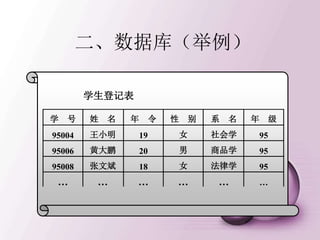
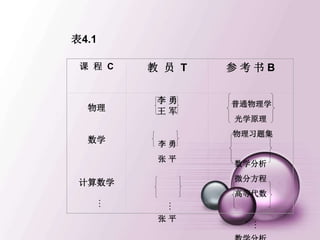
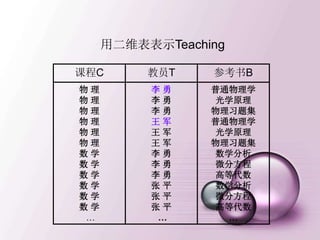
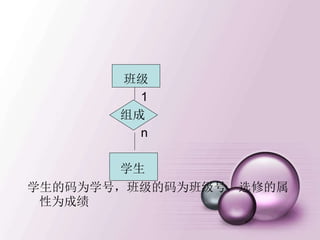
引入记号
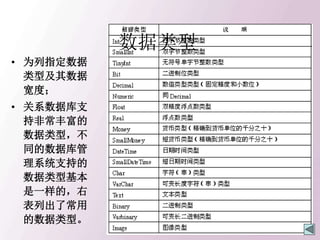
• 关系模式R (A1,A2,…,An),t∈R表示R的一个
元组t。t[Ai]表示属性元组t 中相应于属性Ai的分量
• 若A={Ai1,Ai2,…,Aik},其中Ai1,Ai2, …,Aik是A1
,A2,…,An的一部分A称作属性列或域列。
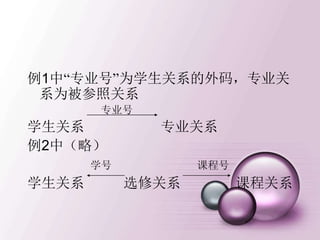
• 元组的连接
• 给定关系R(X,Z), 定义当t[X]=x时,x在R中的象集
为 表示R中属性组X上值
为x的诸元组在Z上分量的集合。
, ,
r s r s
t R t S t t
{ [ ] , [ ] }
x
Z t Z t R t X x
[例5.*] 使用列别名改变查询结果的列标题
SELECT SnameNAME,'Year of Birth: ’ BIRTH,
2000-Sage BIRTHDAY,ISLOWER(Sdept) DEPARTMENT
FROM Student;
输出结果:
NAME BIRTH BIRTHDAY DEPARTMENT
------- ---------------- ------------- ------------------
李勇 Year of Birth: 1976 cs
刘晨 Year of Birth: 1977 is
王名 Year of Birth: 1978 ma
张立 Year of Birth: 1977 is
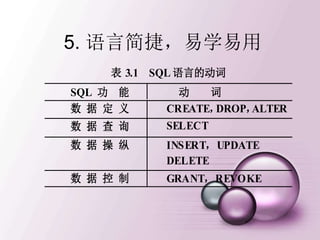
2.查询满足条件的元组
表 3.3 常用的查询条件
查询 条 件 谓 词
比 较
=,>,<,>=,<=,!=,<>,!>,!<;
NOT + 上述比较运算符
确定范围 BETWEEN AND,NOT BETWEEN AND
确定集合 IN,NOT IN
字符匹配 LIKE,NOT LIKE
空 值 IS NULL,IS NOT NULL
多重条件 AND,OR
WHERE子句常用的查询条件
208.
(1) 比较大小
在WHERE子句的<比较条件>中使用比较运算符
– =,>,<,>=,<=,!=或 <>,!>,!<,
– 逻辑运算符NOT + 比较运算符
[例8] 查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20; 或
SELECT Sname,Sage
FROM Student
WHERE NOT Sage >= 20;
(2) 确定范围
• 使用谓词BETWEEN … (下限) AND …(上限)
NOT BETWEEN … AND …
[例10] 查询年龄在20~23岁(包括20岁和23岁)之间的
学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
(3) 确定集合
使用谓词 IN<值表>, NOT IN <值表>
<值表>:用逗号分隔的一组取值
[例12]查询信息系(IS)、数学系(MA)和计
算机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' );
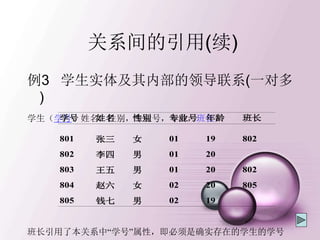
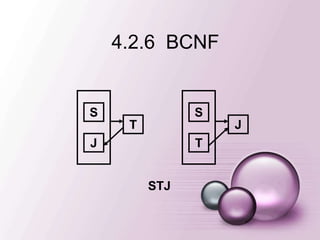
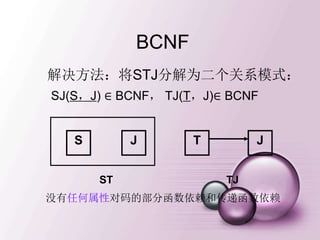
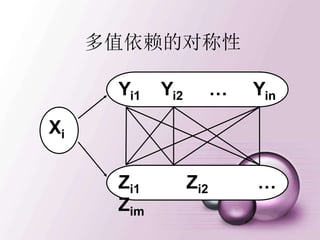
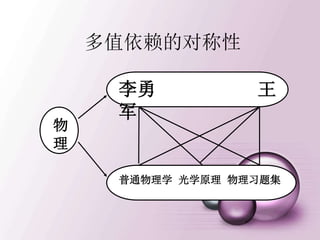
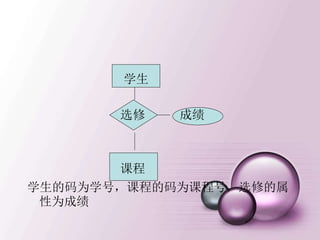
一、多值依赖
• 在R(U)的任一关系r中,如果存在元组t,s 使得
t[X]=s[X],那么就必然存在元组w,v r,(w,v可以
与s,t相同),使得w[X]=v[X]=t[X],而w[Y]=t[Y],
w[Z]=s[Z],v[Y]=s[Y],v[Z]=t[Z](即交换s,t元组的Y值
所得的两个新元组必在r中),则Y多值依赖于X,记为
X→→Y。 这里,X,Y是U的子集,Z=U-X-Y。
t x y1 z2
s x y2 z1
w x y1 z1
v x y2 z2
• Define XF
+= closure of X
= set of attributes functionally determined byX
