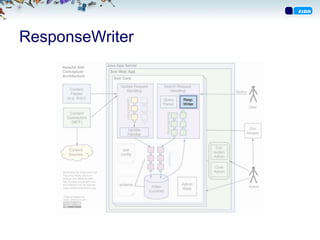
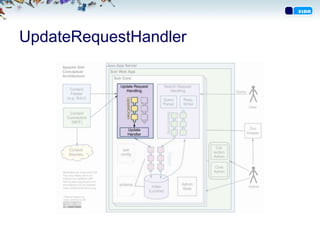
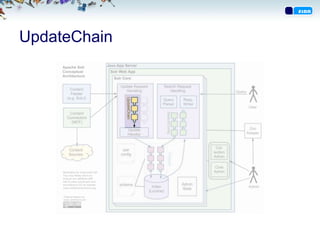
Struktur
• Dokument erenheten som blir lagret i indeksen
• Dokument består av felter
• Felter har sin egen konfigurasjon
– Type – Hvilken type feltet er (int, string, egne typer)
– Stored – Om innholdet kan returneres (true|false)
– Indexed – Om innholdet kan søkes/filtreres/sorteres på
(true|false)
– Multivalue – Om det er lov med flere verdier (true|false)
– Analyse – Hvordan innholdet skal håndteres ved
indeksering og søk
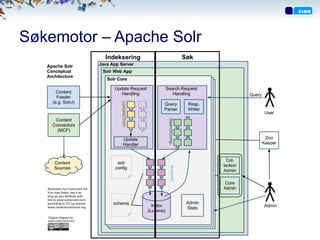
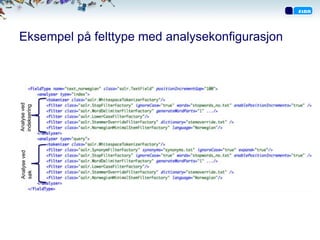
Analyse ved indeksering
•Analyse kjøres pr felt
• Felttype definerer liste med analyse-steg
• Kan overstyres på feltnivå
Tittel Tittel Tittel Tittel
LowerCase
”To
Stemming
[To, [to,
Tokeinzer
[to, stol,
stoler til stoler, til, stoler, til,
til, salg,
salgs i salgs, i, salgs, i,
i, oslo]
Oslo” Oslo] oslo]
12.
Eksempel på felttypemed analysekonfigurasjon
Analyse ved
indeksering
Analyse ved
søk
13.
Eksempler på analyse
•CharFilterFactories (normalisere aksent-er og umlaut-er)
– é e, ö o, å a
• WhitespaceTokenizer - dele opp i ord/tokens
– Dette er en test Dette, er, en, test
• Pr token
– Lowercase
• Dette dette
– Synonym
• Sovesofa sofa
– Stoppord
• Fjerner ord uten mening
– Ordsplitting
• Tex-Mex|TexMex Tex Mex
– Stemming/lemmatisering
• Gule gul, biler bil
14.
Eksempel på stemmer(NorwegianMinimalStemmer)
husene-> hus
huset -> hus
husa-> hus
15.
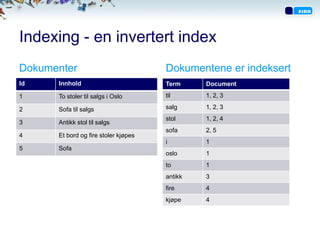
Indexing - eninvertert index
Dokumenter Dokumentene er indeksert
Id Innhold Term Document
1 To stoler til salgs i Oslo til 1, 2, 3
2 Sofa til salgs salg 1, 2, 3
stol 1, 2, 4
3 Antikk stol til salgs
sofa 2, 5
4 Et bord og fire stoler kjøpes
i 1
5 Sofa
oslo 1
to 1
antikk 3
fire 4
kjøpe 4
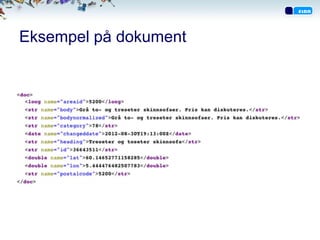
Søk
Indeks
• Analyse Tittel
– Samme som ved indeksering
[to, stol,
• Query til, salg,
i, oslo]
– Filtrerer og brukes for å regne ut
relevans
Query Query LowerCase Query Query
Stemming
Tokeinzer
”Stol [Stol, [stol, [stol,
Oslo” Oslo] oslo] oslo]
19.
