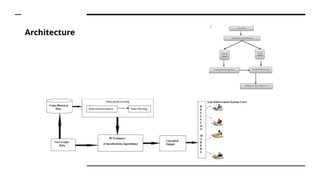
The document discusses a machine learning project focused on crime prediction and prevention, utilizing data analysis to improve crime investigation efficiency. It outlines the use of various algorithms, including decision trees and random forests, to analyze crime data and detect patterns, thereby aiding law enforcement agencies. The study emphasizes the significance of transitioning to empirical, data-driven approaches for more accurate and timely crime predictions.











![Refrences
[1] Shiju Sathyadevan, Devan M, Surya Gangadharan.
Analysis and Prediction Using Data Mining, 2014 First International Conference on Networks & Soft
Computing.
[2] Abba Babakura, Md Nasir Sulaiman and Mahmud A. Yusuf, Improved Method of Classification
Algorithms
for Crime Prediction,2014 International Symposium on Biometrics and Security Technologies
(ISBAST).
[3] Jazeem Azeez, D. John Aravindhar, Hybrid Approach to Crime Prediction using Deep learning, 2015
International Conference on Advances in Computing, Communications and Informatics (ICACCI).
[4] Sathyadevan, S., & Gangadharan, S. (2014, August). Crime analysis and prediction using data mining.
In Networks & Soft Computing (ICNSC), 2014 First International Conference on (pp. 406-412). IEEE.
[5] Nath, S. V. (2006, December). Crime pattern detection using data mining. In Web intelligence and
intelligent agent technology workshops, 2006. wi-iat 2006 workshops. 2006 ieee/wic/acm international
conference on (pp. 41-44). IEEE.
[6] Zhao, X., & Tang, J. (2017, November). Exploring Transfer Learning for Crime Prediction. In Data
Mining Workshops (ICDMW), 2017 IEEE International Conference on (pp. 1158-1159). IEEE.](https://image.slidesharecdn.com/crimepredictionproject-241221234520-7ae49bad/85/CRIME-PREDICTION-prediction-and-analysisPROJECT-pptx-13-320.jpg)
















