• Basis: XF
+ :=X
• Induction: If Y XF
+, and Y A is a given FD,
then add A to XF
+
• End when XF
+ cannot be changed.
Algorithm
y
X+ New X+
A
334.
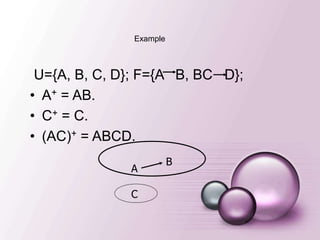
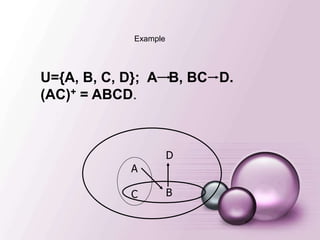
U={A, B, C,D}; F={A B, BC D};
• A+ = AB.
• C+ = C.
• (AC)+ = ABCD.
Example
A
C
B
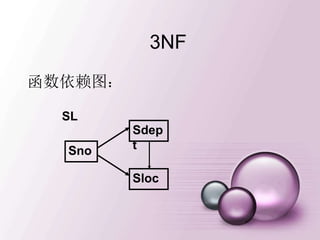
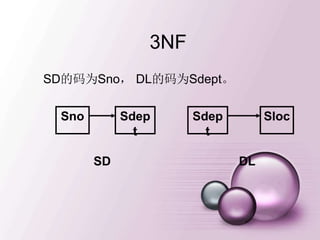
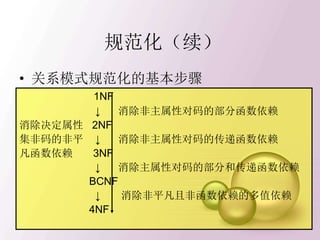
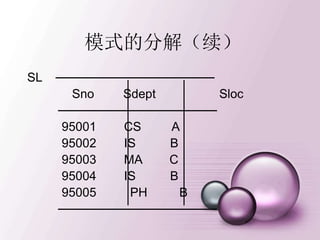
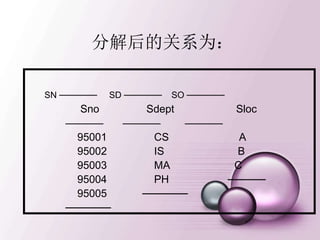
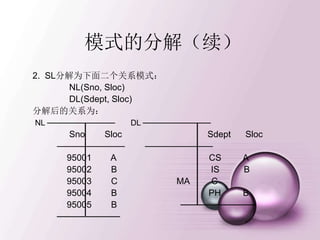
模式的分解(续)
2. SL分解为下面二个关系模式:
NL(Sno, Sloc)
DL(Sdept,Sloc)
分解后的关系为:
NL ──────────── DL ────────────
Sno Sloc Sdept Sloc
──────────── ────────────
95001 A CS A
95002 B IS B
95003 C MA C
95004 B PH B
95005 B ────────────
──────────
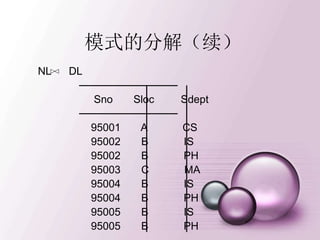
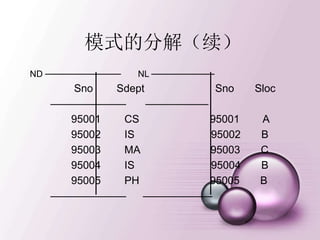
模式的分解(续)
ND ──────────── NL──────────
Sno Sdept Sno Sloc
──────────── ──────────
95001 CS 95001 A
95002 IS 95002 B
95003 MA 95003 C
95004 IS 95004 B
95005 PH 95005 B
──────────── ───────────
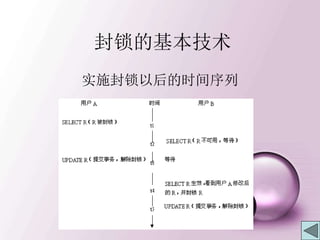
SQL Server中与封锁有关的命
令
…
DECLARE @ddatetime, @t char(6), @s char(2), @n char(10)
…
BEGIN TRANSACTION
SELECT @n=座位号 FROM R WITH (UPDLOCK)
WHERE 日期 = @d AND 车次 = @t AND 座别 = @s AND 状态 IS
NULL
…
IF …
UPDATE R SET 状态 = "Y"
WHERE 座位号 = @n AND 日期 = @d AND 车次 = @t AND 座别 =
@s
COMMIT TRANSACTION
ELSE
ROLLBACK TRANSACTION
授予对象权限
GRANT { ALL[ PRIVILEGES ] | permission_list }
{[ ( column_list ) ] ON { table | view } |
ON { table | view } [ ( column_list ) ]
| ON stored_procedure | ON
user_defined_function }
TO name_list
[ WITH GRANT OPTION ]
[ AS { group | role } ]
用户定义的安全性措施
CREATE TRIGGER secure_wh
ON仓库
FOR INSERT,DELETE,UPDATE
AS
IF DATENAME(weekday, getdate())='星期六'
OR DATENAME(weekday, getdate())='星期日'
OR (convert(INT,DATENAME(hour, getdate())) NOT
BETWEEN 9 AND 17)
BEGIN
RAISERROR ('只许在工作时间操作!', 16, 1)
ROLLBACK TRANSACTION
END




















































































































































