Download as PDF, PPTX



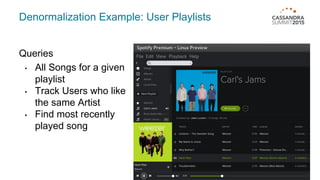





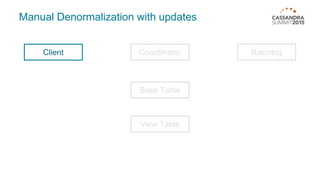


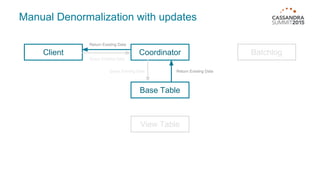

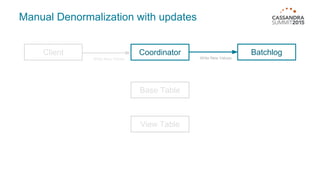
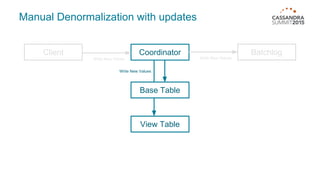


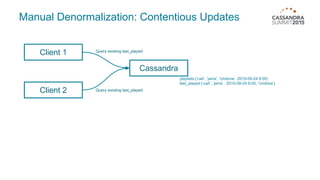
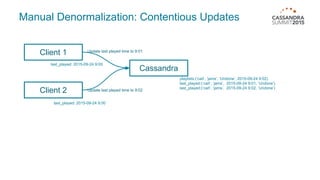






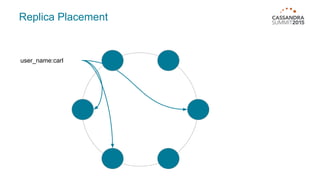
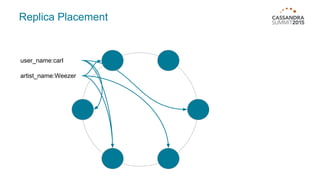



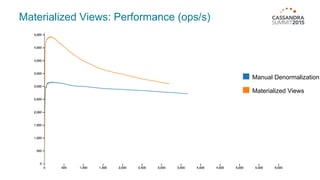
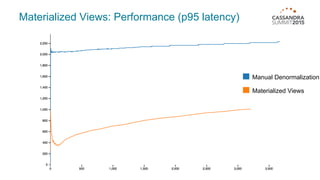

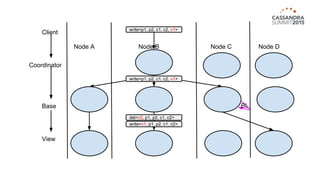






Materialized views in Cassandra enable automated, server-side denormalization of data, enhancing read performance while managing write penalties. They simplify application code by eliminating the need for read-before-write and ensuring data consistency through built-in synchronization mechanisms. However, they also introduce complexities and limitations, particularly regarding updates and potential data loss if base table replicas are compromised.


![Data Structures - Lecture 8 [Sorting Algorithms]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-8sortingalgorithms-150205105023-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
































































