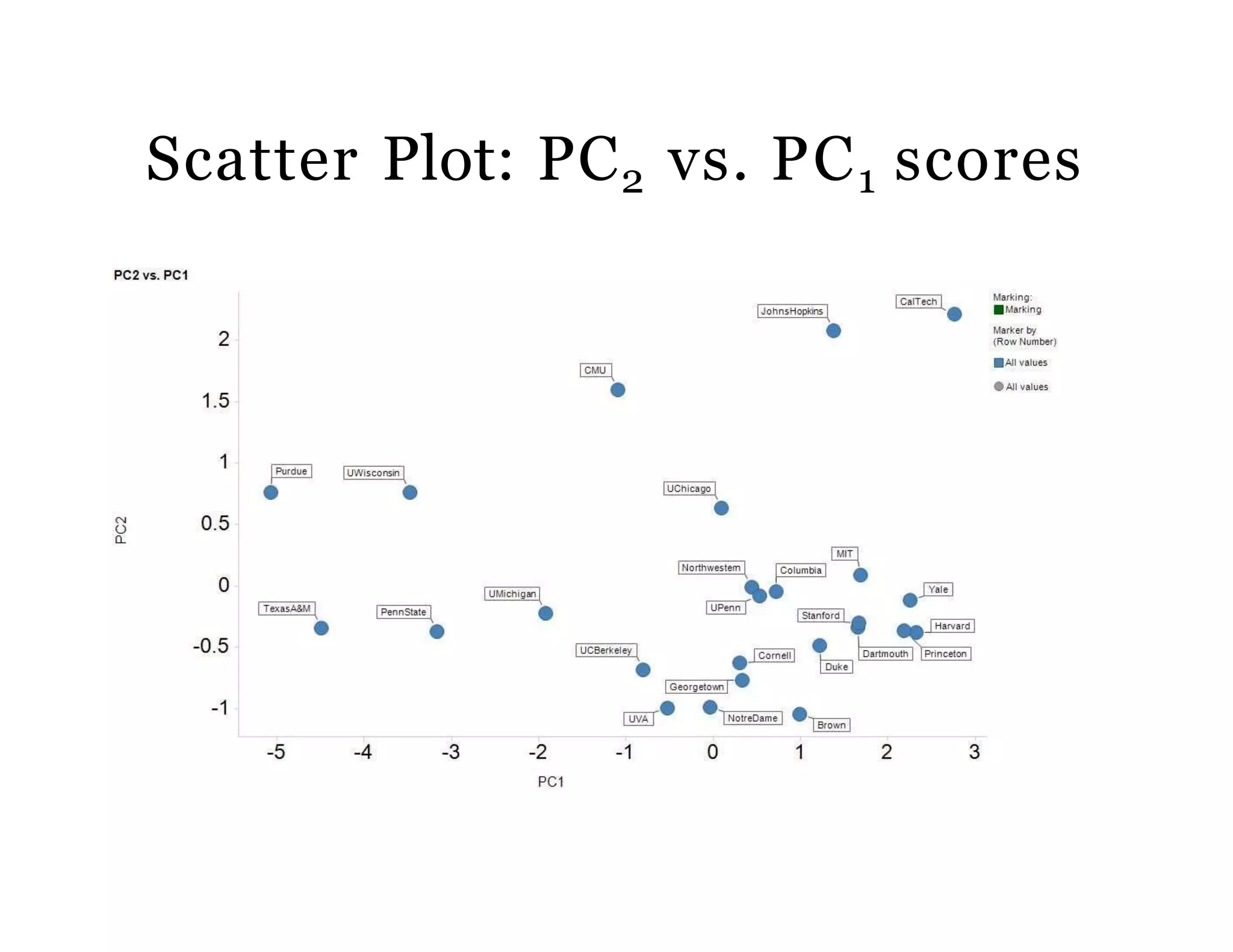
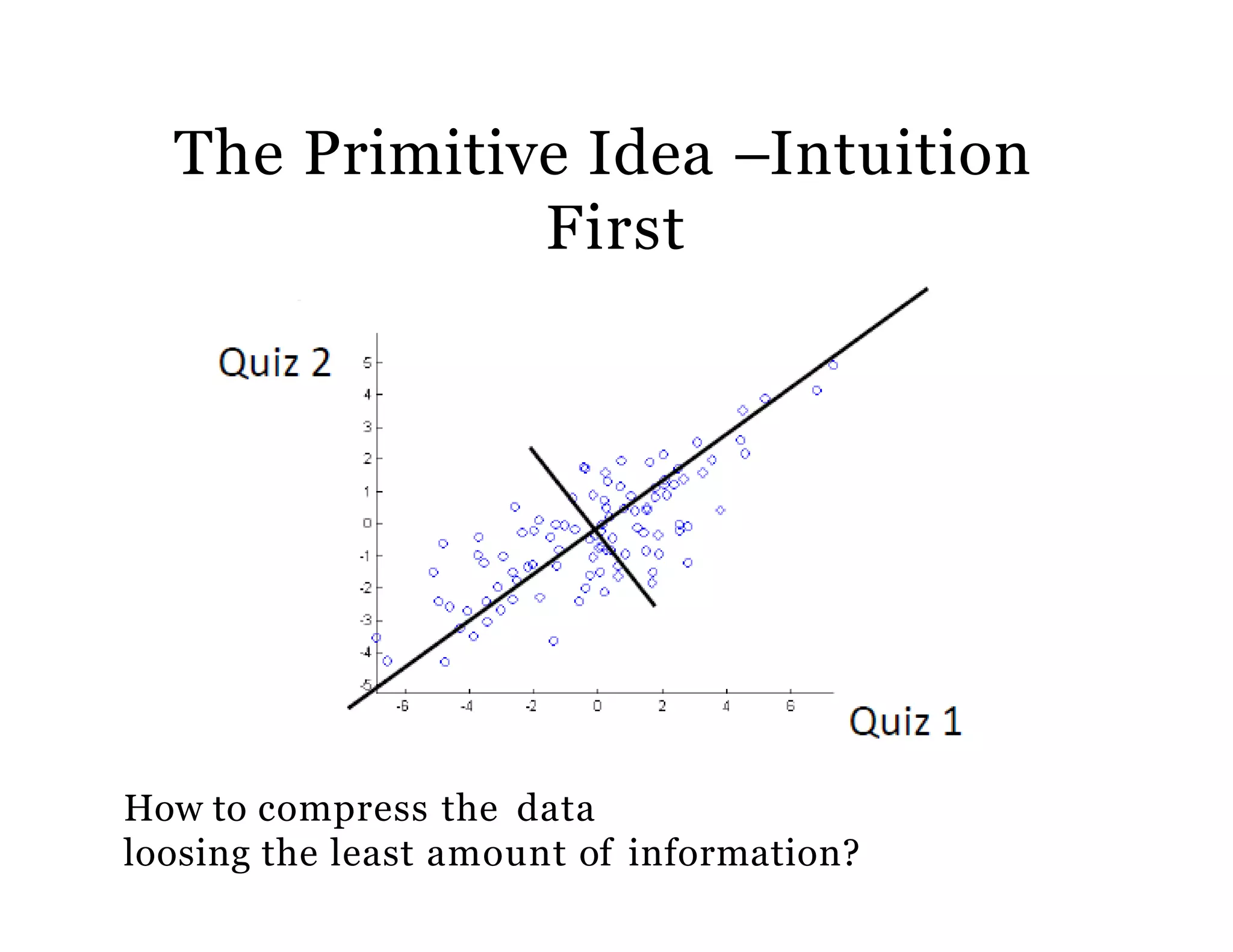
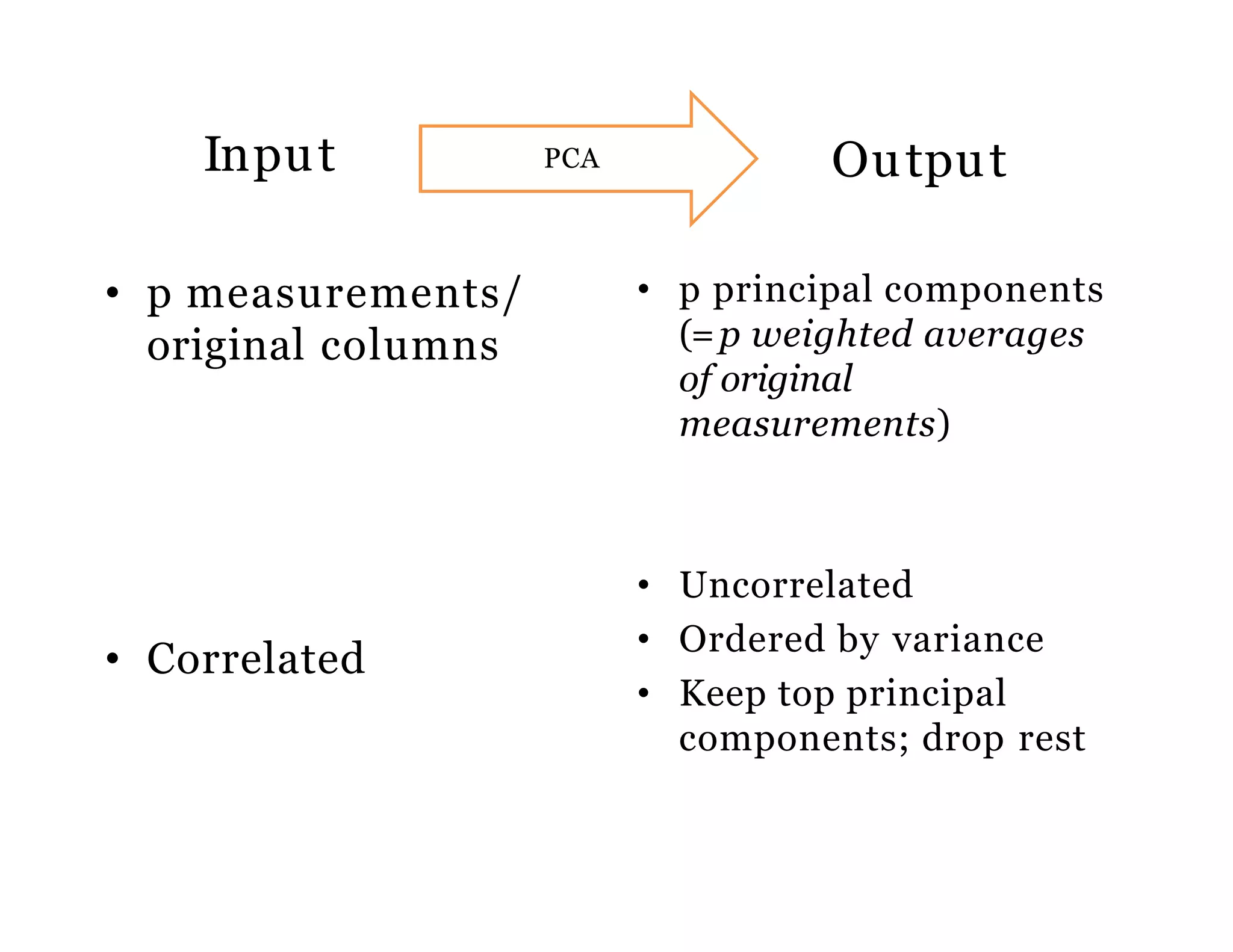
The document discusses the application of Principal Components Analysis (PCA) in business analytics, emphasizing its computational advantages such as data dimension reduction, improved face recognition, and image compression. It includes details about standardized input data, the process of calculating principal components, and their significance in visualizing relationships among different variables. Additionally, it provides R code examples for performing PCA and highlights the method's ability to simplify data analysis by retaining only the most informative dimensions.











![R Code for PCA (Assignment)
OPTIONAL RCode
install.packages("gdata") ##for reading xls files
install.packages("xlsx") ## ”for reading xlsxfiles
mydata<-read.xlsx("UniversityRanking.xlsx",1) ## use read.csv for csv files
mydata## make sure the datais loadedcorrectly
help(princomp) ## to understand the api for princomp
pcaObj<-princomp(mydata[1:25,2:7], cor = TRUE, scores = TRUE, covmat = NULL)
## the first column in mydatahas universitynames
## princomp(mydata,cor = TRUE) not_same_as prcomp(mydata,scale=TRUE);similar,but different
summary(pcaObj)
loadings(pcaObj)
plot(pcaObj)
biplot(pcaObj)
pcaObj$loadings
pcaObj$scores](https://image.slidesharecdn.com/dataanalyticestraininginbangalore-converted-191216105810/75/Data-Analytics-Courses-14-2048.jpg)