![引入记号
• 关系模式R (A1,A2,…,An),t∈R表示R的一个
元组t。t[Ai] 表示属性元组t 中相应于属性Ai的分量
• 若A={Ai1,Ai2,…,Aik},其中Ai1,Ai2, …,Aik是A1
,A2,…,An的一部分A称作属性列或域列。
• 元组的连接
• 给定关系R(X,Z), 定义当t[X]=x时,x在R中的象集
为 表示R中属性组X上值
为x的诸元组在Z上分量的集合。
, ,
r s r s
t R t S t t
{ [ ] , [ ] }
x
Z t Z t R t X x
](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-166-320.jpg)




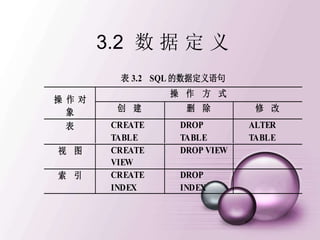
![3.2.1 定义语句格式
CREATE TABLE <表名>(
<列名> <数据类型> [<列级完整性约束>],
<列名> <数据类型> [<列级完整性约束>],
……,
[<表级完整性约束>]
) [<其它参数>]
Ÿ<表名>给出要创建的基本表的名称;
Ÿ<列名>给出列名或字段名;
Ÿ<数据类型>
Ÿ<列级完整性约束>
Ÿ<表级完整性约束>
Ÿ<其它参数>](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-173-320.jpg)



