7.2 信源分类及其统计特性描
述
单消息(符号)离散信源
只输出一个离散符号
统计特性描述
用 符 号 可 能 取 值 范 围 X 和 符 号 取 值 x i的 概 率 P x i 描 述
X x1 , , xi , , xn
P x i P x1 , , P xi , , P xn
n
其 中 , 0 P x i 1, i 1, 2, , n, 且 P x i 1
i 1
5.
7.2 信源分类及其统计特性描
述
离散消息(符号)序列信源
输出一个离散消息(符号)序列
统计特性描述
离 散 消 息 序 列 由 L 个 符 号 组 成 , 则 消 息 序 列 可 表 示 成 L维 随 机 矢 量
X X 1, , X i, , X L ,
其 可 能 取 值 x x1 , , xL 有 n 种 可 能 性 , 构 成 取 值 集 合 X
L L
, xi ,
P x P x1 , , xi , , x L P x 1 P x 2 | x1 P x 3 | x 2 , x1 P x L | x L 1 , , x1
则离散消息序列的统计特性表示为取值集合及其取值概率
X L a1 , , ai , , anL
P x P a1 ,
, P ai , ,
P anL
6.
7.2 信源分类及其统计特性描
述
离散消息(符号)序列信源
离散无记忆序列信源:序列中前后符号相互
统计独立 L
P x P x , , x , , x P x
1 l L l
l 1
离散有记忆序列信源:序列中前后符号不是
相互统计独立的
可用马尔可夫链表示
7.
7.3 信息熵H(X)
信息的基本特征:不确定性。因此信息应该是
概率P的函数
信息的两个特点
随概率P的递减性:概率越大,信息量越小
P x , I P x
可加性:两个独立消息的总信息量应是两个消息的
信息量的和
I P x P y I P x I P y
满足这两个条件的表示信息量的函数只有一种
可能:对数函数
8.
7.3 信息熵H(X)
单消息离散信源的信息度量
自信息量:出现某个消息时的信息量
1
I P x i log
log P x i
P xi
理解:消息出现概率越小,信息量越大
9.
7.3 信息熵H(X)
单消息离散信源的信息度量
两个单消息离散信源X,Y的联合信息量
知 道 了 消 息 x i的 情 况 下 , 消 息 y i 新 带 来 的 信 息 量 :
I P y i | x i log P y i | x i
知 道 了 消 息 y i的 情 况 下 , 消 息 x i 新 带 来 的 信 息 量 :
I P x i | y i log P x i | y i
两 个 消 息 x i, y i 一 共 带 来 的 信 息 量 :
I P x i , y i log P x i , y i
10.
7.3 信息熵H(X)
单消息离散信源的信息熵
前面定义的是一个具体消息的信息量,因为信源输
出的消息有多种可能性,所以可以把信息熵理解为
这个输出消息(考虑多种可能性)的平均信息量
n
H X
E I P x i E log P x i P x i log P x i
i 1
信息熵也可以理解为对信源的不确定性的平均度量
在各种可能性等概时,信源的信息熵最大(图7.3.1)
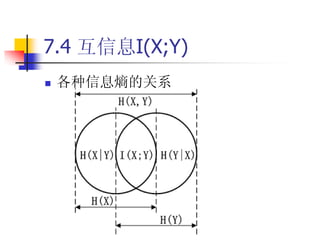
7.3 信息熵H(X)
两个单消息离散信源的联合熵和条件熵
联 合 熵 两 个 符 号 X ,Y 带 来 的 总 信 息 熵 / 平 均 信 息 量
n m
H X ,Y E I P x i , y j E log P x i , y j P x , y log P x , y
i j i j
i 1 j 1
条 件 熵 知 道 一 个 符 号 条 件 下 , 另 一 个 符 号 带 来 的 信 息 熵 / 平 均 信 息 量
n m
H Y | X E I P y j | x i E log P y j | x i P x , y log P y | xi
i j j
i 1 j 1
n m
H X | Y E I P x i | y j E log P x i | y j P x , y log P x | yj
i j i
i 1 j 1
13.
7.3 信息熵H(X)
联合熵和条件熵的一些性质
1 H X , Y H X H Y |X H Y H X |Y
理解为两符号先后到达的过程:两个符号的总信息熵
=一个符号的信息熵+知道这个符号的条件下另一个符号带来的信息熵
2 S h an n o n 不 等 式 : H X H X | Y ; H Y H Y | X
理解:一个消息没有任何前兆时带来的信息肯定大于等于有前兆带来的信息
当 X ,Y 独 立 时 , 等 号 成 立 ; 否 则 都 是 大 于 号 成 立
3 X ,Y 统 计 独 立 时 , 其 联 合 熵 取 最 大 值 两 符 号 信 息 熵 之 和
H X , Y m ax H X H Y
14.
7.3 信息熵H(X)
离散消息序列信源的信息熵、剩余度
离 散 平 稳 有 记 忆 信 源 输 出 的 消 息 序 列 为 X X 1, , X i, ,XL
1 其 总 信 息 熵 为
H X H X 1, ,XL H X1 H X 2 | X1 H XL | X 1, , X L 1
其 中 , 每 发 一 个 符 号 具 有 不 同 的 信 息 熵 依 次 递 减 :
0 H XL | X 1, , X L 1 H X2 | X1 H X1
2定 义 平 均 符 号 信 息 熵 为 : 总 信 息 熵 除 以 符 号 个 数
1 1
HLX H X 1, , X L , H X lim H X 1, ,XL
L L L
7.4 互信息I(X;Y)
互信息的定义I(X;Y)及理解
前 面 已 知 : H X ,Y H X H Y |X H Y H X | Y
H X H X | Y ; H Y H Y | X
由此可见:H X H X |Y H Y H Y | X 0
P xi
互 信 息 定 义 : I X ;Y H X H X |Y E log E i xi ; y j
P xi | y j
Pyj
H Y H Y | X E log E i y j ; xi
P y j | xi
互 信 息 的 理 解 : H X 是 X 所 含 的 信 息 ; H X |Y 是 已 知 Y的 条 件 下
X 还能带来的信息量。那么两者之差自然就是由于知道Y使得X 减
少的信息量,也即由Y 可以得到的关于X的信息量