Why NoSQL? Howto use it?
Kyungpyo Park | Solutions Architect
2.
강연 중 질문하는방법 AWS Builders
Go to Webinar “Questions” 창에 자신이 질문한
내역이 표시됩니다. 기본적으로 모든 질문은
공개로 답변 됩니다만 본인만 답변을 받고 싶으면
(비공개)라고 하고 질문해 주시면 됩니다.
본 컨텐츠는 고객의 편의를 위해 AWS 서비스 설명을 위해 온라인 세미나용으로 별도로 제작, 제공된 것입니다. 만약 AWS
사이트와 컨텐츠 상에서 차이나 불일치가 있을 경우, AWS 사이트(aws.amazon.com)가 우선합니다. 또한 AWS 사이트
상에서 한글 번역문과 영어 원문에 차이나 불일치가 있을 경우(번역의 지체로 인한 경우 등 포함), 영어 원문이 우선합니다.
AWS는 본 컨텐츠에 포함되거나 컨텐츠를 통하여 고객에게 제공된 일체의 정보, 콘텐츠, 자료, 제품(소프트웨어 포함) 또는 서비스를 이용함으로 인하여 발생하는 여하한 종류의 손해에
대하여 어떠한 책임도 지지 아니하며, 이는 직접 손해, 간접 손해, 부수적 손해, 징벌적 손해 및 결과적 손해를 포함하되 이에 한정되지 아니합니다.
고지 사항(Disclaimer)
주요 주제
SQL ?NoSQL ?
SQL은 현재까지도 많이 활용되는 Database의 종류입니다. 대부분의 초기
개발은 RDBMS에서 시작되는 경우가 많습니다. SQL과 NoSQL은 각각의
특징이 있으며, 최신 Application에서는 “혼용”하여 활용 하고 있습니다.
SQL vs NoSQL
SQL & NoSQL
5.
주요 주제
RDBMS
“컬럼“으로 형식화되어있는 “테이블“을 기본으로, 실제 데이터를 의미하는
“레코드“를 조작하여 업무를 수행합니다. 테이블은 다른 테이블과 “관계“를
맺을 수가 있으며, 이 관계를 이용하여 쿼리를 수행하게 됩니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
ACC_ID BAL USER_ID
03-240-W 1,000,000 USER001
03-241-X -700,000 USER001
03-242-Y 350,000 USER001
05-512-Z 0 USER001
테이블
테이블
컬럼
레코드
관계
6.
주요 주제
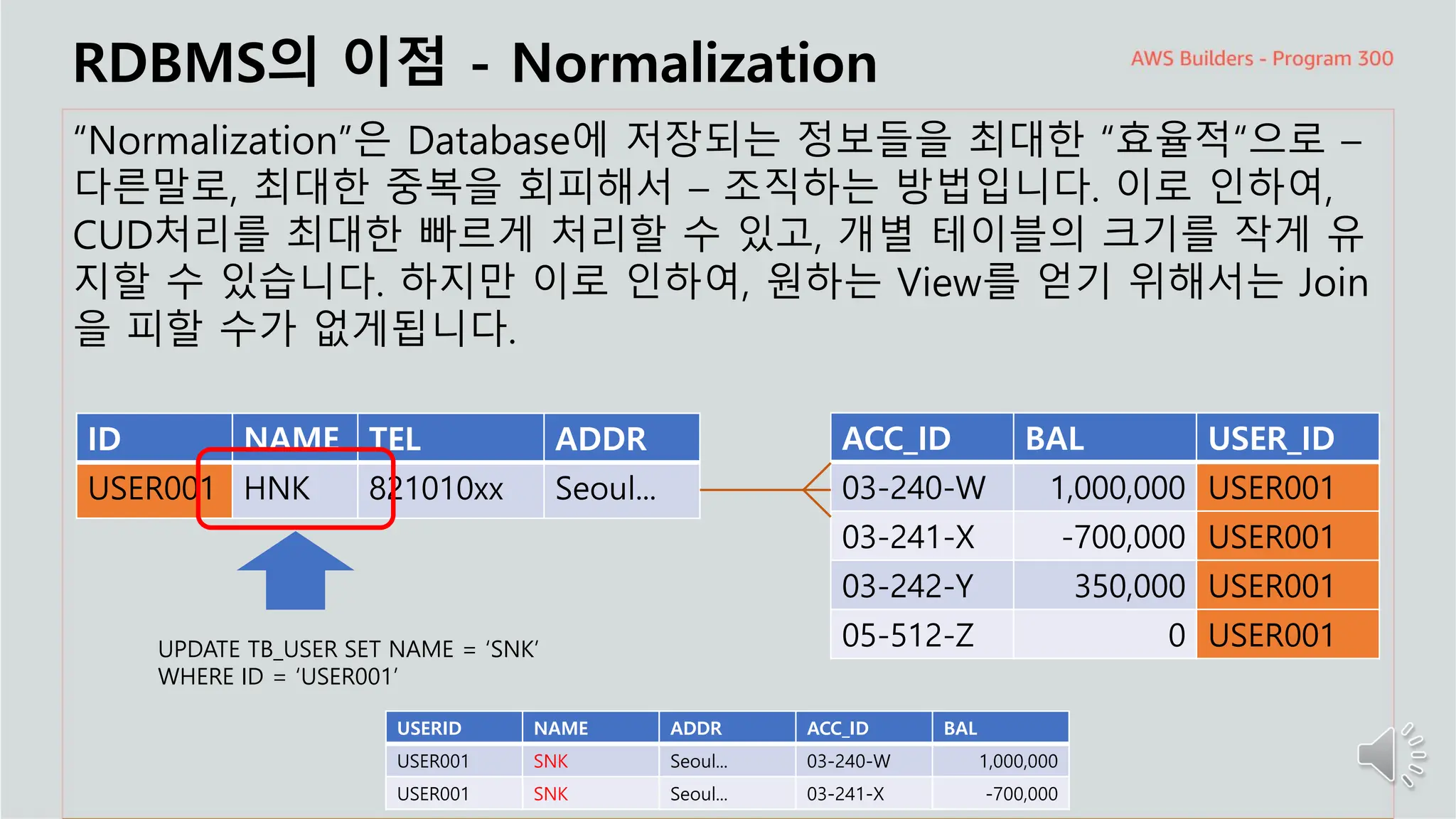
RDBMS의 이점- Normalization
“Normalization”은 Database에 저장되는 정보들을 최대한 “효율적“으로 –
다른말로, 최대한 중복을 회피해서 – 조직하는 방법입니다. 이로 인하여,
CUD처리를 최대한 빠르게 처리할 수 있고, 개별 테이블의 크기를 작게 유
지할 수 있습니다. 하지만 이로 인하여, 원하는 View를 얻기 위해서는 Join
을 피할 수가 없게됩니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
ACC_ID BAL USER_ID
03-240-W 1,000,000 USER001
03-241-X -700,000 USER001
03-242-Y 350,000 USER001
05-512-Z 0 USER001
UPDATE TB_USER SET NAME = ‘SNK’
WHERE ID = ‘USER001’
USERID NAME ADDR ACC_ID BAL
USER001 SNK Seoul... 03-240-W 1,000,000
USER001 SNK Seoul... 03-241-X -700,000
7.
주요 주제
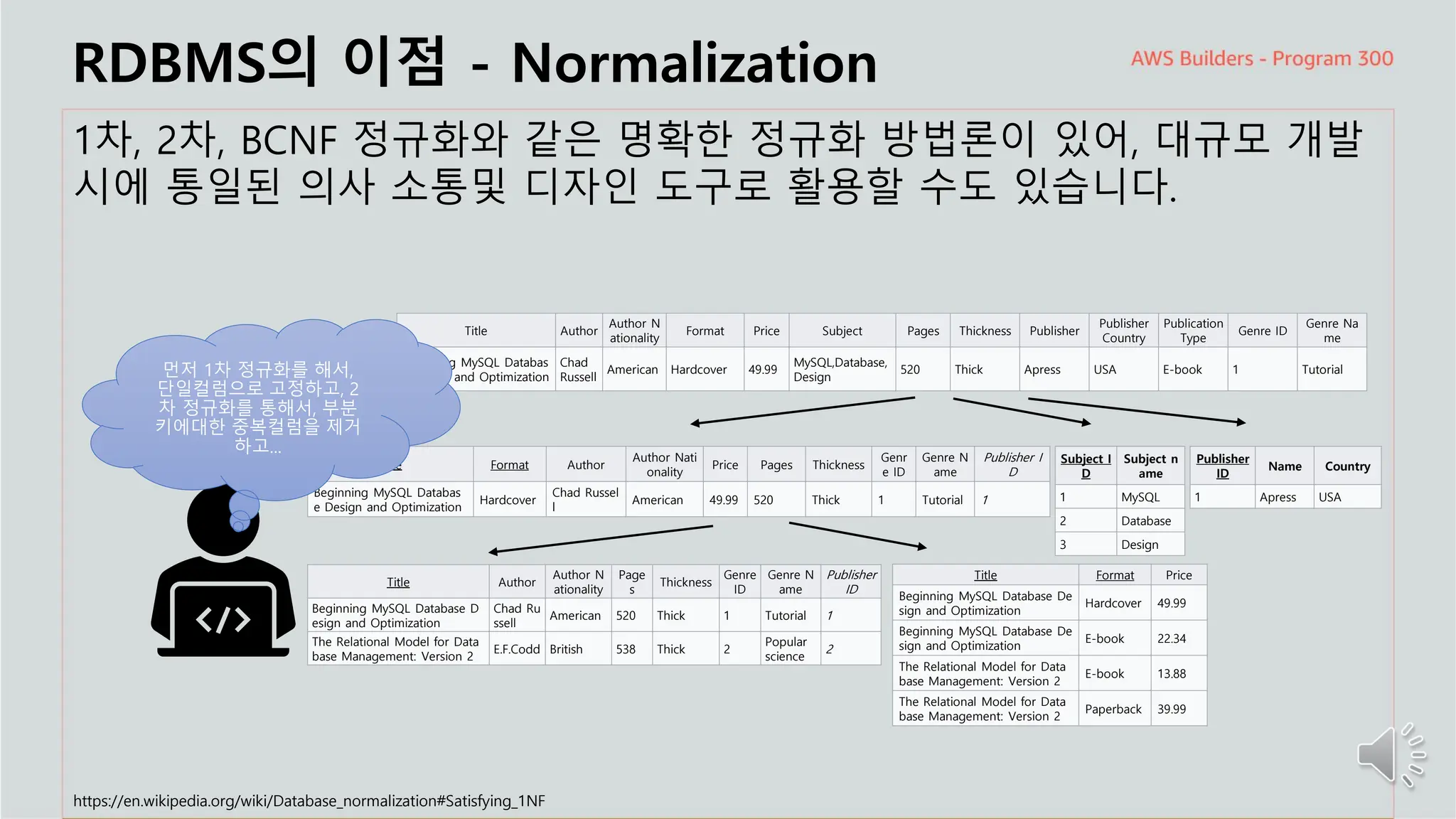
RDBMS의 이점- Normalization
1차, 2차, BCNF 정규화와 같은 명확한 정규화 방법론이 있어, 대규모 개발
시에 통일된 의사 소통및 디자인 도구로 활용할 수도 있습니다.
https://en.wikipedia.org/wiki/Database_normalization#Satisfying_1NF
Title Author
Author N
ationality
Format Price Subject Pages Thickness Publisher
Publisher
Country
Publication
Type
Genre ID
Genre Na
me
Beginning MySQL Databas
e Design and Optimization
Chad
Russell
American Hardcover 49.99
MySQL,Database,
Design
520 Thick Apress USA E-book 1 Tutorial
Title Format Author
Author Nati
onality
Price Pages Thickness
Genr
e ID
Genre N
ame
Publisher I
D
Beginning MySQL Databas
e Design and Optimization
Hardcover
Chad Russel
l
American 49.99 520 Thick 1 Tutorial 1
Subject I
D
Subject n
ame
1 MySQL
2 Database
3 Design
Publisher
ID
Name Country
1 Apress USA
Title Author
Author N
ationality
Page
s
Thickness
Genre
ID
Genre N
ame
Publisher
ID
Beginning MySQL Database D
esign and Optimization
Chad Ru
ssell
American 520 Thick 1 Tutorial 1
The Relational Model for Data
base Management: Version 2
E.F.Codd British 538 Thick 2
Popular
science
2
Title Format Price
Beginning MySQL Database De
sign and Optimization
Hardcover 49.99
Beginning MySQL Database De
sign and Optimization
E-book 22.34
The Relational Model for Data
base Management: Version 2
E-book 13.88
The Relational Model for Data
base Management: Version 2
Paperback 39.99
먼저 1차 정규화를 해서,
단일컬럼으로 고정하고, 2
차 정규화를 통해서, 부분
키에대한 중복컬럼을 제거
하고...