![例题
[例1] 建立一个“学生”表Student,它由学号Sno
、姓名Sname、性别Ssex、年龄Sage、所在
系Sdept五个属性组成。其中学号不能为空,
值是唯一的,并且姓名取值也唯一。
CREATE TABLE Student
(Sno CHAR(5) NOT NULL UNIQUE,
Sname CHAR(20) UNIQUE,
Ssex CHAR(1) ,
Sage INT,
Sdept CHAR(15));](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-178-320.jpg)
![二、修改基本表
ALTER TABLE <表名>
[ADD <新列名> <数据类型> [<列级完整性约束>]] |
[ DROP <完整性约束名> ]
[MODIFY <列名><数据类型>]
[DROP COLUMN <列名> ]
[ALTER COLUMN <列名> <数据类型> [<列级完整性约束>]
]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-179-320.jpg)
![例题
[例2] 向Student表增加“入学时间”列,其数据
类型为日期型。
ALTER TABLE Student ADD Scome DATE;
– 不论基本表中原来是否已有数据,新增加的列一律
为空值。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-180-320.jpg)
![例题
[例3] 将年龄的数据类型改为半字长整数。
ALTER TABLE Student MODIFY Sage
SMALLINT;
– 修改原有的列定义可能会破坏已有数据。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-181-320.jpg)
![例题
[例4] 删除关于学号必须取唯一值的约束。
ALTER TABLE Student DROP UNIQUE(Sno)
;
– SQL没有提供删除属性列的语句,只能间接实现,
先将原表中要保留的列及其内容复制到一个新表中
,然后删除原表,并将新表命名为原表名。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-182-320.jpg)



![一、建立索引
• 语句格式
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…);
– 用<表名>指定要建索引的基本表名字
– 索引可以建立在该表的一列或多列上,各列名之间用逗
号分隔
– 用<次序>指定索引值的排列次序,升序:ASC,降序:
DESC。缺省值:ASC
– UNIQUE表明此索引的每一个索引值只对应唯一的数据
记录
– CLUSTER表示要建立的索引是聚簇索引](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-186-320.jpg)




![例题
[例6] 为学生-课程数据库中的Student,
Course,SC三个表建立索引。其中Student表
按学号升序建唯一索引,Course表按课程号升
序建唯一索引,SC表按学号升序和课程号降
序建唯一索引。
CREATE UNIQUE INDEX Stusno ON Student(Sno)
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-191-320.jpg)
![二、删除索引
DROP INDEX <索引名>;
– 删除索引时,系统会从数据字典中删去有关
该索引的描述。
[例7] 删除Student表的Stusname索引。
DROP INDEX Stusname;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-192-320.jpg)
![3.3.1 概述
语句格式
SELECT [ALL|DISTINCT] <目标表达式>[, <目标表达式
>] …
FROM <表名或视图名>[, <表名或视图名>…]
[WHERE <条件表达式>]
[GROUP BY <列名1>[HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]];](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-193-320.jpg)