Relevans
• Relevans eret tall som beskriver hvor godt
dokumentet passer søket
• Relvans er satt sammen av en
– Dynamisk faktor
– Statisk faktor
– Rankbidrag basert på funksjoner
20.
Relevans
• Dynamisk rank • Statisk boost
– TF * IDF – Viktige/bedre dokument kan
• Term frequency (TF) rankes høyere uavhengig av
sqrt(freq) hva man søker på
• Inverse Document Frequency (IDF) • Function queries
log(numDocs/(freq +1))
– Boost på dato i forhold til
– Position dagens dato (freshness)
• Hvor tidlig i feltet det står – Boost på avstand fra et
”sofa selges” > ”selger sofa”
punkt (geodistance)
– QueryNorm
• Hvor stor andel av feltet
”sofa” > ”sofa til salgs”
21.
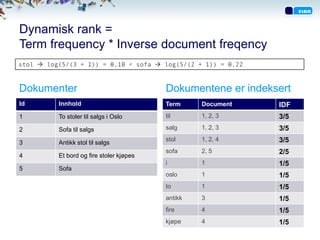
Dynamisk rank =
Termfrequency * Inverse document freqency
stol log(5/(3 + 1)) = 0,10 < sofa log(5/(2 + 1)) = 0,22
Dokumenter Dokumentene er indeksert
Id Innhold Term Document IDF
1 To stoler til salgs i Oslo til 1, 2, 3 3/5
2 Sofa til salgs salg 1, 2, 3 3/5
stol 1, 2, 4 3/5
3 Antikk stol til salgs
sofa 2, 5 2/5
4 Et bord og fire stoler kjøpes
i 1 1/5
5 Sofa
oslo 1 1/5
to 1 1/5
antikk 3 1/5
fire 4 1/5
kjøpe 4 1/5
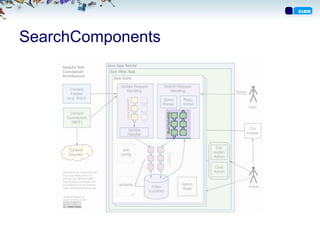
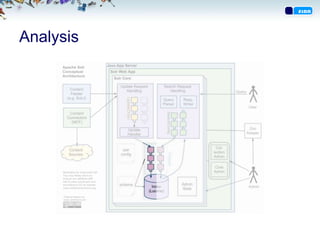
SearchComponents
• Komponenter mankan legge på i ”pipeline” for å
endre resultatsettet.
• Eksempler
– FacetComponent
• Dele opp søkeresultat i katergorier med antall i hver kategori
– MoreLikeThis
• Finne andre som ligner
– Highlighting
• Markere søkeordtreff i resultatet
– StatsComponent
• Regne ut statistikker for resultatsettet
– QueryElevationComponent
• ”heve” resultater i resultatsettet basert på regler og ikke
relevans





![Analyse ved indeksering
• Analyse kjøres pr felt
• Felttype definerer liste med analyse-steg
• Kan overstyres på feltnivå
Tittel Tittel Tittel Tittel
LowerCase
”To
Stemming
[To, [to,
Tokeinzer
[to, stol,
stoler til stoler, til, stoler, til,
til, salg,
salgs i salgs, i, salgs, i,
i, oslo]
Oslo” Oslo] oslo]](https://image.slidesharecdn.com/dagenifi-121109033625-phpapp02/85/Hvordan-fungerer-en-sokemotor-11-320.jpg)



![Søk
Indeks
• Analyse Tittel
– Samme som ved indeksering
[to, stol,
• Query til, salg,
i, oslo]
– Filtrerer og brukes for å regne ut
relevans
Query Query LowerCase Query Query
Stemming
Tokeinzer
”Stol [Stol, [stol, [stol,
Oslo” Oslo] oslo] oslo]](https://image.slidesharecdn.com/dagenifi-121109033625-phpapp02/85/Hvordan-fungerer-en-sokemotor-18-320.jpg)