8.
주요 주제
RDBMS의 이점- 인덱스
자주 활용되는 필터 조건에 대하여, 사전에 인덱스를 생성해 놓으면, 자동
적으로 데이터가 변경됨에 따라, 인덱스도 갱신이 진행되고 이를 활용하여
빠른 검색이 보장됩니다.
인덱스를 구성해서
Tel, Resid에 대한 Filter 성
능을 높여야겠다.
Addr은 자주쓰지 않으니,
Composite index로 만들
되 뒤로...
ID NAME TEL ADDR RESID
USER001 HNK 821010xx Seoul... 951201-xx
9.
주요 주제
RDBMS의 이점
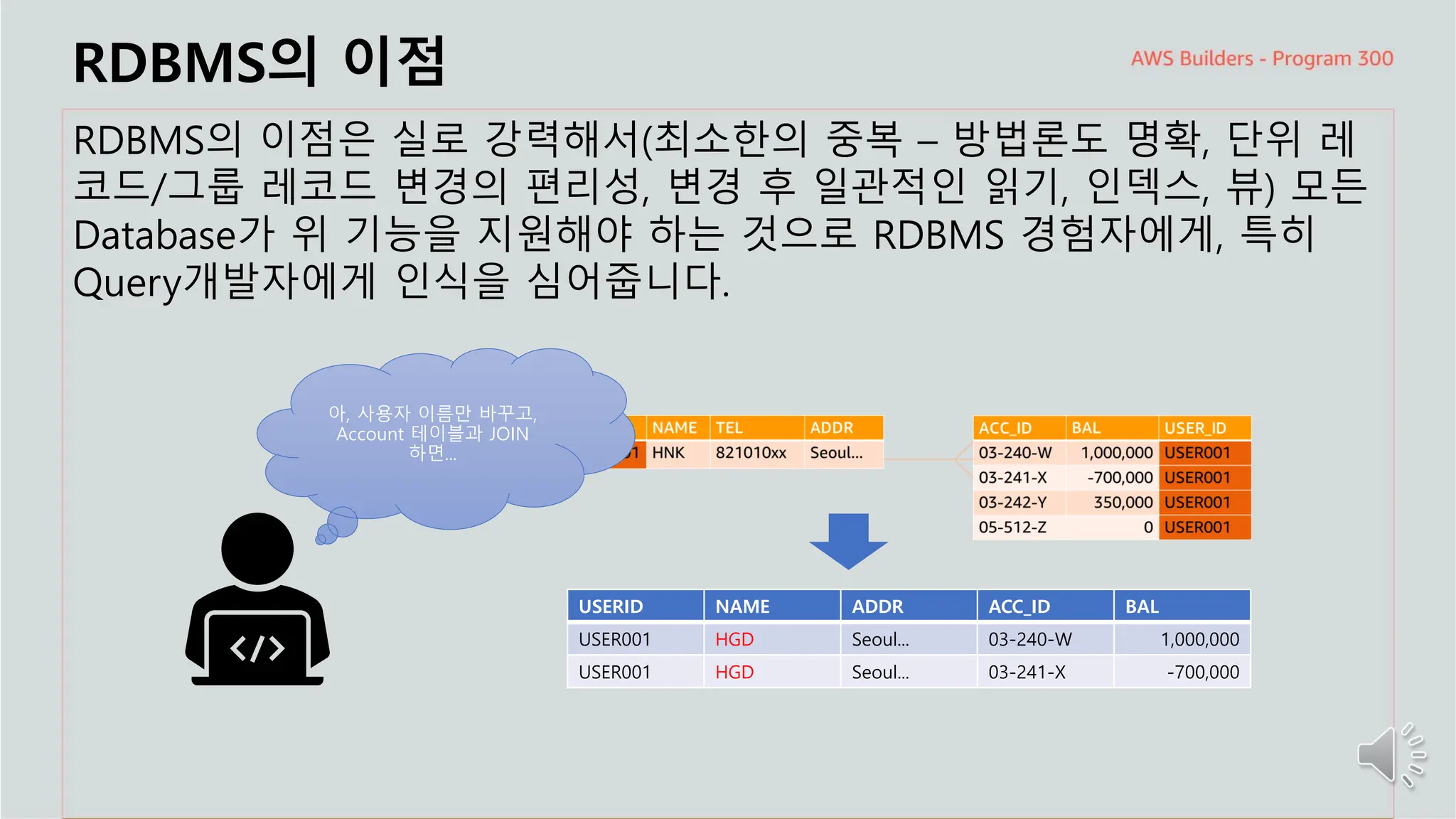
RDBMS의이점은 실로 강력해서(최소한의 중복 – 방법론도 명확, 단위 레
코드/그룹 레코드 변경의 편리성, 변경 후 일관적인 읽기, 인덱스, 뷰) 모든
Database가 위 기능을 지원해야 하는 것으로 RDBMS 경험자에게, 특히
Query개발자에게 인식을 심어줍니다.
아, 사용자 이름만 바꾸고,
Account 테이블과 JOIN
하면...
USERID NAME ADDR ACC_ID BAL
USER001 HGD Seoul... 03-240-W 1,000,000
USER001 HGD Seoul... 03-241-X -700,000
10.
주요 주제
Why NoSQL?
ACID, MVCC, Normalized Table 등 RDBMS가 제공하는 이점보다, 다른 형
태(최근 아키텍처)의 요구사항이 커질 경우, RDBMS를 이용한 아키텍처가
도리어 부담으로 작용할 수 있습니다.
으아아!
넘처나는 데이터를 어떻게
받지?
Sharding? NoSQL?
• 대규모 데이터 처리
• 시계열 처리
• 그래프 처리
• 개발자들의 Non-Deterministic schema
• Document 처리
11.
주요 주제
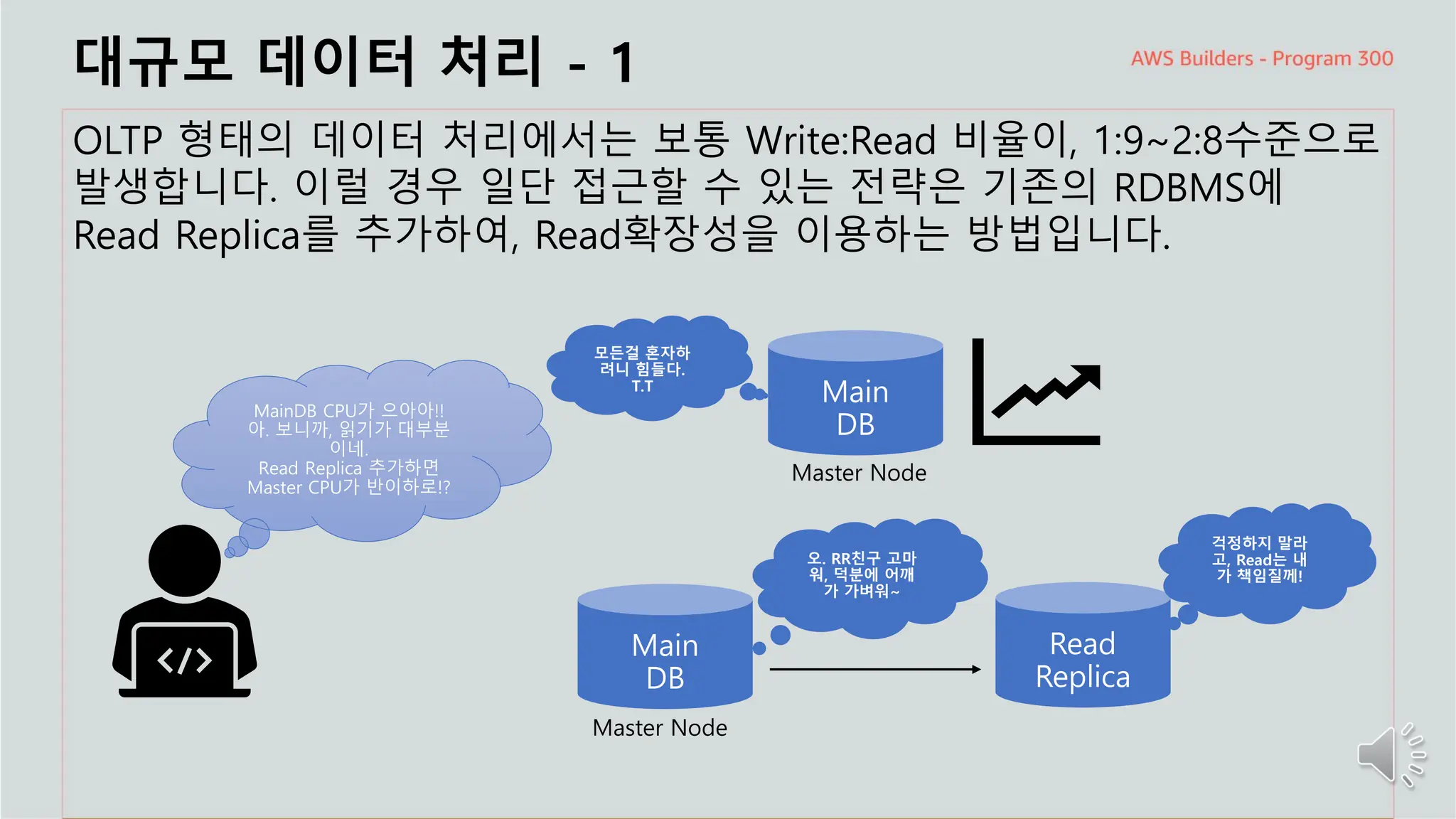
대규모 데이터처리 - 1
OLTP 형태의 데이터 처리에서는 보통 Write:Read 비율이, 1:9~2:8수준으로
발생합니다. 이럴 경우 일단 접근할 수 있는 전략은 기존의 RDBMS에
Read Replica를 추가하여, Read확장성을 이용하는 방법입니다.
MainDB CPU가 으아아!!
아. 보니까, 읽기가 대부분
이네.
Read Replica 추가하면
Master CPU가 반이하로!?
Master Node
Master Node
12.