![[例5.*] 使用列别名改变查询结果的列标题
SELECT Sname NAME,'Year of Birth: ’ BIRTH,
2000-Sage BIRTHDAY,ISLOWER(Sdept) DEPARTMENT
FROM Student;
输出结果:
NAME BIRTH BIRTHDAY DEPARTMENT
------- ---------------- ------------- ------------------
李勇 Year of Birth: 1976 cs
刘晨 Year of Birth: 1977 is
王名 Year of Birth: 1978 ma
张立 Year of Birth: 1977 is](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-202-320.jpg)

![ALL 与 DISTINCT
[例6] 查询选修了课程的学生学号。
(1) SELECT Sno
FROM SC;
(因为默认的是ALL)
SELECT ALL Sno
FROM SC;
所以结果为: Sno
-------
95001
95001
95001
95002
95002](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-205-320.jpg)

![(1) 比较大小
在WHERE子句的<比较条件>中使用比较运算符
– =,>,<,>=,<=,!= 或 <>,!>,!<,
– 逻辑运算符NOT + 比较运算符
[例8] 查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20; 或
SELECT Sname,Sage
FROM Student
WHERE NOT Sage >= 20;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-208-320.jpg)

![(2) 确定范围
• 使用谓词 BETWEEN … (下限) AND …(上限)
NOT BETWEEN … AND …
[例10] 查询年龄在20~23岁(包括20岁和23岁)之间的
学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-210-320.jpg)
![例题(续)
[例11] 查询年龄不在20~23岁之间的学生姓名、
系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND
23;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-211-320.jpg)
![(3) 确定集合
使用谓词 IN <值表>, NOT IN <值表>
<值表>:用逗号分隔的一组取值
[例12]查询信息系(IS)、数学系(MA)和计
算机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' );](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-212-320.jpg)
![(3) 确定集合
[例13]查询既不是信息系、数学系,也不是计算
机科学系的学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept NOT IN ( 'IS','MA','CS' );](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-213-320.jpg)
![(4) 字符串匹配
• [NOT] LIKE ‘<匹配串>’ [ESCAPE ‘ <换码字符>’]
<匹配串>:指定匹配模板
匹配模板:固定字符串或含通配符的字符串
当匹配模板为固定字符串时,即不含通配符时
可以用 = 运算符取代 LIKE 谓词
用 != 或 < >运算符取代 NOT LIKE 谓词](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-214-320.jpg)


![例题
1) 匹配模板为固定字符串
[例14] 查询学号为95001的学生的详细情况。
SELECT *
FROM Student
WHERE Sno LIKE '95001';
等价于:
SELECT *
FROM Student
WHERE Sno = '95001';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-217-320.jpg)
![例题(续)
2) 匹配模板为含通配符的字符串
[例15] 查询所有姓刘学生的姓名、学号和性别。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE ‘刘%’;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-218-320.jpg)
![例题(续)
匹配模板为含通配符的字符串(续)
[例16] 查询姓"欧阳"且全名为三个汉字的学生的
姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_ _';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-219-320.jpg)
![例题(续)
匹配模板为含通配符的字符串(续)
[例17] 查询名字中第2个字为"阳"字的学生的姓
名和学号。
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '_ _阳%';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-220-320.jpg)
![例题(续)
匹配模板为含通配符的字符串(续)
[例18] 查询所有不姓刘的学生姓名。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE '刘%';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-221-320.jpg)
![例题(续)
3) 使用换码字符将通配符转义为普通字符
[例19] 查询DB_Design课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB_Design'
ESCAPE ''](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-222-320.jpg)
![例题(续)
使用换码字符将通配符转义为普通字
符(续)
[例20] 查询以"DB_"开头,且倒数第3个字
符为 i的课程的详细情况。
SELECT *
FROM Course
WHERE Cname LIKE 'DB_%i_ _'
ESCAPE ' ';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-223-320.jpg)
![(5) 涉及空值的查询
– 使用谓词 IS NULL 或 IS NOT NULL
– “IS NULL” 不能用 “= NULL” 代替
[例21] 某些学生选修课程后没有参加考试,所以有选课
记录,但没有考试成绩。查询缺少成绩的学生的学号
和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-224-320.jpg)
![例题(续)
[例22] 查所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-225-320.jpg)
![(6) 多重条件查询
用逻辑运算符AND和 OR来联结多个查询条件
• AND的优先级高于OR
• 可以用括号改变优先级
可用来实现多种其他谓词
• [NOT] IN
• [NOT] BETWEEN … AND …](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-226-320.jpg)
![例题
[例23] 查询计算机系年龄在20岁以下的学生姓名
。
SELECT Sname
FROM Student
WHERE Sdept= 'CS' AND Sage<20;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-227-320.jpg)
![改写[例12]
[例12] 查询信息系(IS)、数学系(MA)和计算
机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' )
可改写为:
SELECT Sname,Ssex
FROM Student
WHERE Sdept= ' IS ' OR Sdept= ' MA' OR
Sdept= ' CS ';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-228-320.jpg)
![改写[例10]
[例10] 查询年龄在20~23岁(包括20岁和23岁)
之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
可改写为:
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage>=20 AND Sage<=23;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-229-320.jpg)

