Download as PDF, PPTX





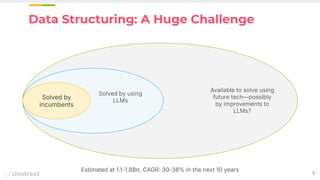

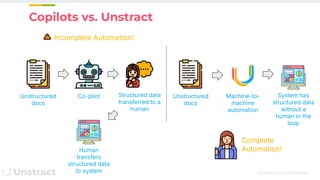
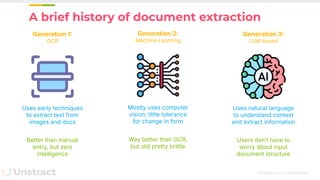

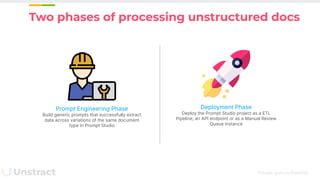


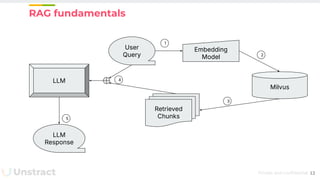


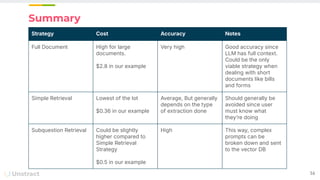


The document discusses challenges and advancements in extracting structured data from unstructured documents, highlighting the role of large language models (LLMs) in addressing these issues. It introduces Unstract, a startup focused on automated data extraction, and compares various approaches to processing documents, including the use of vector databases. Additionally, it explores the evolution of document extraction technologies, from OCR to LLM-based methods, emphasizing the importance of prompt engineering and the potential for future improvements.


![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)























![[DSC Europe 23] Djordje Grozdic - Transforming Business Process Automation wi...](https://cdn.slidesharecdn.com/ss_thumbnails/djordjegrozdic-transformingbusinessprocessautomationwithretrieval-augmentedgenerationandllms-231129100159-8fe5bf2b-thumbnail.jpg?width=640&height=640&fit=bounds)








