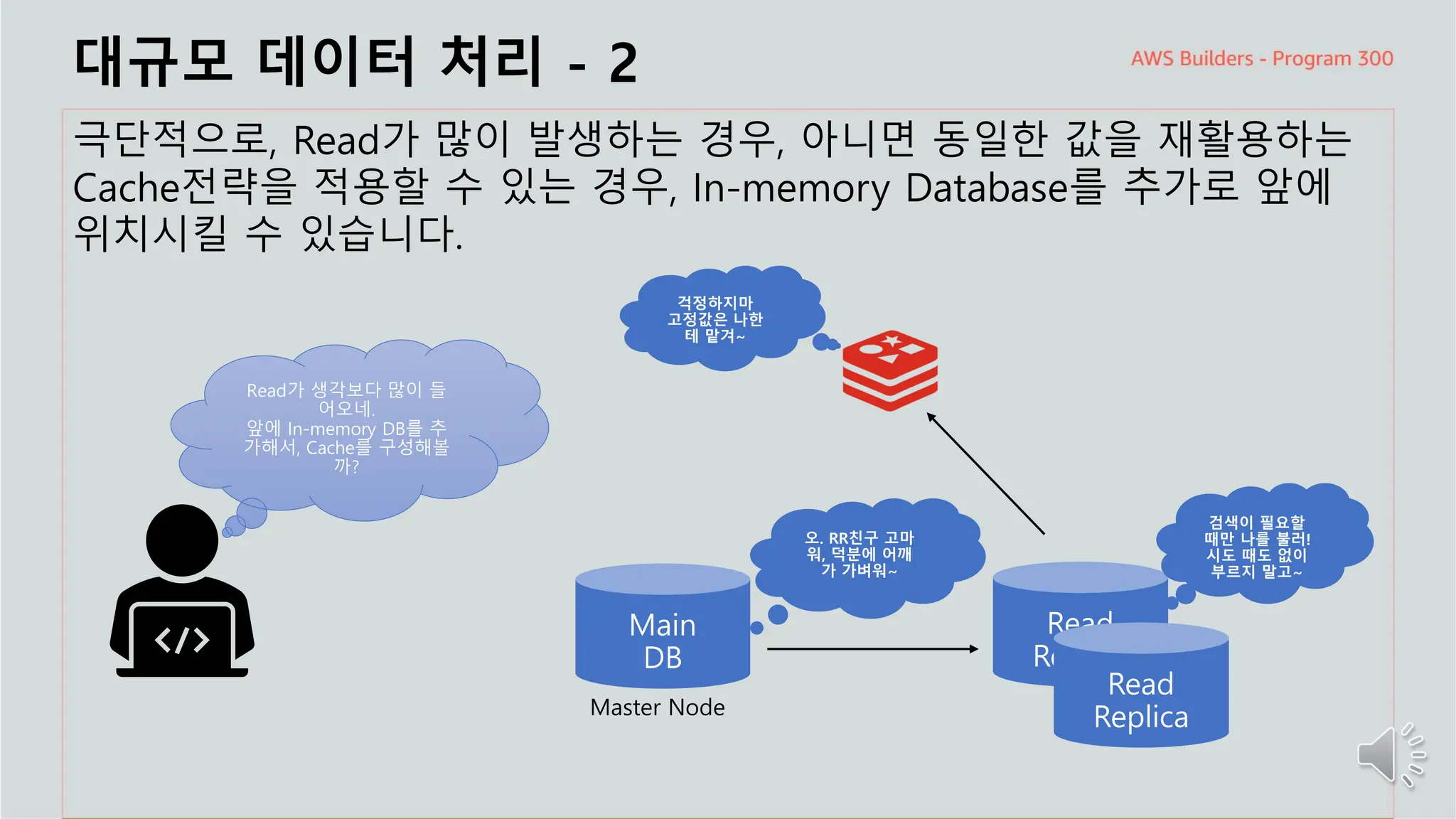
주요 주제
대규모 데이터처리 - 2
극단적으로, Read가 많이 발생하는 경우, 아니면 동일한 값을 재활용하는
Cache전략을 적용할 수 있는 경우, In-memory Database를 추가로 앞에
위치시킬 수 있습니다.
Read가 생각보다 많이 들
어오네.
앞에 In-memory DB를 추
가해서, Cache를 구성해볼
까?
Master Node
13.
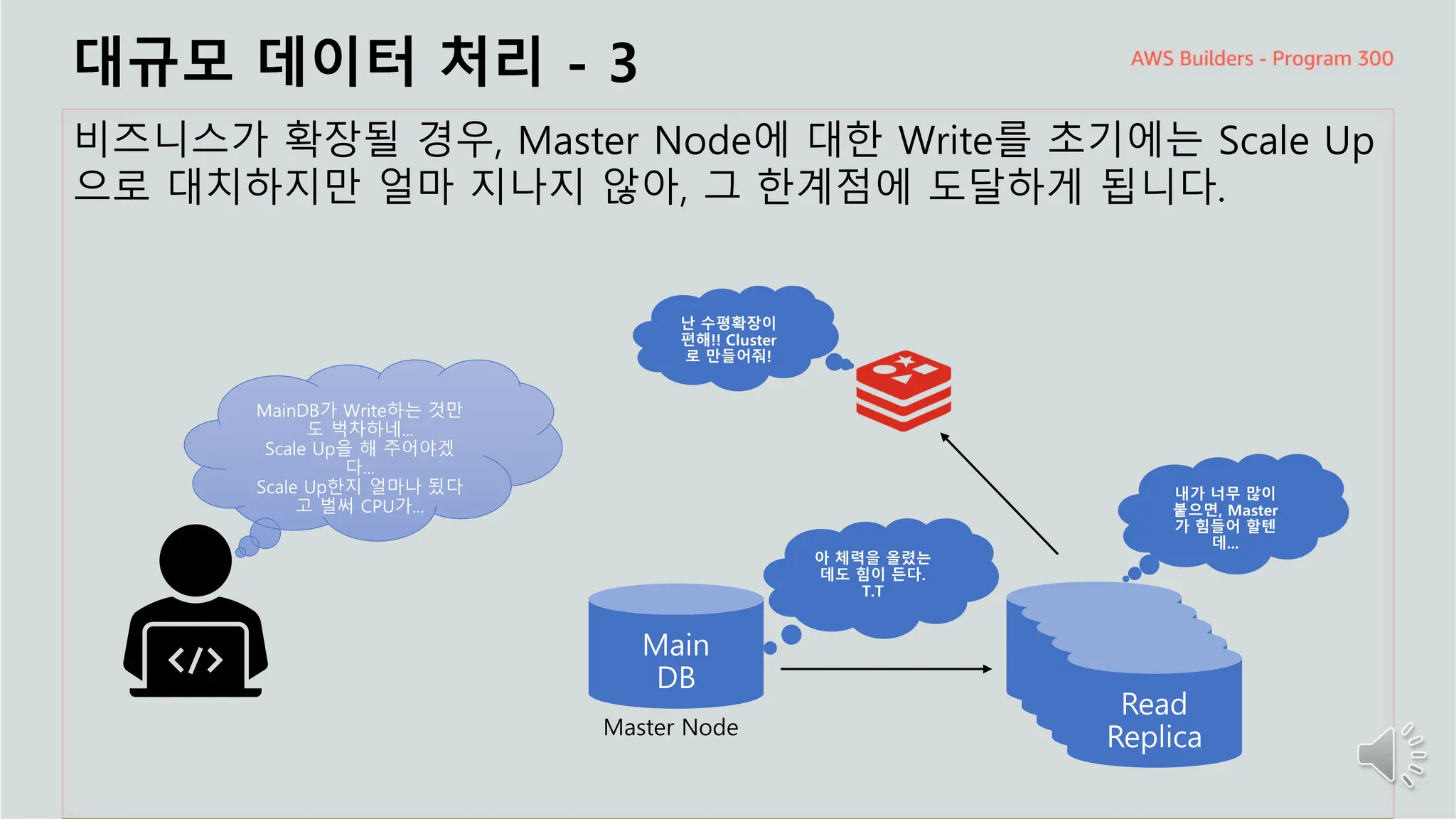
주요 주제
대규모 데이터처리 - 3
비즈니스가 확장될 경우, Master Node에 대한 Write를 초기에는 Scale Up
으로 대치하지만 얼마 지나지 않아, 그 한계점에 도달하게 됩니다.
MainDB가 Write하는 것만
도 벅차하네...
Scale Up을 해 주어야겠
다...
Scale Up한지 얼마나 됬다
고 벌써 CPU가...
Master Node
14.
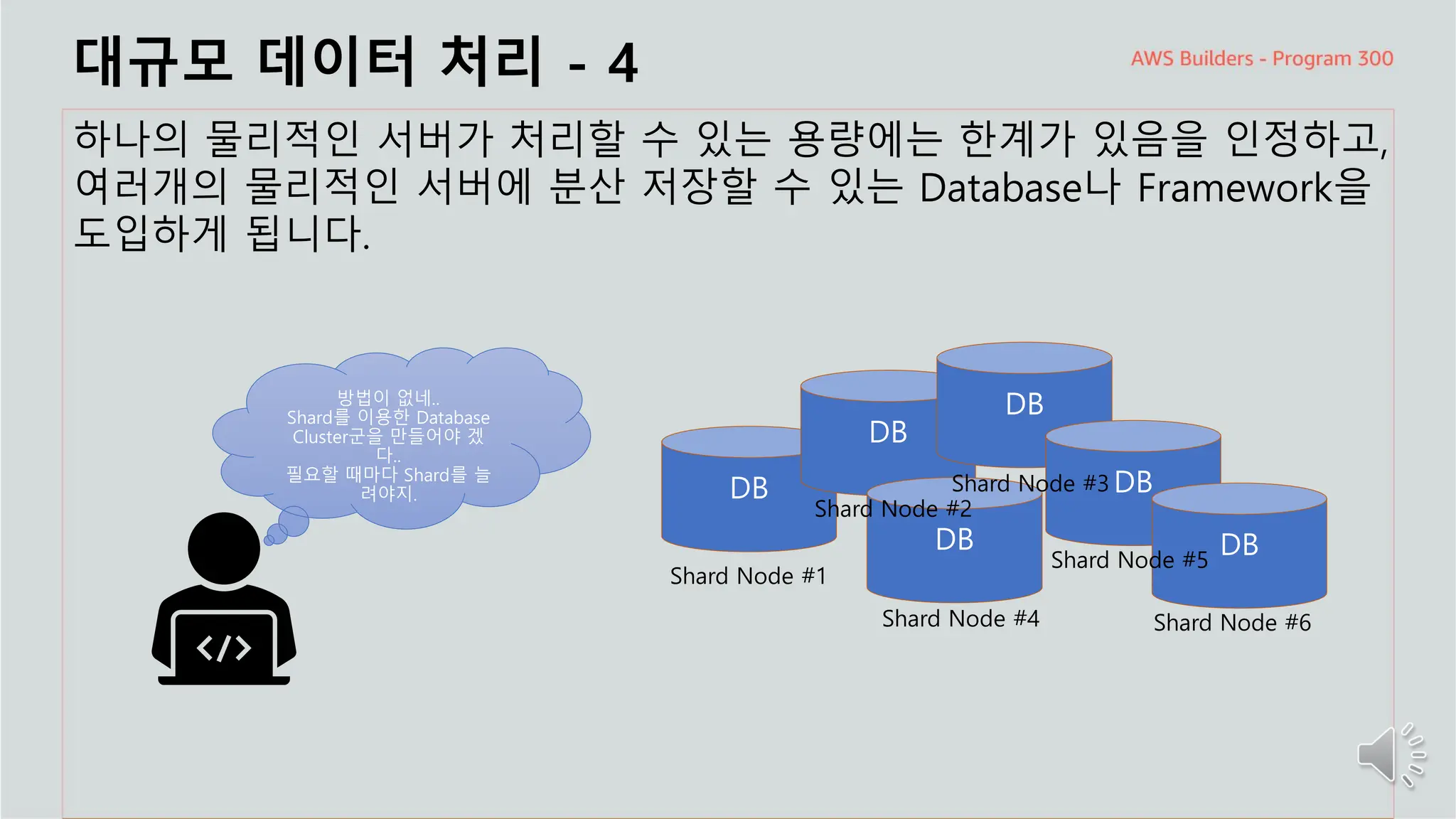
주요 주제
대규모 데이터처리 - 4
하나의 물리적인 서버가 처리할 수 있는 용량에는 한계가 있음을 인정하고,
여러개의 물리적인 서버에 분산 저장할 수 있는 Database나 Framework을
도입하게 됩니다.
방법이 없네..
Shard를 이용한 Database
Cluster군을 만들어야 겠
다..
필요할 때마다 Shard를 늘
려야지.
Shard Node #1
Shard Node #3
Shard Node #2
Shard Node #5
Shard Node #4 Shard Node #6
15.