![对查询结果排序(续)
[例24] 查询选修了3号课程的学生的学号
及其成绩,查询结果按分数降序排列。
SELECT Sno,Grade
FROM SC
WHERE Cno= ' 3 '
ORDER BY Grade DESC;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-231-320.jpg)
![对查询结果排序(续)
[例25] 查询全体学生情况,查询结果按所
在系的系号升序排列,同一系中的学生
按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept,Sage DESC;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-233-320.jpg)
![四、使用集函数
5类主要集函数
– 计数
COUNT([DISTINCT|ALL] *)
COUNT([DISTINCT|ALL] <列名>)
– 计算总和,(此列必须是数值型的)
SUM([DISTINCT|ALL] <列名>)
– 计算平均值,(此列必须是数值型的)
AVG([DISTINCT|ALL] <列名>)](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-234-320.jpg)
![使用集函数(续)
求最大值
MAX([DISTINCT|ALL] <列名>)
求最小值
MIN([DISTINCT|ALL] <列名>)
– DISTINCT短语:在计算时要取消指定列中
的重复值
– ALL短语:不取消重复值
– ALL为缺省值](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-235-320.jpg)
![使用集函数 (续)
[例26] 查询学生总人数。
SELECT COUNT(*)
FROM Student;
[例27] 查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno)
FROM SC;
注:用DISTINCT以避免重复计算学生人数](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-236-320.jpg)
![使用集函数 (续)
[例28] 计算1号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno= ' 1 ';
[例29] 查询选修1号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHER Cno= ' 1 ';](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-237-320.jpg)

![使用GROUP BY子句分组
[例30] 求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
结果
Cno COUNT(Sno)
1 22
2 34
3 44
4 33
5 48](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-239-320.jpg)

![使用HAVING短语筛选最终输出结果
[例31] 查询选修了3门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*) >3;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-241-320.jpg)
![例题
[例32] 查询有3门以上课程是90分以上的
学生的学号及(90分以上的)课程数
SELECT Sno, COUNT(*)
FROM SC
WHERE Grade>=90
GROUP BY Sno
HAVING COUNT(*)>=3;](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-242-320.jpg)


















































![一、多值依赖
• 在R(U)的任一关系r中,如果存在元组t,s 使得
t[X]=s[X],那么就必然存在元组 w,v r,(w,v可以
与s,t相同),使得w[X]=v[X]=t[X],而w[Y]=t[Y],
w[Z]=s[Z],v[Y]=s[Y],v[Z]=t[Z](即交换s,t元组的Y值
所得的两个新元组必在r中),则Y多值依赖于X,记为
X→→Y。 这里,X,Y是U的子集,Z=U-X-Y。
t x y1 z2
s x y2 z1
w x y1 z1
v x y2 z2](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-303-320.jpg)

















