Download to read offline




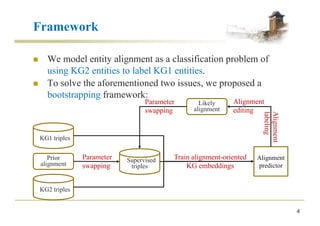

![Alignment-Oriented Embedding
n Translational score function: ! " = $ + & − ( )
)
.
n Margin-based ranking loss:
*+ = ∑-∈/0 ∑-1∈/2
3[5 + ! " − ! "6
]8
n Limited loss function:
*9 = ∑-∈/0[! " − 5:]8+ ∑-1∈/3[5) − ! "6
]8
6
! "6
− ! " > 5
not controlled not controlled
! "6
≥ 5) ! " ≤ 5:
! "6 − ! " ≥ 5) − 5:](https://image.slidesharecdn.com/2018-07-19zqsunijcaibootea-180724102049/85/Bootstrapping-Entity-Alignment-with-Knowledge-Graph-Embedding-6-320.jpg)
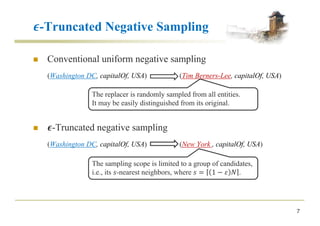



![Experiments
11
n Comparative Approaches
¡ MTransE [ijcai 2017] learns a linear transformation between KGs.
¡ IPTransE [ijcai 2017] is an iterative method for entity alignment.
¡ JAPE [iswc 2017] combines relation and attribute embeddings for
entity alignment.
n Metrics
¡ Hits@k : the percentage of correct alignment ranked at top k
¡ MRR: the average of the reciprocal ranks of results](https://image.slidesharecdn.com/2018-07-19zqsunijcaibootea-180724102049/85/Bootstrapping-Entity-Alignment-with-Knowledge-Graph-Embedding-11-320.jpg)




This document presents BootEA, a framework for bootstrapping entity alignment across knowledge graphs using knowledge graph embedding. BootEA models entity alignment as a classification task and trains alignment-oriented knowledge graph embeddings using an iterative process of parameter swapping, alignment prediction, labeling likely alignments, and editing alignments. Experimental results on five datasets show that BootEA significantly outperforms three state-of-the-art embedding-based entity alignment methods, particularly on sparse data.
![250310_JH_Seminar[Translating Embeddings for Modeling Multi-relational Data]....](https://cdn.slidesharecdn.com/ss_thumbnails/250310jhseminar-250310102407-96b769ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![241125_HW_LabSeminar[Knowledge Graph].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/241125hwlabseminar-241125095541-16efdd37-thumbnail.jpg?width=640&height=640&fit=bounds)













































