Download to read offline









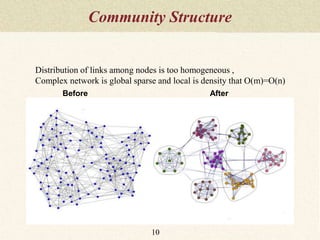


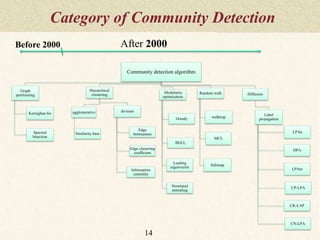







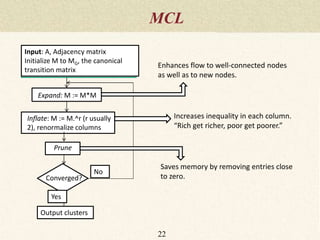






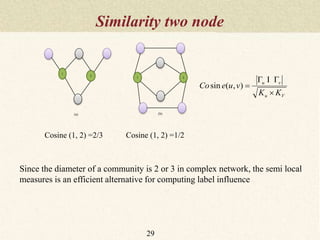





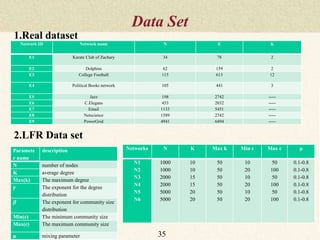


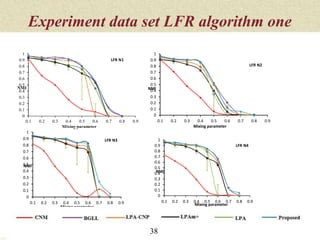




This document summarizes a thesis proposal on detecting community structure in social networks using label propagation algorithms. It begins with an introduction to complex networks and community structure detection. It then reviews several popular community detection algorithms including graph partitioning, hierarchical clustering, modularity optimization, random walks, and label propagation algorithms. The document proposes two new label propagation algorithms that incorporate measures of node and label influence to improve community detection accuracy. An example is provided to illustrate how the proposed algorithms would work.
























































