Download as PDF, PPTX


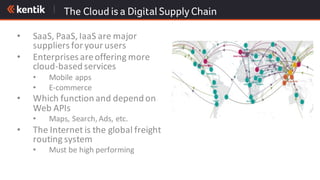






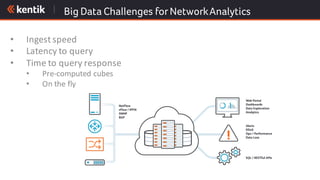


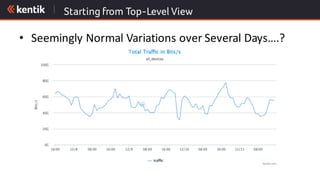
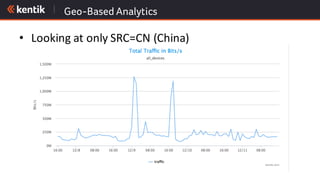
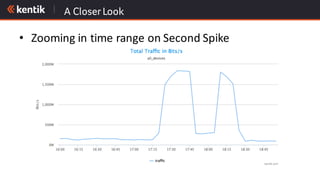
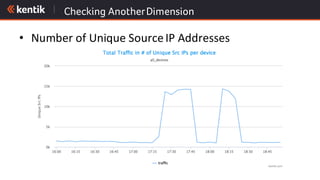

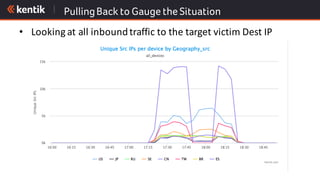
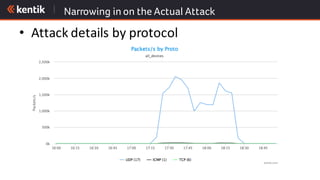
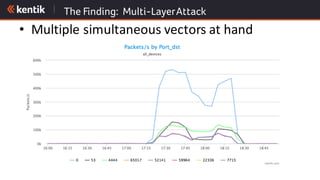





The document discusses the importance of cloud-aware network management in ensuring high performance and user experience amid increasing reliance on cloud services. It outlines key strategies and tactics for efficient network management, such as collecting detailed traffic flow data and utilizing advanced analytics for anomaly detection. The document emphasizes that traditional approaches are insufficient for managing large network data, advocating for big data analytics to improve operational responses and enhance visibility across hybrid environments.


















![Kurt Schneider [Discover Financial] | How Discover Modernizes Observability w...](https://cdn.slidesharecdn.com/ss_thumbnails/session-influxdays-schneidercroft103020202-201103001840-thumbnail.jpg?width=640&height=640&fit=bounds)















