![(l)自反律:若Y X U,则X →Y为F所蕴含
证: 设Y X U
对R <U,F> 的任一关系r中的任意两个元组t,s:
若t[X]=s[X],由于Y X,有t[y]=s[y],
所以X→Y成立.
自反律得证
定理4.1 Armstrong推理规则是正确的](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-324-320.jpg)
![(2)增广律: 若X→Y为F所蕴含,且Z U,则XZ→YZ
为F所蕴含。
证:设X→Y为F所蕴含,且Z U。
设R<U,F> 的任一关系r中任意的两个元组t,s;
若t[XZ]=s[XZ],则有t[X]=s[X]和t[Z]=s[Z];
由X→Y,于是有t[Y]=s[Y],所以t[YZ]=s[YZ],所以
XZ→YZ为F所蕴含.
增广律得证。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-325-320.jpg)
![(3) 传递律:若X→Y及Y→Z为F所蕴含,则
X→Z为 F所蕴含。
证:设X→Y及Y→Z为F所蕴含。
对R<U,F> 的任一关系 r中的任意两个元组 t,s。
若t[X]=s[X],由于X→Y,有 t[Y]=s[Y];
再由Y→Z,有t[Z]=s[Z],所以X→Z为F所蕴含.
传递律得证。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-326-320.jpg)







![函数依赖闭包
[例1] 已知关系模式R<U,F>,其中
U={A,B,C,D,E};
F={AB→C,B→D,C→E,EC→B,AC→B}
。
求(AB)F
+ 。
解 设X(0)=AB;
(1)计算X(1): 逐一的扫描F集合中各个函数依赖,
找左部为A,B或AB的函数依赖。得到两个:
AB→C,B→D。
于是X(1)=AB∪CD=ABCD。](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-336-320.jpg)











![最小依赖集
[例2] 对于5.l节中的关系模式S<U,F>,其中:
U={ SNO,SDEPT,MN,CNAME,G },
F={ SNO→SDEPT,SDEPT→MN,
(SNO,CNAME)→G }
设F’={SNO→SDEPT,SNO→MN,
SDEPT→MN,(SNO,CNAME)→G,
(SNO,SDEPT)→SDEPT}
F是最小覆盖,而F ’不是。
因为:F ’-{SNO→MN}与F ’等价
F ’-{(SNO,SDEPT)→SDEPT}也与F ’等价
F ’-{(SNO,SDEPT)→SDEPT}
∪{SNO→SDEPT}也与F ’等价](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-348-320.jpg)




![极小化过程
[例3] F = {A→B,B→A,B→C,
A→C,C→A}
Fm1、Fm2都是F的最小依赖集:
Fm1= {A→B,B→C,C→A}
Fm2= {A→B,B→A,A→C,C→A}
• F的最小依赖集Fm不一定是唯一的它与对各函
数依赖FDi 及X→A中X各属性的处置顺序有关](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-353-320.jpg)



































































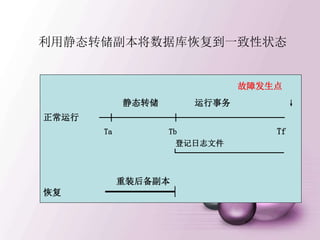
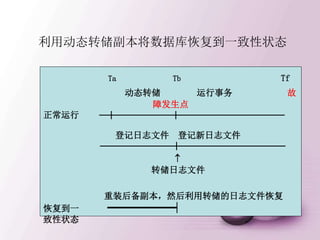





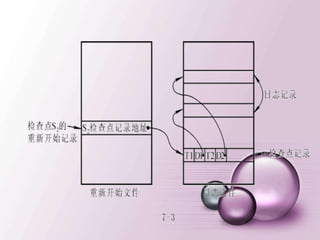

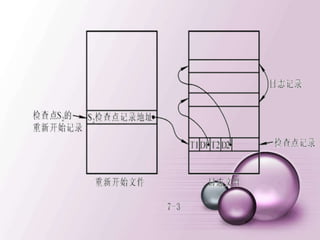
























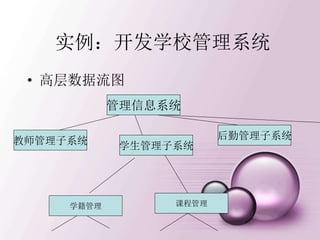





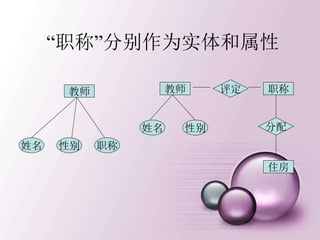
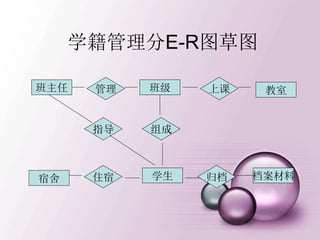

