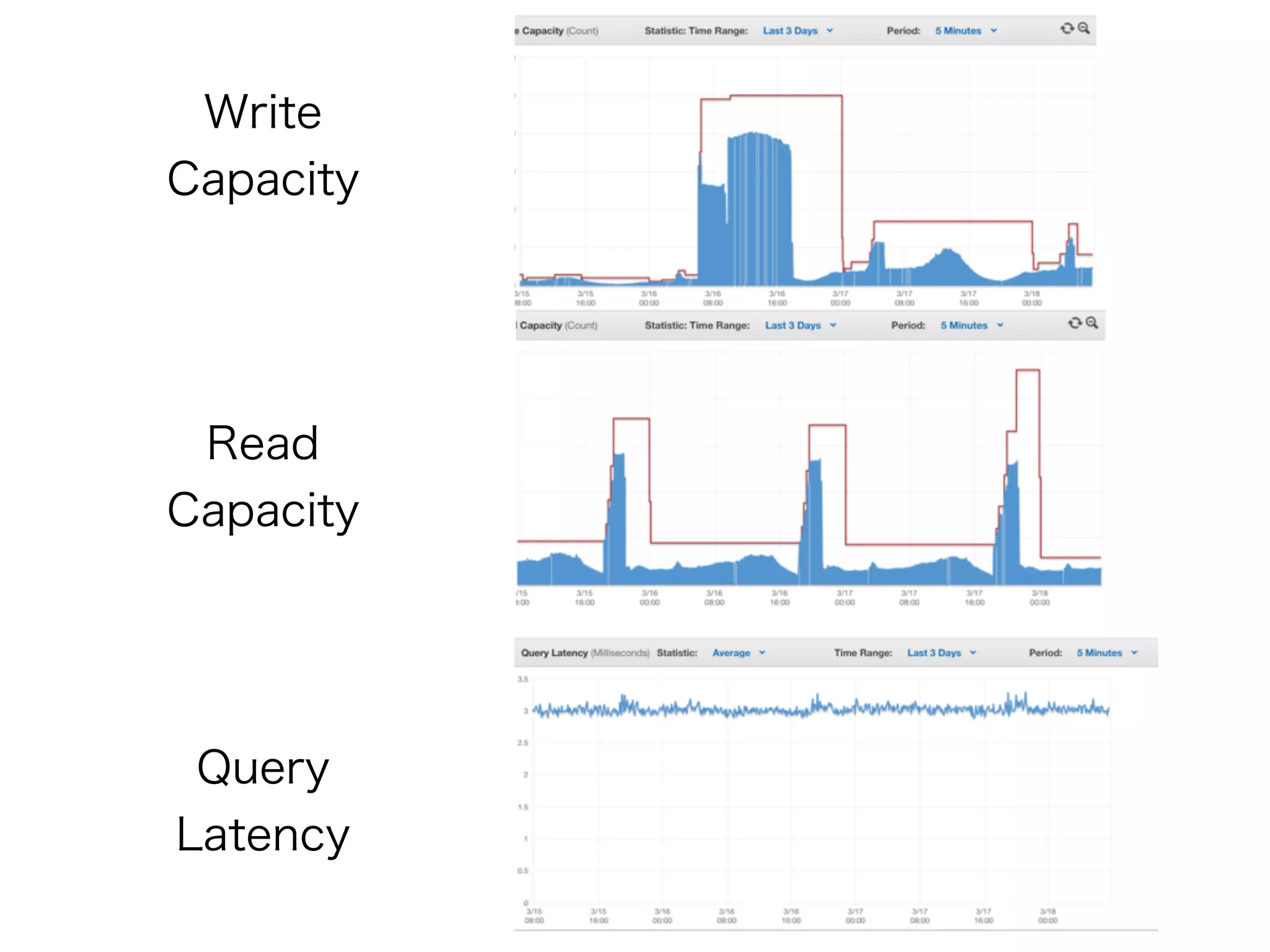
DynamoDBのthroughputをどれくらい使うか
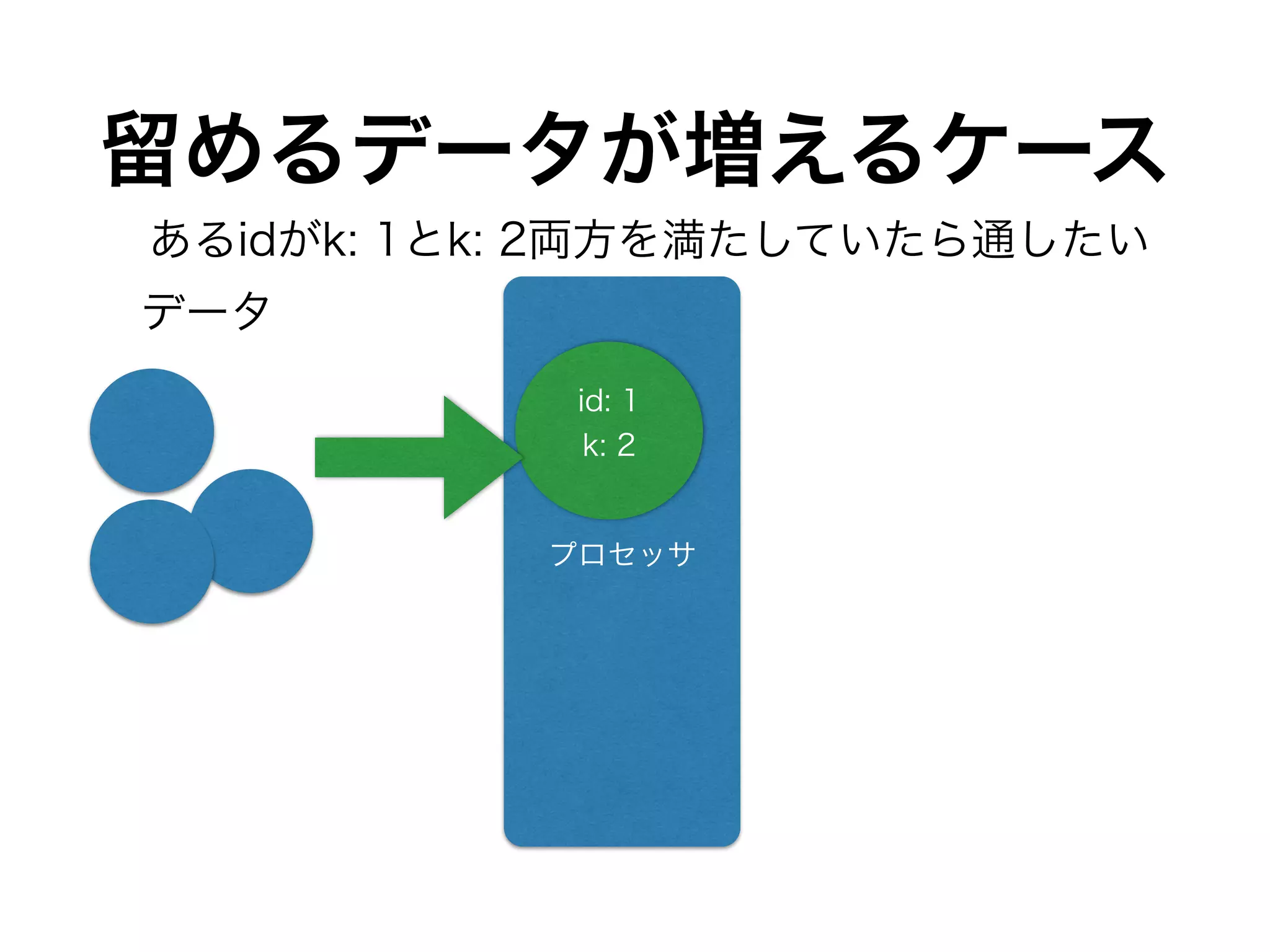
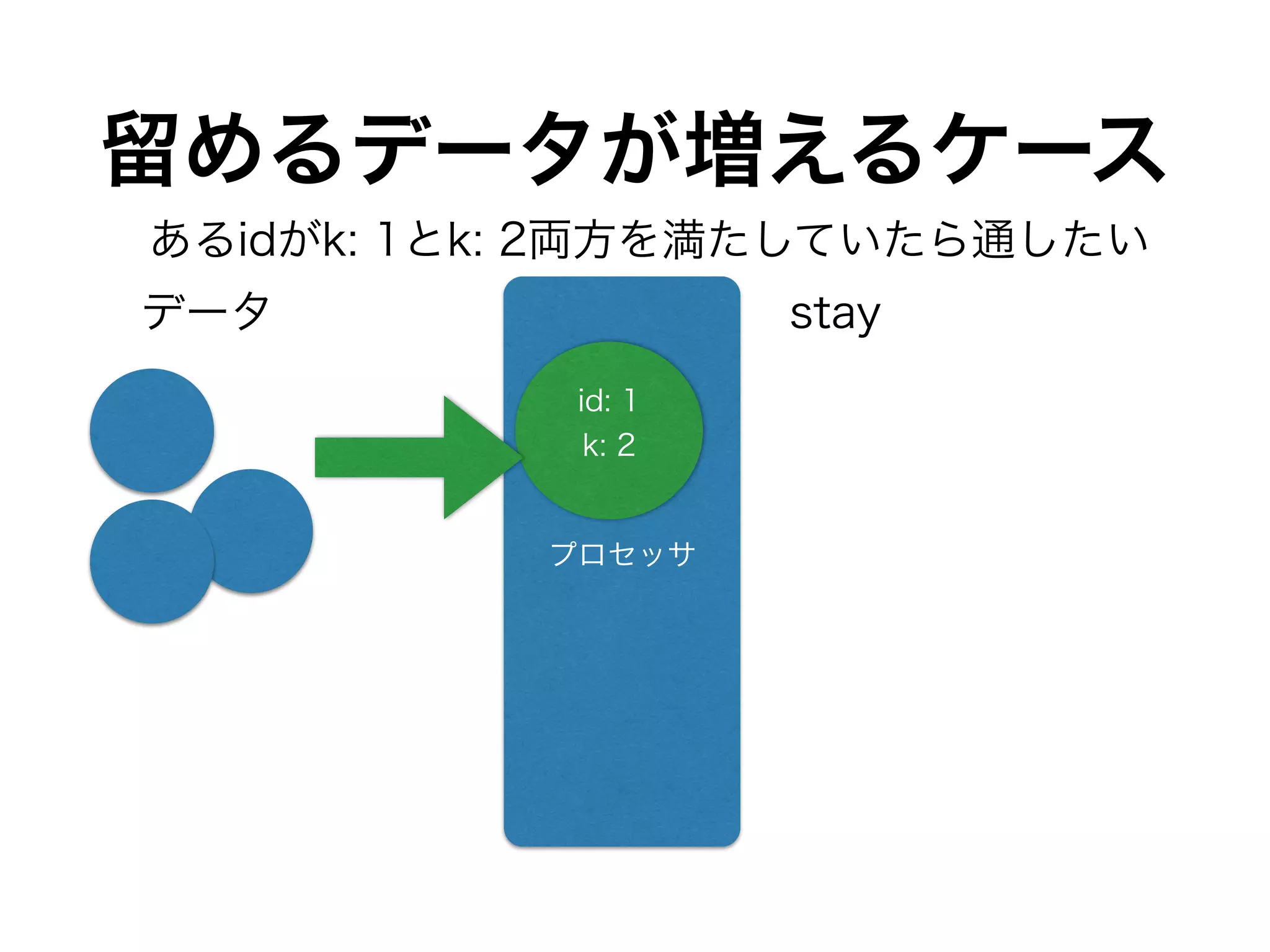
