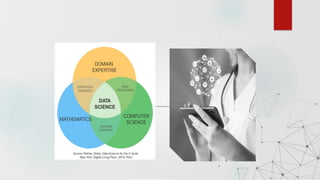
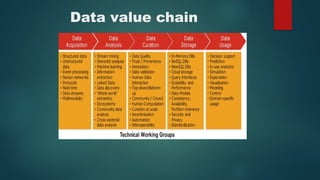
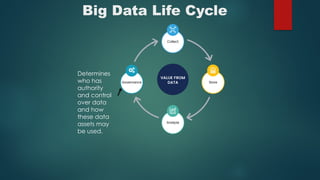
Chapter 2 discusses the significance of data science, highlighting its role in extracting knowledge from various forms of data and the importance of data scientists in this process. It explains the data processing cycle, different types of data (structured, unstructured, semi-structured), and introduces the concept of big data and its characteristics. Moreover, it covers technologies like Hadoop and the stages of big data processing, including ingestion, storage, and analysis.






































![Chapter 2 - Intro to Data Sciences[2].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-introtodatasciences2-230326001432-ec8e4032-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