주요 주제
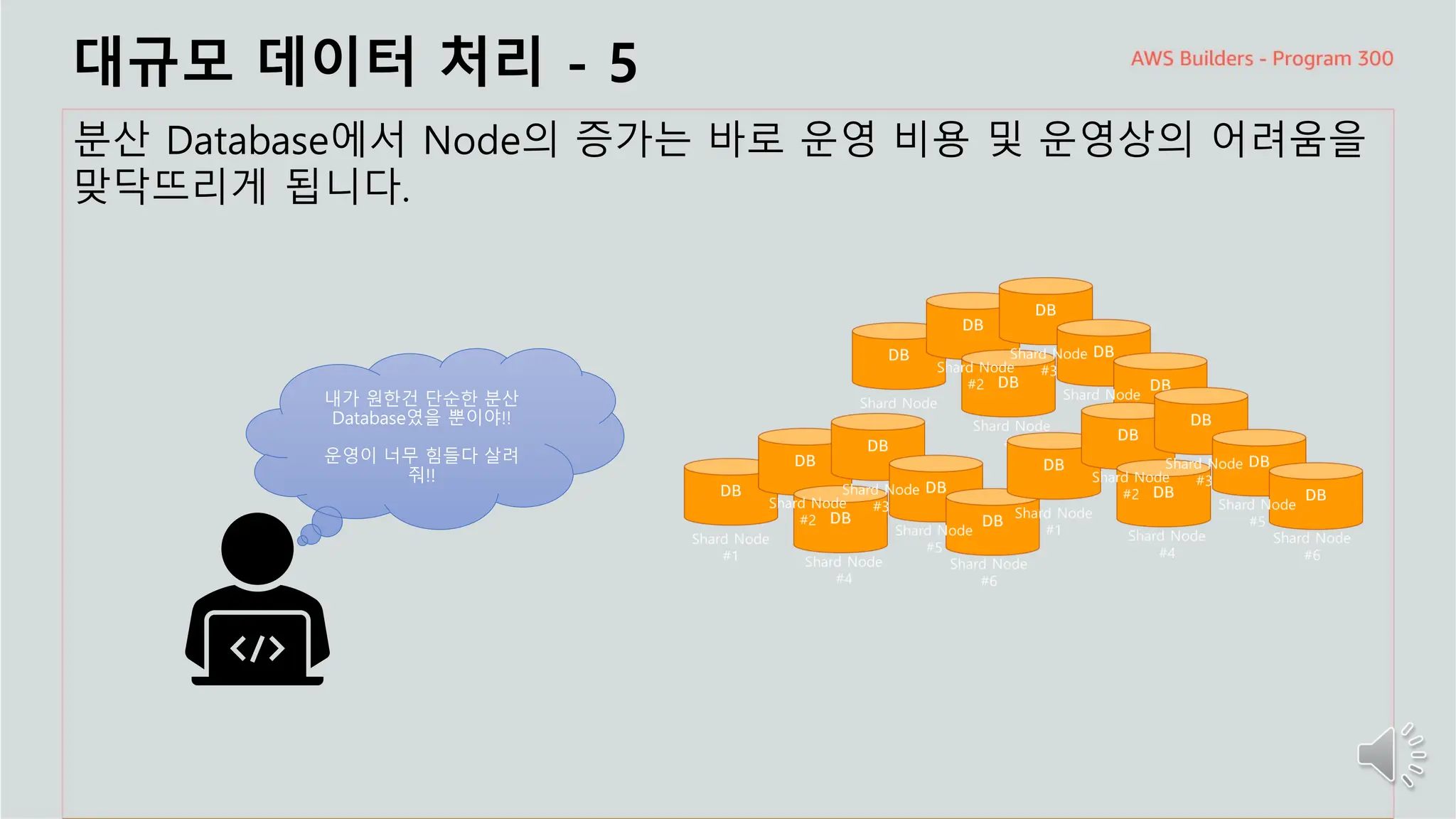
대규모 데이터처리 - 5
분산 Database에서 Node의 증가는 바로 운영 비용 및 운영상의 어려움을
맞닥뜨리게 됩니다.
내가 원한건 단순한 분산
Database였을 뿐이야!!
운영이 너무 힘들다 살려
줘!!
16.
주요 주제
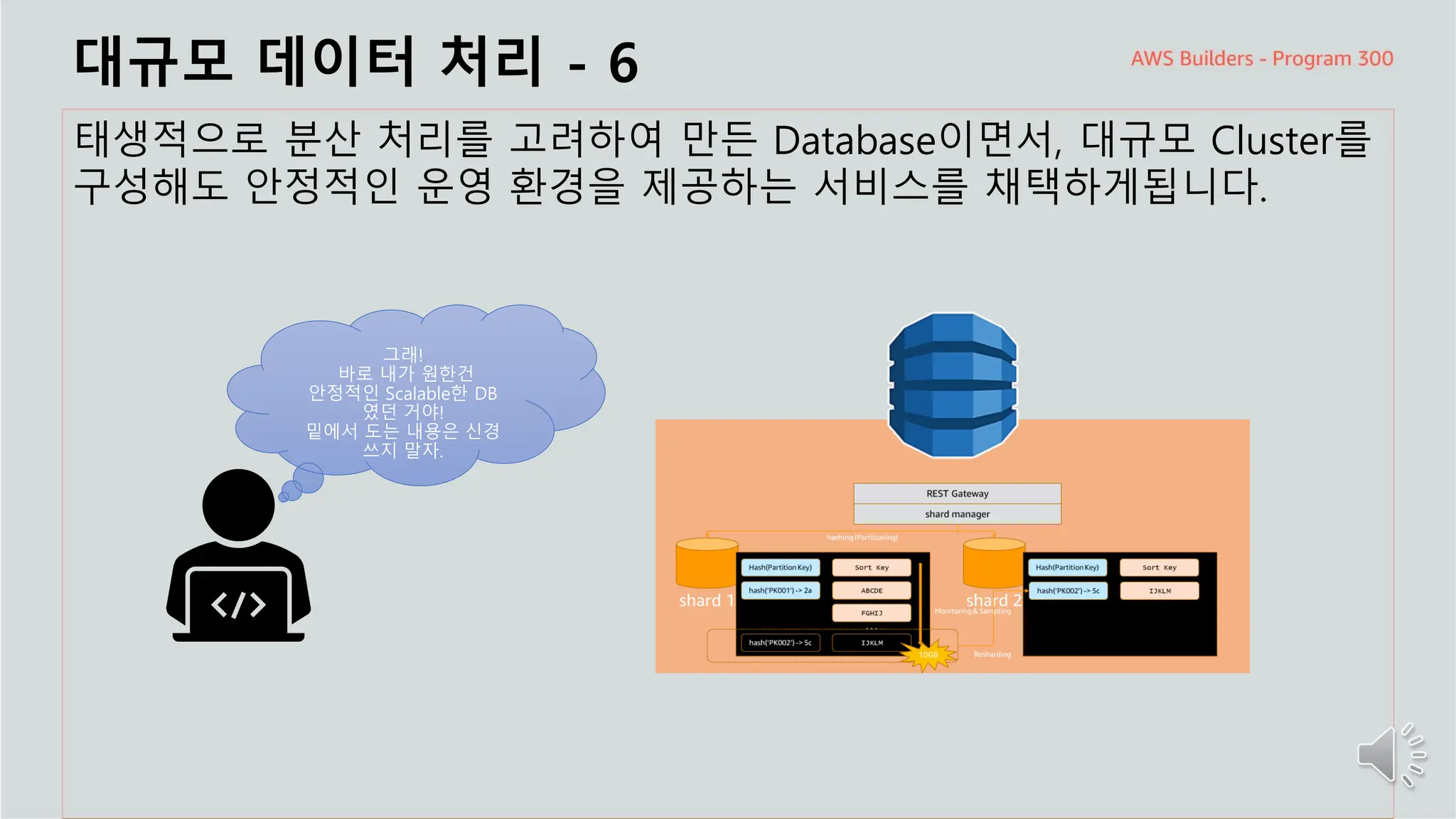
대규모 데이터처리 - 6
태생적으로 분산 처리를 고려하여 만든 Database이면서, 대규모 Cluster를
구성해도 안정적인 운영 환경을 제공하는 서비스를 채택하게됩니다.
그래!
바로 내가 원한건
안정적인 Scalable한 DB
였던 거야!
밑에서 도는 내용은 신경
쓰지 말자.
주요 주제
Key ValueDatabase
Redis/Memcached/DynamoDB로 분류되는, Key-Value Database는 기본적
으로 Key”만”을 이용하여, 처리하도록 구성됩니다. 이는 기본적으로,
RDBMS에서 지원되는 기능을 직접 “키”를 이용하여 대치하여야 합니다.
인덱스가 없네 ?
Key Value에서는 어떻게
Index와 유사한 기능을 구
현하지 ?
19.
주요 주제
Index Key설계 - 1
Key-Value 구조에서는 보통 다양한 Key를 구성하여, 인덱스 효과를 생성할
수 있습니다. 즉, 기준이 되는 Item Record를 하나 구성하면서, Filter에 활
용될 Key를 추가할 수 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
인덱스를 생성해서
조회속도를 업!
인덱스용 키를 별도로
생성해서
조회
USER#MOB#010-1234-5678 USER#USER001
USER#MOB#010-5678-1234 USER#USER002
20.
주요 주제
Index Key설계 - 2
실제 상황에서는 다양한 Filter조건을 이용하여 Record 검색을 수행합니다.
이럴 경우, Index용 Key를 AND 조건의 경우 모두 Concatenate하여 대리
수행할 수 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
인덱스를 생성해서
조회속도를 업!
서울 사는 “일동"이
를 어떻게 찾을까?
USER#HONGILDONG#Seoul, Korea USER#USER001
USER#KIMCHEONSOO#Busan, Korea USER#USER002
21.
주요 주제
Index Key설계 - 3
만약, Unique가 아닌 값을, Filter조건을 위하여, Key로 생성하였을 경우에
는, Database에서 제공하는 솔루션을 활용하여야 합니다. 예를 들어, Redis
의 List를 이용하거나, DDB의 Index를 이용합니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER955 HONGILDONG 160424-3654321 010-5678-1234 Seoul, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#HONGILDONG#Seoul, Korea [ USER#USER001, USER#USER955 ]
USER#USER955
{ “name” : “HONGILDONG”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Seoul, Korea” }
Composite 인덱스
를 생성해서 조회
속도를 업!
아 주소가 비슷한 동
명이인이 있다니!!!
22.
주요 주제
Index Key설계 - 4
OR 조건 검색이 필요할 경우에는, OR 전체를 묶는 새로운 키를 생성할 수
도 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#HONGILDONG#Seoul, Korea [ USER#USER001, USER#USER955 ]
USER#HONGILDONG#010-1234-4578 [ USER#USER001 ]
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-
3654321”, “mob”:”010-5678-1234”, “addr” : “Busan,
Korea” }
아 주소가 비슷한 동
명이인이 있다니!!!
SELECT ITEM_ID, RES_ID
FROM TB_USER
WHERE NAME = ‘HONGILDONG’ AND
( ADDR = ‘SEOUL, Korea’ OR MOB = ‘010-5678-1234’ )
23.
주요 주제
Aggregation
Key만 제공되는Database에서는 Aggregation이 기본적으로 제공되지 않
습니다. 하지만, 필요시에는 Attribute를 추가하거나, 별도의 “통계KEY”를
구성하여
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#SEOUL#USER_COUNT 3
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
서울 사는 유저들에 대해서 실
시간 통계를 구하고 싶은데 어
떻게 하지 ?
사용자가 추가될 때마다, +1을
해주어야 겠다.
SELECT ADDR, COUNT(1) as USER_COUNT
FROM TB_USER
WHERE ADDR = ‘Seoul, Korea’
24.
주요 주제
Record &Column conversion
Value에서, 다양한 형태의 자료구조를 제공하는 Database도 있지만, 기본
적으로, String은 대부분의 Key Value Database에서 모두 제공합니다.
String Value의 경우, JSON Type같이 Column Name(Attribute)가 포함될
경우, Record / Column의 경계가 매우 모호해지며, 다양한 응용이 생깁니
다.
ElastiCache
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER001#SECRET { “credential”:”3bac-de3c-....”, “secretToekn”: “abcdef” }
아 나는 Credential 정보를 접근
하게 하고 싶지 않아, “레코드"
를 분리해야 겠군!