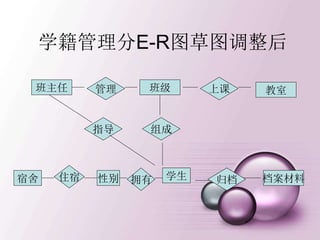











































































































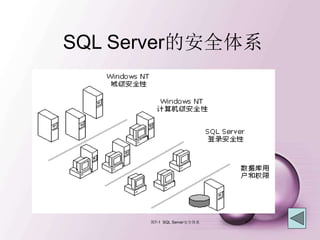

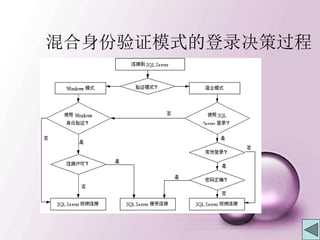


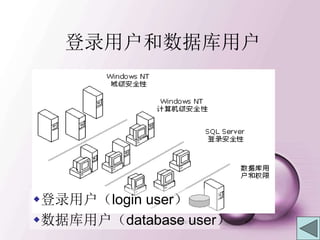

![建立新的登录用户
sp_addlogin [@loginname=] login_id
[,[@passwd=]passwd]
[,[@defdb=]defdb]
[,[@deflanguage=]deflanguage]
[,[@sid=]sid]
[,[@encryptopt =]encryption_option]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-600-320.jpg)
![修改登录密码
sp_password [ [ @old = ] old_password , ]
{ [ @new =] new_password }
[ , [ @loginame = ] login ]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-601-320.jpg)
![删除登录用户
sp_droplogin [ @loginame = ] login](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-602-320.jpg)
![授权登录用户为当前数据库用户
sp_grantdbaccess [@loginame =] login
[,[@name_in_db =] name_in_db]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-603-320.jpg)
![从当前数据库中删除用户
sp_revokedbaccess [ @name_in_db = ]
name](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-604-320.jpg)

![定义角色
sp_addrole [ @rolename = ] role
[ , [ @ownername = ] owner ]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-606-320.jpg)
![为用户指定角色
sp_addrolemember [ @rolename = ] role
,
[ @membername = ] user_account](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-607-320.jpg)
![取消用户的角色
sp_droprolemember [ @rolename = ] role
,
[ @membername = ] user_account](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-608-320.jpg)
![删除角色
sp_droprole [@rolename = ] role](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-609-320.jpg)







![授予对象权限
GRANT { ALL [ PRIVILEGES ] | permission_list }
{[ ( column_list ) ] ON { table | view } |
ON { table | view } [ ( column_list ) ]
| ON stored_procedure | ON
user_defined_function }
TO name_list
[ WITH GRANT OPTION ]
[ AS { group | role } ]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-617-320.jpg)

![收回权限
• 收回语句授权
REVOKE { ALL | statement_list } FROM name_list
• 收回对象授权
REVOKE [GRANT OPTION FOR]
{ ALL [ PRIVILEGES ] | permission_list }
{[ ( column_list ) ] ON { table | view } | ON { table |
view } [ ( column_list ) ]
| ON stored_procedure | ON user_defined_function }
FROM name_list
[ CASCADE ]
[ AS { group | role } ]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-619-320.jpg)
![禁止权限
• 禁止语句权限
DENY { ALL | statement_list } TO name_list
• 禁止对象权限
DENY { ALL [ PRIVILEGES ] | permission_list }
{[ ( column_list ) ] ON { table | view } | ON { table |
view } [ ( column_list ) ]
| ON stored_procedure | ON user_defined_function
}
TO name_list
[CASCADE]](https://image.slidesharecdn.com/random-240706042723-b7de233b/85/Database-Principles-Course-complete-edition-620-320.jpg)



































