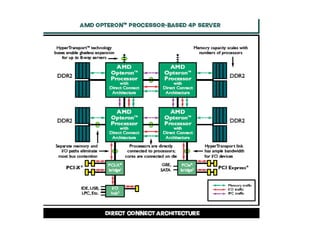
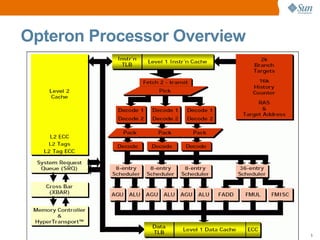
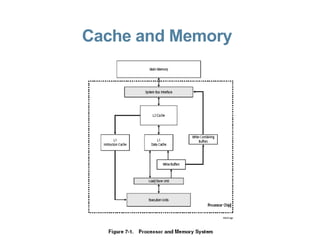
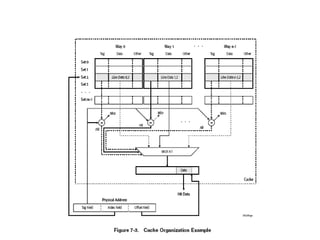
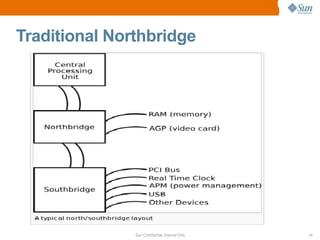
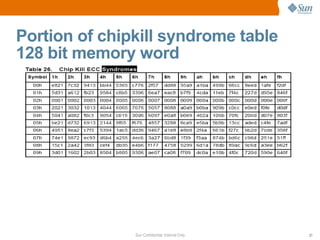
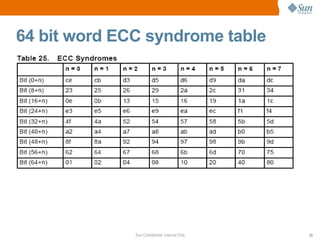
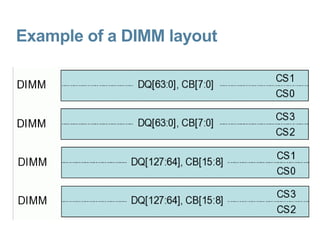
The document discusses CPU and memory architecture, error handling, and troubleshooting for Opteron processors. It covers cache and memory organization, error reporting banks, correctable and uncorrectable error types, machine check exceptions, memory addressing including interleaving and the memory hole, and provides examples of error messages from Linux and Solaris systems.
![CPU and Memory Events [email_address]](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/85/Cpu-And-Memory-Events-1-320.jpg)
![CPU and Memory Events [email_address]](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/75/Cpu-And-Memory-Events-1-2048.jpg)


































![Memory Hole address range without remapping Node address range displayed at boot. Each Node has 4GB node 0 has “lost” memory (a 4G address range would be 000000000000000-00000000ffffffff) Memory hole exists between dfffffff and fffffff =20000000 [root@va64-x4100f-gmp03 log]# pwd /var/log [root@va64-x4100f-gmp03 log]# grep -i Bootmem mess* Bootmem setup node 0 000000000000000-00000000dfffffff Bootmem setup node 1 0000000100000000-00000001ffffffff](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/85/Cpu-And-Memory-Events-45-320.jpg)











![fmd: [ID 441519 daemon.error] SUNW-MSG-ID: AMD-8000-3K, TYPE: Fault, VER: 1, SEVERITY: Major EVENT-TIME: Sat Mar 10 00:52:13 MET 2007 PLATFORM: Sun Fire X4100 Server, CSN: 0606AN1288 , HOSTNAME: siegert SOURCE: eft, REV: 1.16 EVENT-ID: 13441a52-c465-629b-ca9d-fc77b0e66354 DESC: The number of errors associated with this memory module has exceeded acceptable levels. Refer to http://sun.com/msg/AMD-8000-3K for more information. AUTO-RESPONSE: Pages of memory associated with this memory module are being removed from service as errors are reported. IMPACT: Total system memory capacity will be reduced as pages are retired. REC-ACTION: Schedule a repair procedure to replace the affected memory module. Use fmdump -v -u <EVENT_ID> to identify the module.](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/85/Cpu-And-Memory-Events-57-320.jpg)


![SUNW-MSG-ID: SUNOS-8000-0G, TYPE: Error, VER: 1, SEVERITY: Major EVENT-TIME: 0x459d66e9.0xbf18650 (0x687a83db95e45) i86pc, CSN: -, HOSTNAME: SOURCE: SunOS, REV: 5.10 Generic_118855-14 DESC: Errors have been detected that require a reboot to ensure system integrity. See http://www.sun.com/msg/SUNOS-8000-0G for more information. Thu Jan 4 21:43:21 2007]AUTO-RESPONSE: Solaris will attempt to save and diagnose the error telemetry REC-ACTION: Save the error summary below in case telemetry cannot be saved [Thu Jan 4 21:43:21 2007] [Thu Jan 4 21:43:21 2007]ereport.cpu.amd.bu.l2t_par ena=7a83db8bc8500401 detector=[ > > version=0 scheme= "hc" hc-list=[...] ] bank-status=b60000000002017a bank-number=2 addr=5a0c addr-valid=1 ip=0 privileged=1 ereport.cpu.amd.bu.l2t_par ena=7a83db9517700401](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/85/Cpu-And-Memory-Events-60-320.jpg)
![System now panics and then reboots panic[cpu1]/thread=fffffe800032fc80: Unrecoverable Machine-Check Exception dumping to /dev/dsk/c0t0d0s1, offset 860356608,](https://image.slidesharecdn.com/cpuandmemoryevents-100324135846-phpapp02/85/Cpu-And-Memory-Events-61-320.jpg)





























![[ PPT ] NS _ppt 4..ppt microprocesser and microcontroller fundamentals](https://cdn.slidesharecdn.com/ss_thumbnails/gurukulkangriuniversity-121014110754-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)















![Chap 02[1]](https://cdn.slidesharecdn.com/ss_thumbnails/chap021-140914002518-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