25.
주요 주제
단순한 구조에서다양한 활용
Key Value 구조는 직관적이기 때문에, 다양한 형태로 “조합”을 할 수 있습
니다. 아까 보여드린 예시도 Key Value구조의 특성을 이용한 한 예시일 뿐
입니다.
Index Record 생성
Value concatenation을 이용한 Composite Index 생성
통계 Record를 추가하고, Event 시점에 Update
주요 주제
KV Database개별적인 특성
Redis의 경우에는, 다양한 형태의 Value Type을 제공합니다. 또한
Operation이 다양하기 때문에, Range 검색에 용이합니다. DynamoDB는
인덱스 생성을 자동으로 지원해 줄 수 있습니다. 이를 이용하여 다양한
Indexing방법을 활용할 수 있습니다.
REDIS는 다양한 Value Type 제공
DynamoDB는 Column 형태의 Value 제공
DynamoDB는 다양한 Indexing 기능 제공
DynamoDB는 기본적으로 Partitioning기능 제공
28.
주요 주제
Redis에서 제공하는Value Type
가장 기본적인 단일값 형태와 함께, Multi Value에 대한 지원을 위하여,
HashSet, List, Set등을 지원합니다. 이를 사용하면, 기본 키에 대한 Multi
Value처리, Unique 값 처리, 기본키이외에 속성형태의 추가 키를 부여하여,
값을 관리할 수 있게 합니다. (더 다양한 형태의 Value Type이 있습니다.)
LIST – Multi Value를 저장할 수 있는 기본 기능
SET – Multi Value저장 시 Unique값을 보장
HASH – 추가 키(속성)에 Value를 추가
ETC
29.
주요 주제
Partitioning
Redis/DynamoDB 모두Sharding(Clustering)기능을 제공합니다. Redis는
사용자가 요청할 경우 Node 추가 시, Slot을 조정하여 이를 해결하고,
DynamoDB는 WCU/RCU와 용량을 판단하여, 자동 조정하게 되어 있습니
다.
[REDIS] [DynamoDB]
주요 주제
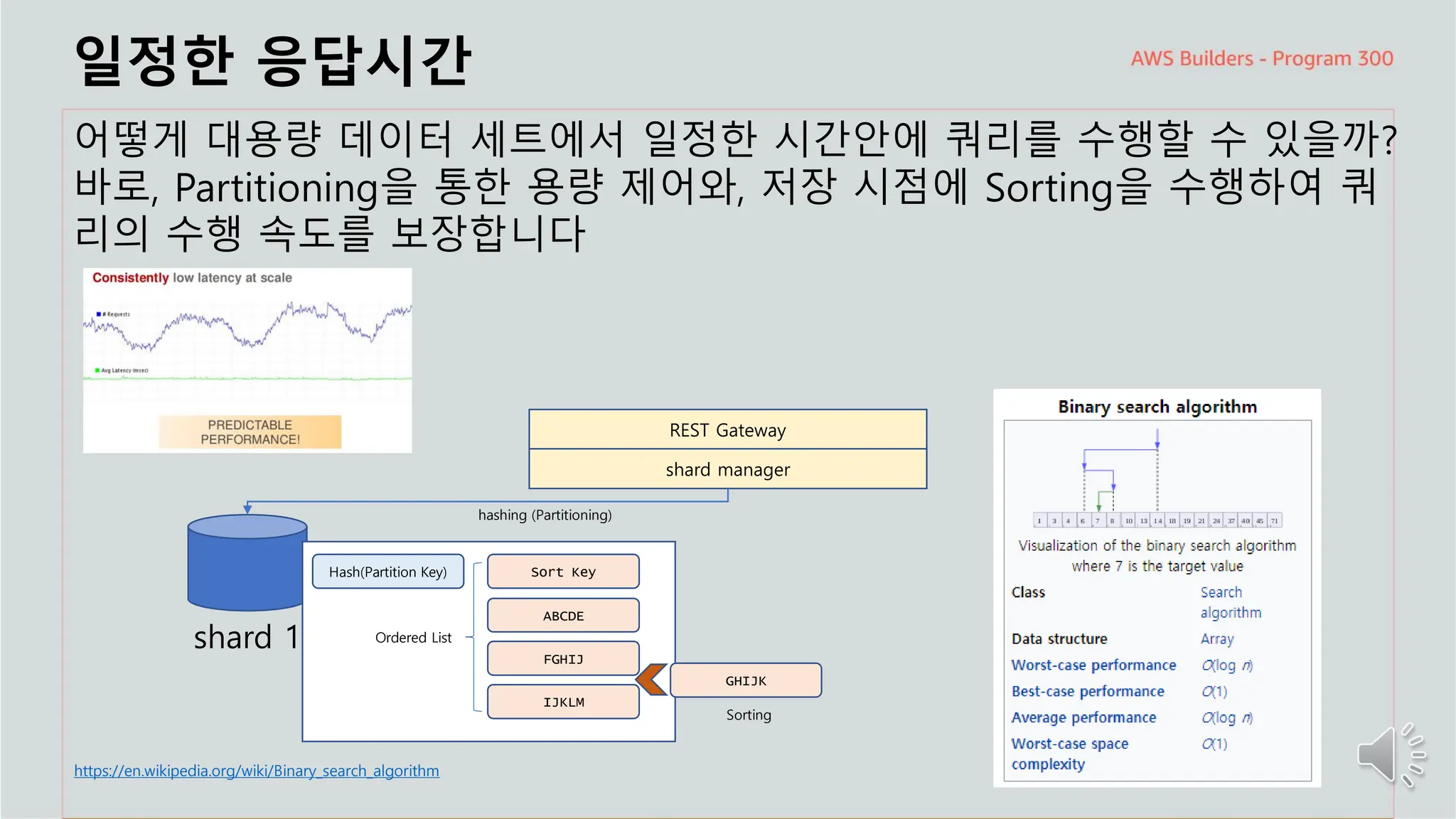
일정한 응답시간
어떻게대용량 데이터 세트에서 일정한 시간안에 쿼리를 수행할 수 있을까?
바로, Partitioning을 통한 용량 제어와, 저장 시점에 Sorting을 수행하여 쿼
리의 수행 속도를 보장합니다
Hash(Partition Key)
REST Gateway
shard manager
Sort Key
shard 1
hashing (Partitioning)
ABCDE
FGHIJ
IJKLM
GHIJK
Sorting
Ordered List
https://en.wikipedia.org/wiki/Binary_search_algorithm
32.
주요 주제
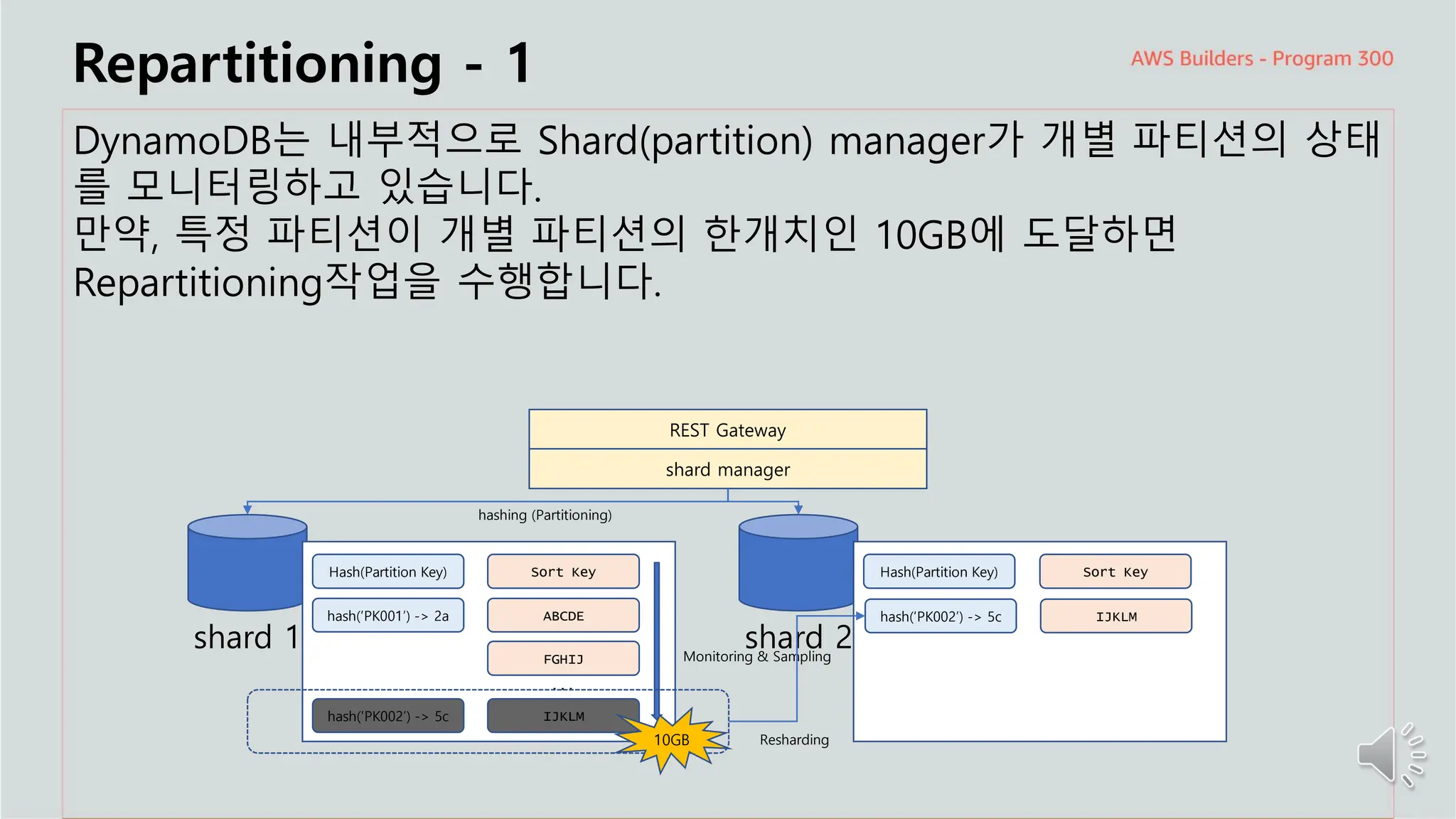
Repartitioning -1
DynamoDB는 내부적으로 Shard(partition) manager가 개별 파티션의 상태
를 모니터링하고 있습니다.
만약, 특정 파티션이 개별 파티션의 한개치인 10GB에 도달하면
Repartitioning작업을 수행합니다.
Hash(Partition Key)
REST Gateway
shard manager
Sort Key
shard 1
hashing (Partitioning)
Hash(Partition Key) Sort Key
shard 2
ABCDE
FGHIJ
IJKLM
hash(‘PK001’) -> 2a
hash(‘PK002’) -> 5c
...
Monitoring & Sampling
10GB
IJKLM
hash(‘PK002’) -> 5c
Resharding
33.