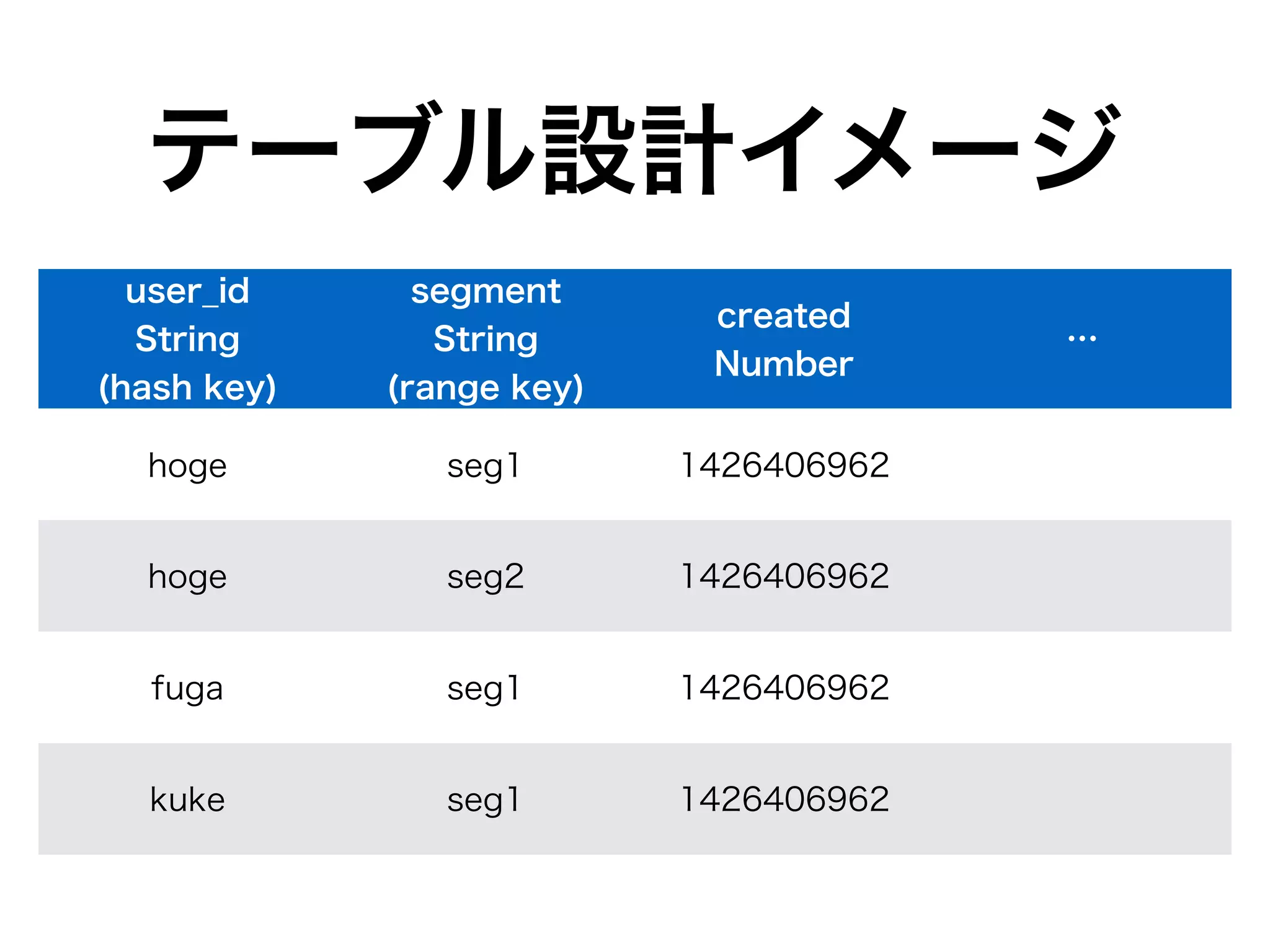
DynamoDBカラムとHiveテーブルの
カラム対応関係
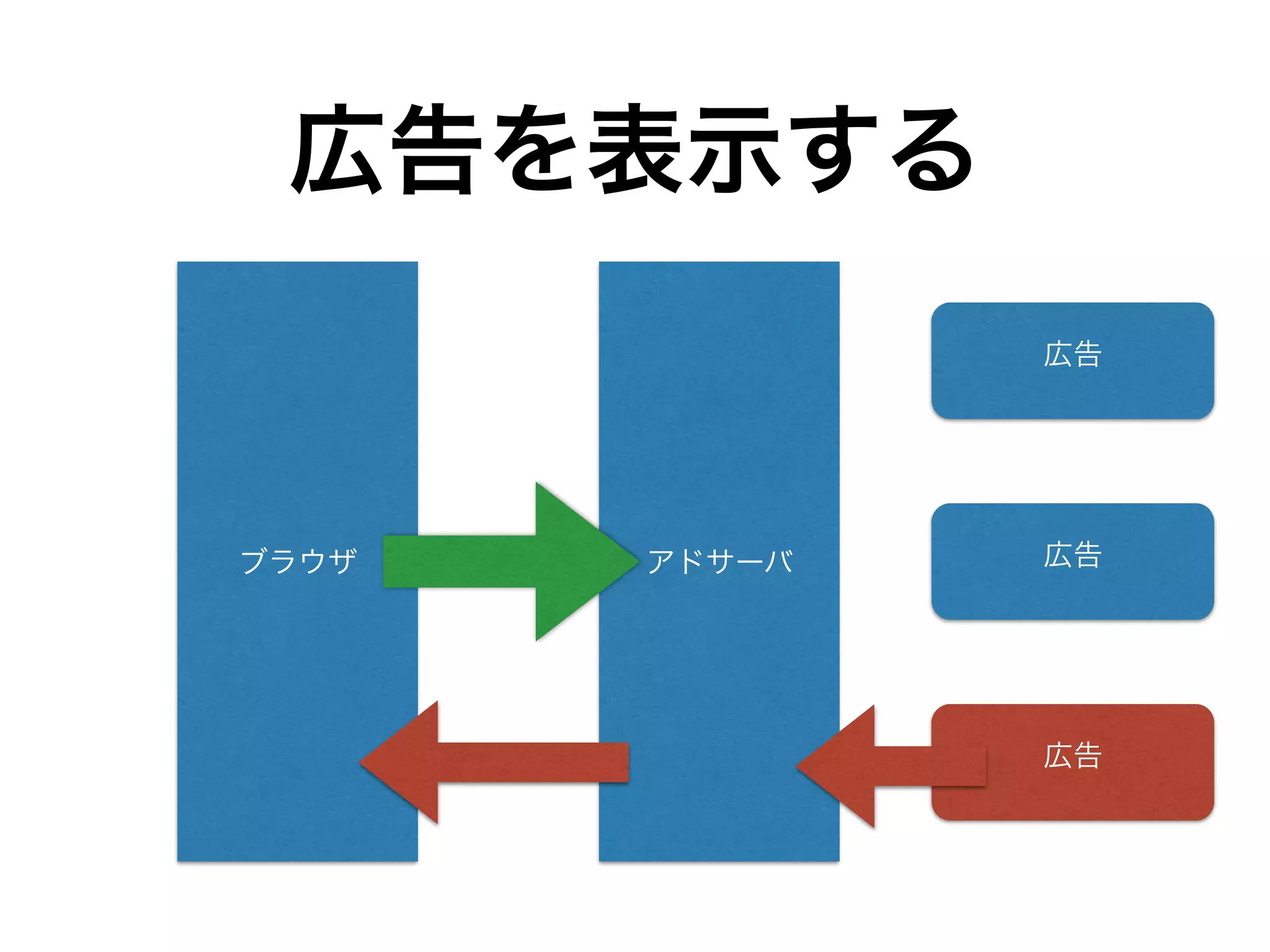
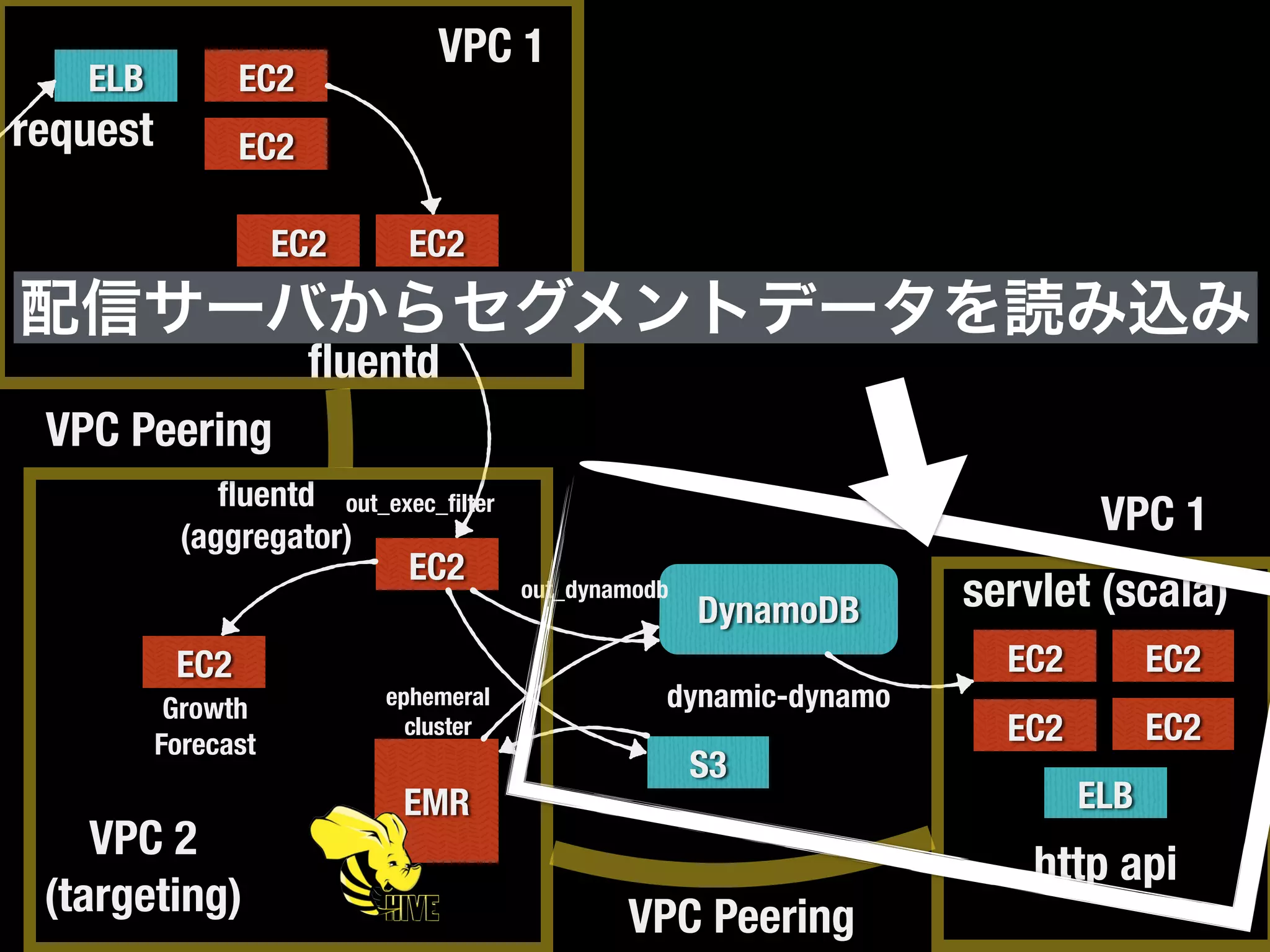
DynamoDBから全データを
抽出してs3に書き込み






































































































![[AWSマイスターシリーズ] Amazon DynamoDB](https://cdn.slidesharecdn.com/ss_thumbnails/20131002aws-meister-regenerate-dynamodb-public-131004025730-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[20140625]wwdc2014 feedback](https://cdn.slidesharecdn.com/ss_thumbnails/20140625wwdc2014feedback-140625023809-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[20130624]最近の開発環境について話してみる sakata](https://cdn.slidesharecdn.com/ss_thumbnails/20130624sakata-130624201516-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