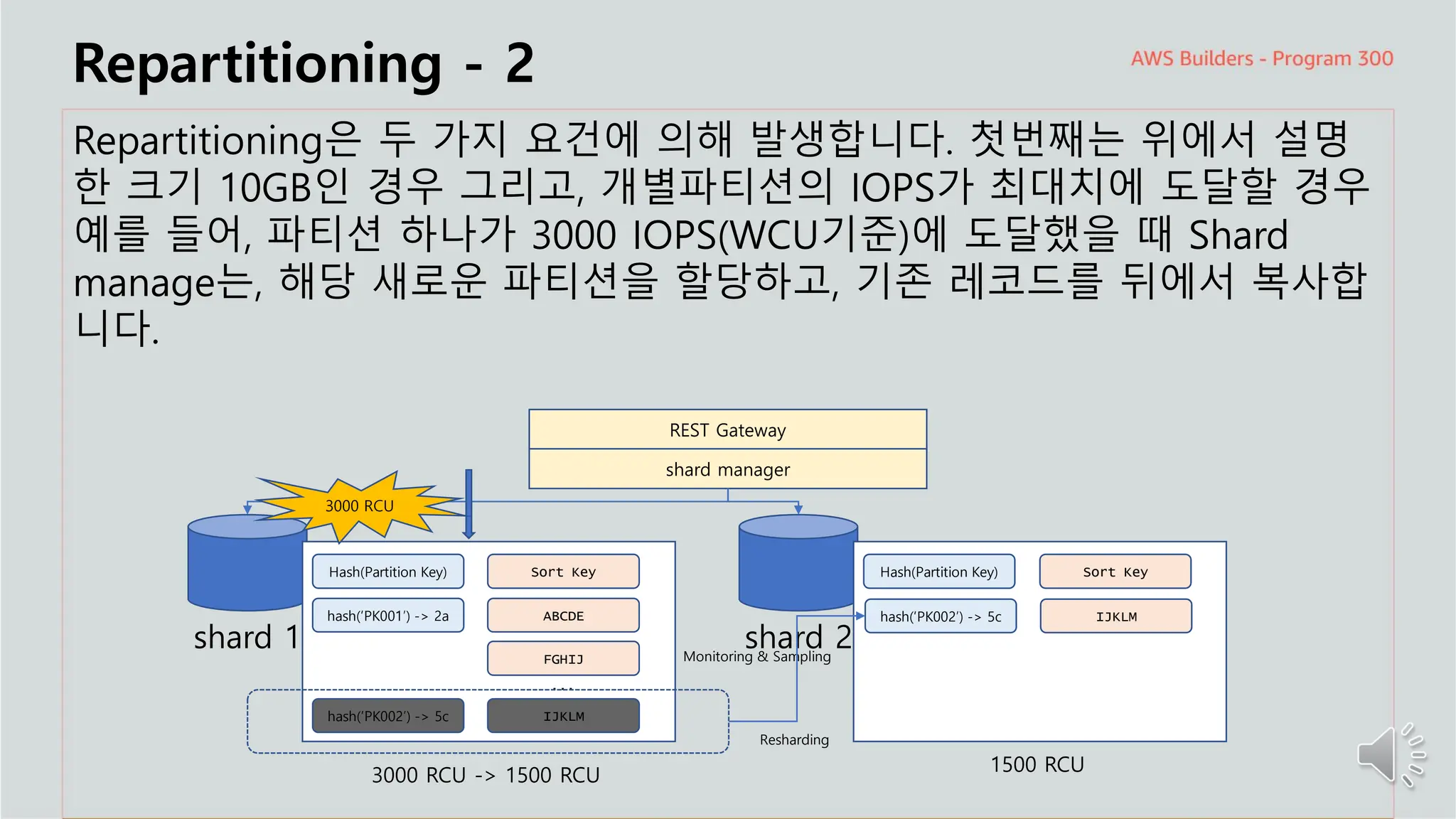
주요 주제
Repartitioning -2
Repartitioning은 두 가지 요건에 의해 발생합니다. 첫번째는 위에서 설명
한 크기 10GB인 경우 그리고, 개별파티션의 IOPS가 최대치에 도달할 경우
예를 들어, 파티션 하나가 3000 IOPS(WCU기준)에 도달했을 때 Shard
manage는, 해당 새로운 파티션을 할당하고, 기존 레코드를 뒤에서 복사합
니다.
Hash(Partition Key)
REST Gateway
shard manager
Sort Key
shard 1
Hash(Partition Key) Sort Key
shard 2
ABCDE
FGHIJ
IJKLM
hash(‘PK001’) -> 2a
hash(‘PK002’) -> 5c
...
Monitoring & Sampling
3000 RCU
IJKLM
hash(‘PK002’) -> 5c
Resharding
3000 RCU -> 1500 RCU
1500 RCU
34.
주요 주제
Provisioned Capacityvs On-Demand
만약 꾸준하게 부하가 들어온다고 가정해 보겠습니다. (아래 표는 ICN On-
Demand/Provisioned Price)
한쪽은 Request단위로 또 다른 쪽은 WCU 단위로 과금
을 하기 때문에 계산이 어렵습니다. WCU를 Request
로 변환해 보겠습니다.
1 RCU는 1초에 한번의 Request를 처리한다는 의미입
니다. 즉 아래와 같이,
1 RCU * 3600 (Sec) * 24 (Hour) * 30 (Day)
= 2,592,000 (Request)
따라서, 한달 동안 1RCU로 꾸준하게 부하가 발생한다
면, 약 2.6 백만건이며, 이를 On-Demand로 환산하면,
약 0.70$가 됩니다.
Provisioned 모델로 구성하셨다면, 시간당 요금이
0.00014098이므로,
1 RCU * 24 * 30 = 72 RCU / month. 72 RCU = 0.01$
즉, 0.01$가 됩니다.
무조건 Provisioned를 사용하라는 의미가 아니라,
Workload특성을 봐야 합니다!
35.
주요 주제
Autoscaling (inProvisioned Capacity)
Provisioned IOPS를 사용할 경우에는 아래 권고사항을 유념하여 설정하시
기 바랍니다.
1. 반드시, WCU/RCU에 대한 개별적인 정책을 세우셔야 합니다.
2. GSI를 사용하신다면, 반드시 Master Table과 동일한 Autoscaling정책을 구성하십시요.
3. 만약, Global Table기능을 활용한다면, “모든 리전”에 동일한 Autoscaling 정책을 지정합니다.
4. 대형 이벤트를 준비하신다면, Scale-in 이벤트를 잠시 비활성화 할 수 있습니다.
5. Scale In-out이 발생하는 기준을 확신하십시요.
[Scale out] trigger
: Two continuous 1 minute windows over target utilization
[Scale in] trigger
: 15 continuous 1 minute windows under 80% target utilization
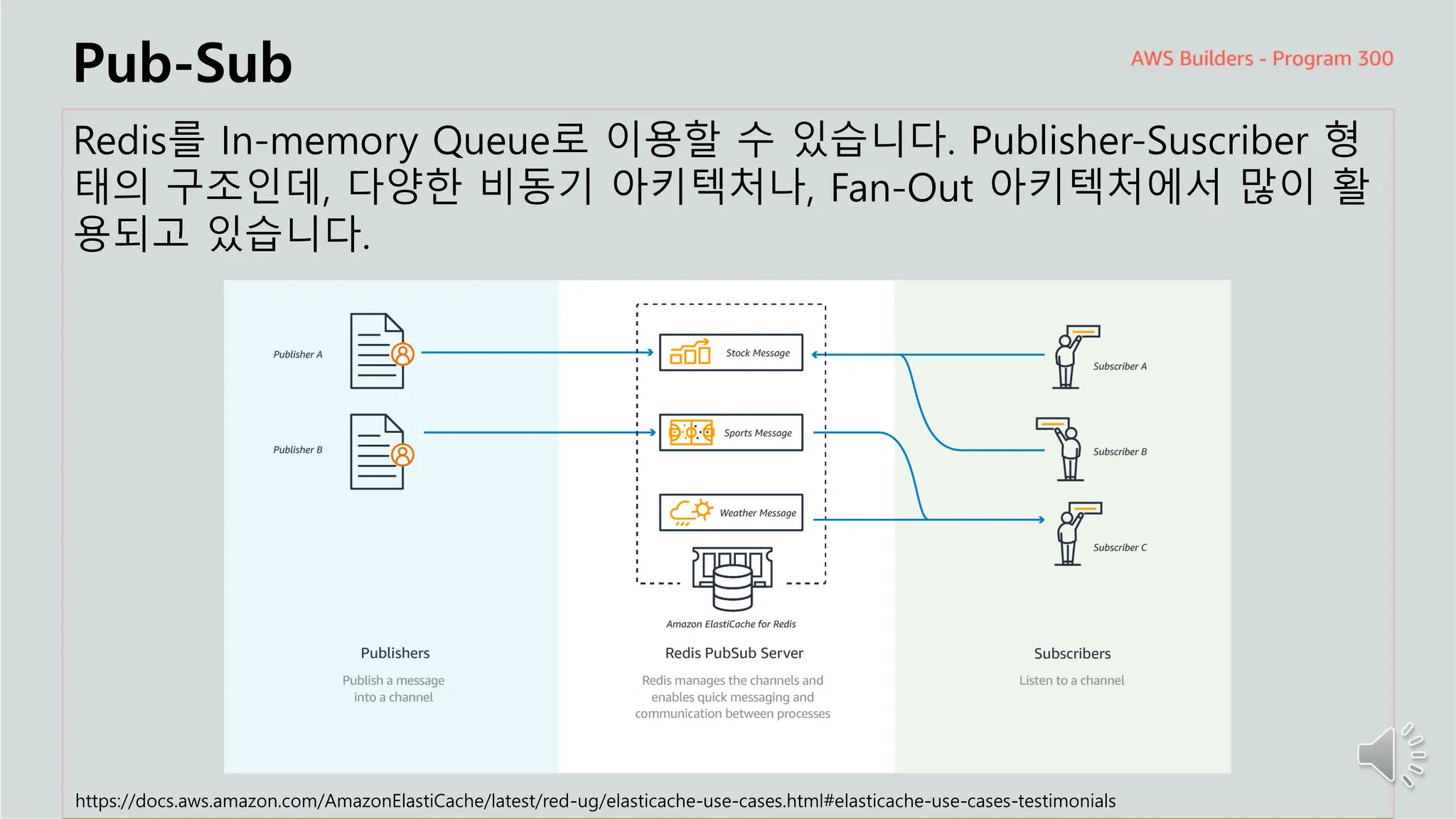
주요 주제
Pub-Sub
Redis를 In-memoryQueue로 이용할 수 있습니다. Publisher-Suscriber 형
태의 구조인데, 다양한 비동기 아키텍처나, Fan-Out 아키텍처에서 많이 활
용되고 있습니다.
https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/elasticache-use-cases.html#elasticache-use-cases-testimonials
38.
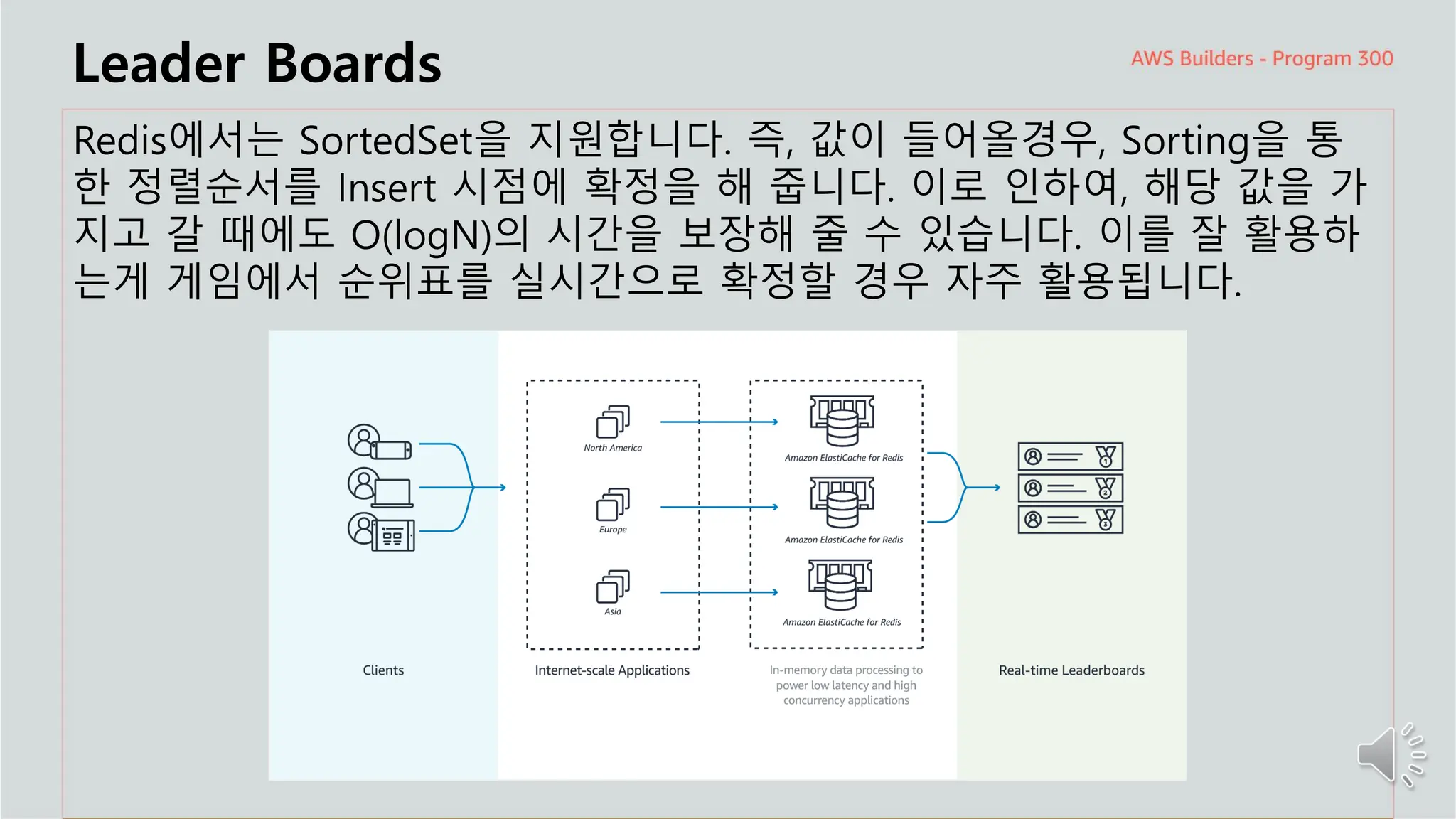
주요 주제
Leader Boards
Redis에서는SortedSet을 지원합니다. 즉, 값이 들어올경우, Sorting을 통
한 정렬순서를 Insert 시점에 확정을 해 줍니다. 이로 인하여, 해당 값을 가
지고 갈 때에도 O(logN)의 시간을 보장해 줄 수 있습니다. 이를 잘 활용하
는게 게임에서 순위표를 실시간으로 확정할 경우 자주 활용됩니다.
39.
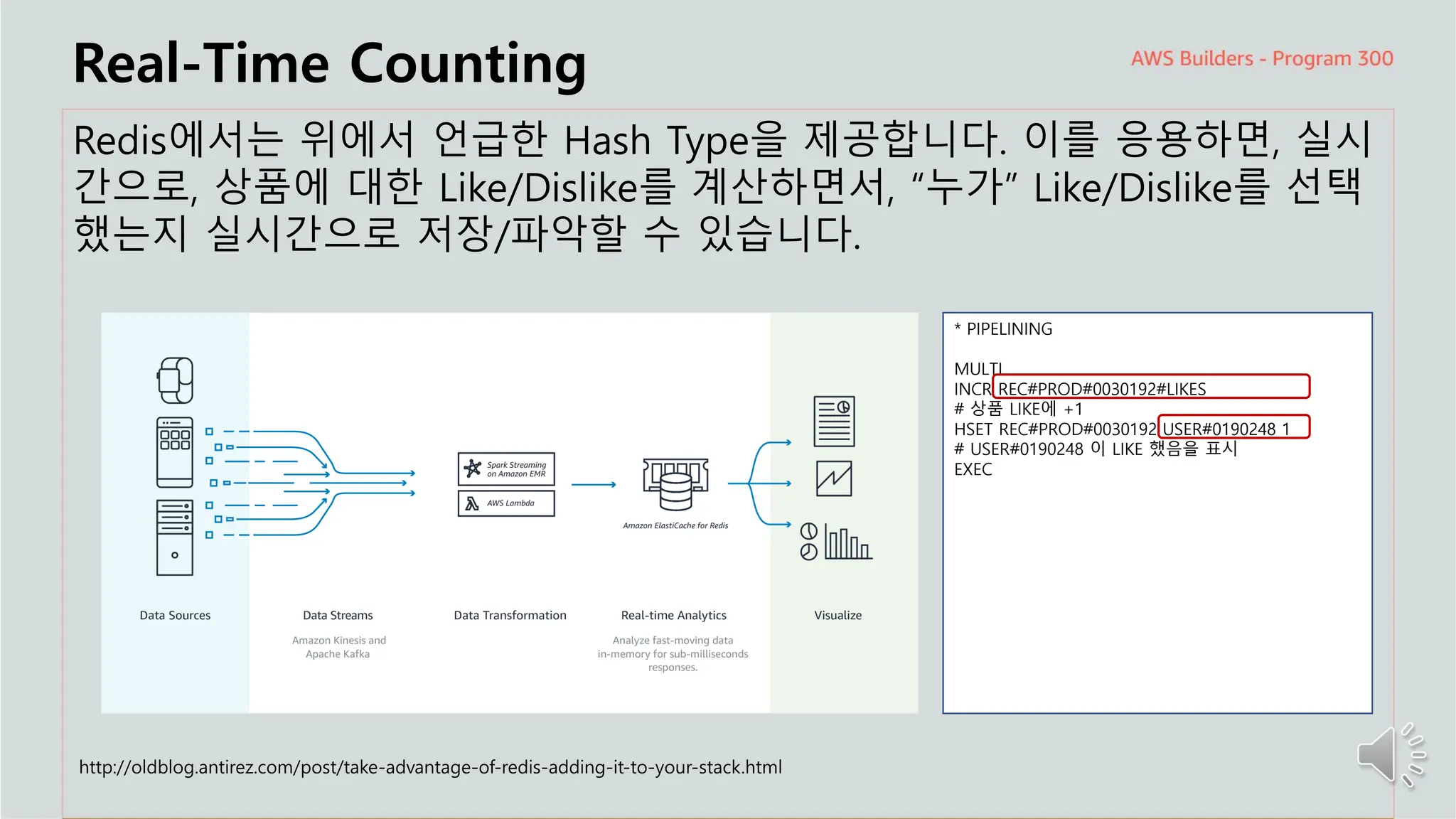
주요 주제
Real-Time Counting
Redis에서는위에서 언급한 Hash Type을 제공합니다. 이를 응용하면, 실시
간으로, 상품에 대한 Like/Dislike를 계산하면서, “누가” Like/Dislike를 선택
했는지 실시간으로 저장/파악할 수 있습니다.
* PIPELINING
MULTI
INCR REC#PROD#0030192#LIKES
# 상품 LIKE에 +1
HSET REC#PROD#0030192 USER#0190248 1
# USER#0190248 이 LIKE 했음을 표시
EXEC
http://oldblog.antirez.com/post/take-advantage-of-redis-adding-it-to-your-stack.html
주요 주제
논리적 테이블을하나의 DDB테이블로
효율적인 JOIN을 하기 위해서는 하나의 DDB테이블로 구성하여야 한다.
효율적인 Query를 하기 위해서는 하나의 DDB테이블로 구성하여야 한다.
효율적인 Provisioning을 하기 위해서 하나의 DDB테이블로 구성하여야 한다.
여러 레코드를 Nested JSON으로 단일 Record표현이 가능하다.
유사한 형태의 조회를 단일 인덱스로 처리할 수 있다.
42.
주요 주제
Join의 개념을다르게 볼 수 있을까?
RDBMS에서 JOIN은 서로 다른 두개의 테이블과 레코드를 하나로 묶습니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
ACC_ID BAL USER_ID
03-240-X 1,000,000 USER001
SELECT A.ID, A.NAME, A.TEL, A.ADDR, B.ACC_ID, B.BAL FROM USER A JOIN ACCOUNT B ON (A.ID = B.USER_ID) WHERE A.ID = “USER001”
--------------------------------------------------------------------------------------------------------------------------------
USER001, HNK, 821010XX, Seoul..., 03-240-X, 1000000
[Coding] String id = resultset.getString(1); String name = resultset.getString(2); String telno = resultset.getString(3); ...; String accounted = resultset.getString(5); ...
ID(Part) SK(Sort) NAME TEL ADDR ACC_ID BAL
USER001 USER HNK 821010xx Seoul...
USER001 ACC 03-240-X 1,000,000
Query
{ “TableName” : “USERMASTER”, “ProjectionExpression” : “id, sortkey, name, tel, addr, acc_id, bal”, “KeyConditionExpression” : “id = :v1”, ... }
[Coding] ItemCollection<UserMaster> items = table.query(spec); Iterator<Item> iterator = items.iterator(); Item item = null;
while(iterator.hasNext()) { item = iterator.next(); if( item.get(“sk“).equals( “USER” ) classmap(targetBean, User.class, item ) else classmap(targetBean, Acc.class,item) }
DynamoDB에서 JOIN 개념은 두개의 레코드를 한번에 조회하는 것입니다.
43.
주요 주제
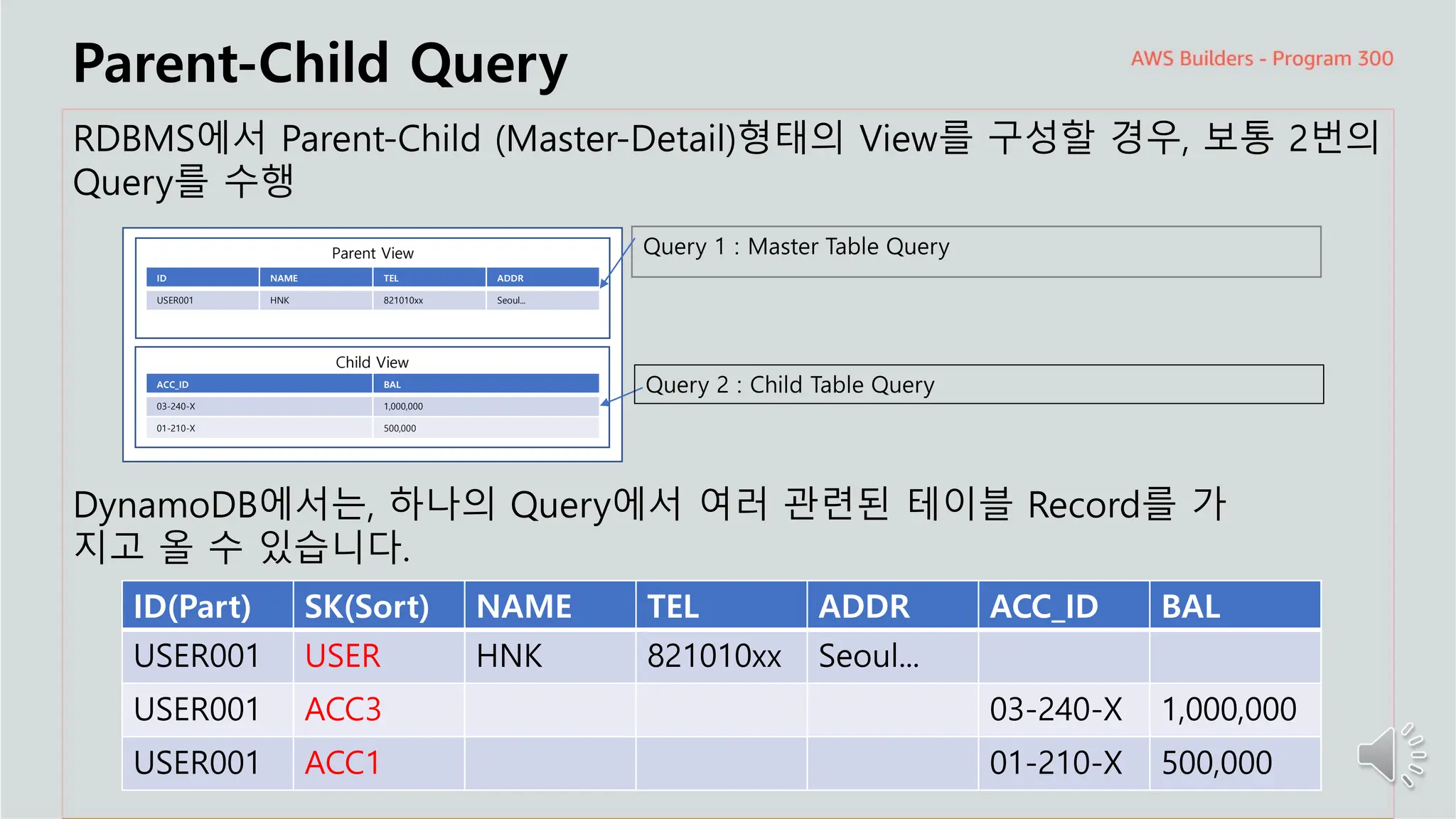
Parent-Child Query
RDBMS에서Parent-Child (Master-Detail)형태의 View를 구성할 경우, 보통 2번의
Query를 수행
Query 1 : Master Table Query
ID(Part) SK(Sort) NAME TEL ADDR ACC_ID BAL
USER001 USER HNK 821010xx Seoul...
USER001 ACC3 03-240-X 1,000,000
USER001 ACC1 01-210-X 500,000
Parent View
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
Child View
ACC_ID BAL
03-240-X 1,000,000
01-210-X 500,000
Query 2 : Child Table Query
DynamoDB에서는, 하나의 Query에서 여러 관련된 테이블 Record를 가
지고 올 수 있습니다.
44.
주요 주제
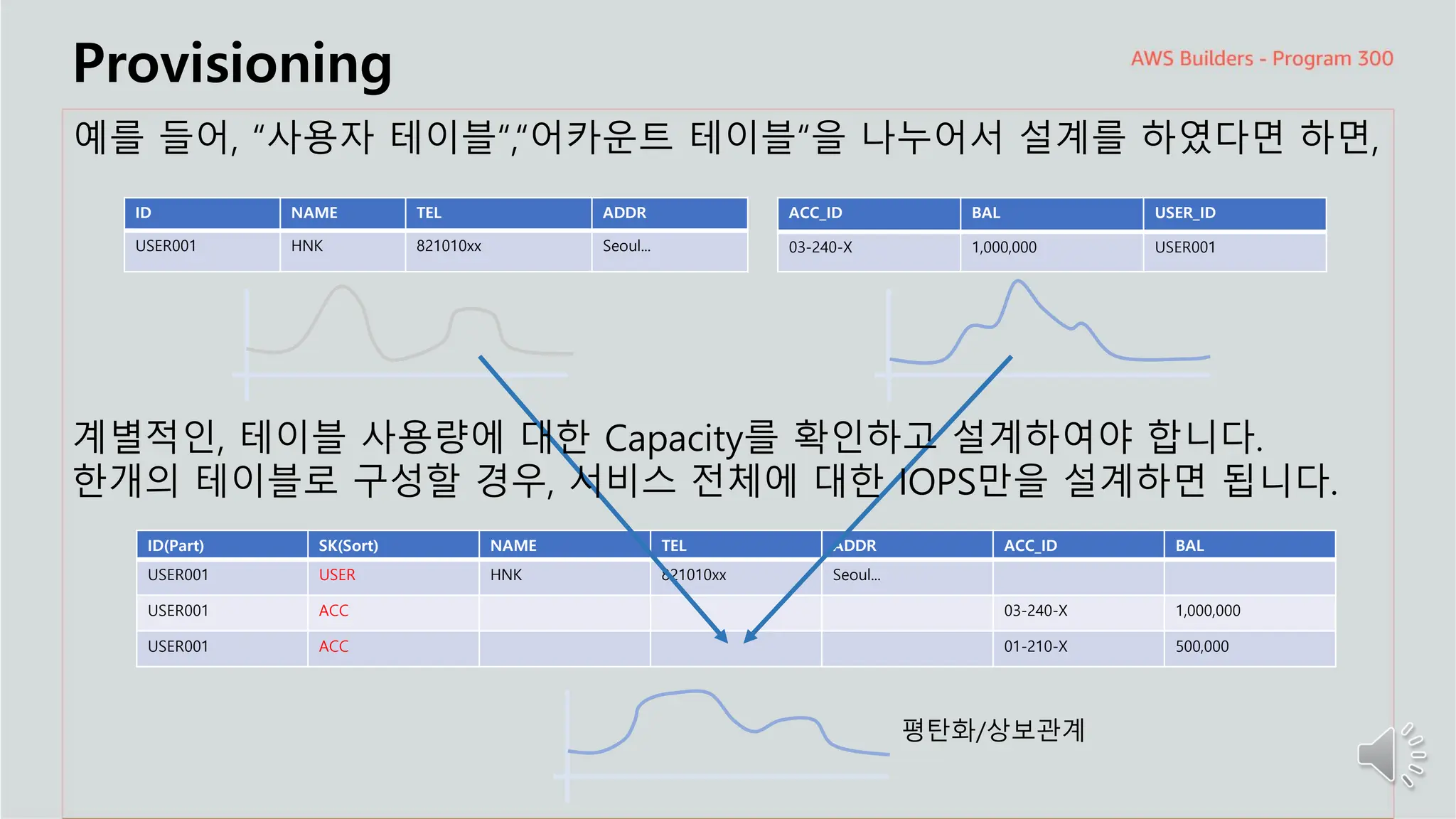
Provisioning
예를 들어,“사용자 테이블“,“어카운트 테이블“을 나누어서 설계를 하였다면 하면,
ID(Part) SK(Sort) NAME TEL ADDR ACC_ID BAL
USER001 USER HNK 821010xx Seoul...
USER001 ACC 03-240-X 1,000,000
USER001 ACC 01-210-X 500,000
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
ACC_ID BAL USER_ID
03-240-X 1,000,000 USER001
평탄화/상보관계
계별적인, 테이블 사용량에 대한 Capacity를 확인하고 설계하여야 합니다.
한개의 테이블로 구성할 경우, 서비스 전체에 대한 IOPS만을 설계하면 됩니다.
45.
주요 주제
여러 레코드를하나의 레코드로
예를 들어, “사용자 테이블“, “초기 접속 서버“를 테이블로 나누어서 설계를 하였
다면 하면, 아래와 같이 구성할 수 있습니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
SRV_ID USER_ID REGION
SRV_001_LOBBY USER001 SEOUL
SRV_002_WORLD USER001 SEOUL
SRV_003_WORLD USER001 TOKYO
ID NAME TEL ADDR INIT_SERVER
USER001 HNK 821010xx Seoul... { servers : [ {
server_id : “SRV_001_LOBBY”,
region : “SEOUL”
}, {
server_id : “SRV_002_WORLD”,
region : “SEOUL”
}, {
server_id : “SRV_003_WORLD”,
region : “SEOUL”
} ]
}
만약, “초기 접속 서버” 정보가 고정적이고, 사용자 정보 특히 로그인 시점의 정
보와 밀접하게 연결되어 있다면, 여러 레코드를 하나의 레코드로 묶어서 제공해
줄 수 있게 됩니다.
46.
주요 주제
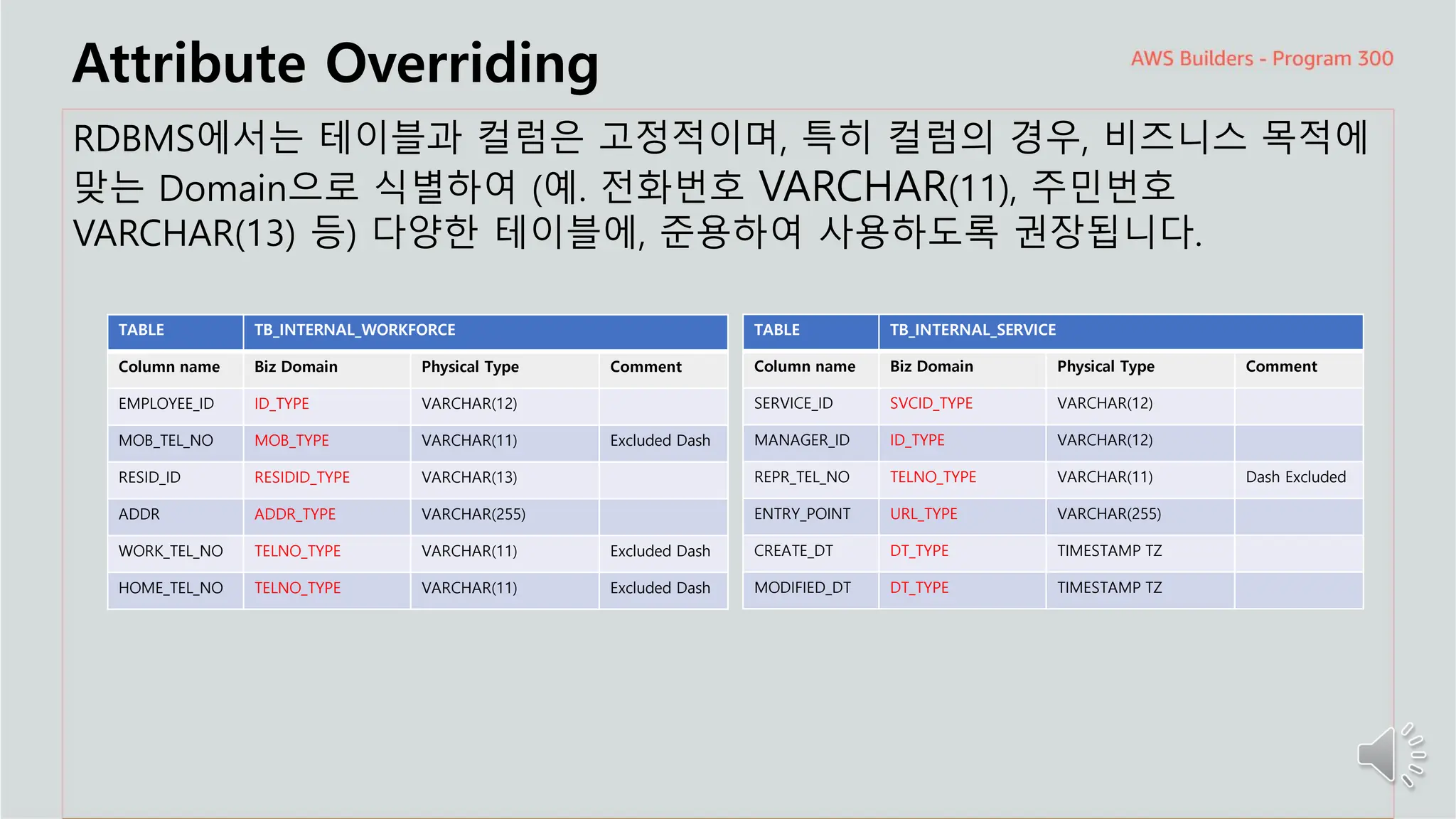
Attribute Overriding
RDBMS에서는테이블과 컬럼은 고정적이며, 특히 컬럼의 경우, 비즈니스 목적에
맞는 Domain으로 식별하여 (예. 전화번호 VARCHAR(11), 주민번호
VARCHAR(13) 등) 다양한 테이블에, 준용하여 사용하도록 권장됩니다.
TABLE TB_INTERNAL_WORKFORCE
Column name Biz Domain Physical Type Comment
EMPLOYEE_ID ID_TYPE VARCHAR(12)
MOB_TEL_NO MOB_TYPE VARCHAR(11) Excluded Dash
RESID_ID RESIDID_TYPE VARCHAR(13)
ADDR ADDR_TYPE VARCHAR(255)
WORK_TEL_NO TELNO_TYPE VARCHAR(11) Excluded Dash
HOME_TEL_NO TELNO_TYPE VARCHAR(11) Excluded Dash
TABLE TB_INTERNAL_SERVICE
Column name Biz Domain Physical Type Comment
SERVICE_ID SVCID_TYPE VARCHAR(12)
MANAGER_ID ID_TYPE VARCHAR(12)
REPR_TEL_NO TELNO_TYPE VARCHAR(11) Dash Excluded
ENTRY_POINT URL_TYPE VARCHAR(255)
CREATE_DT DT_TYPE TIMESTAMP TZ
MODIFIED_DT DT_TYPE TIMESTAMP TZ
47.
주요 주제
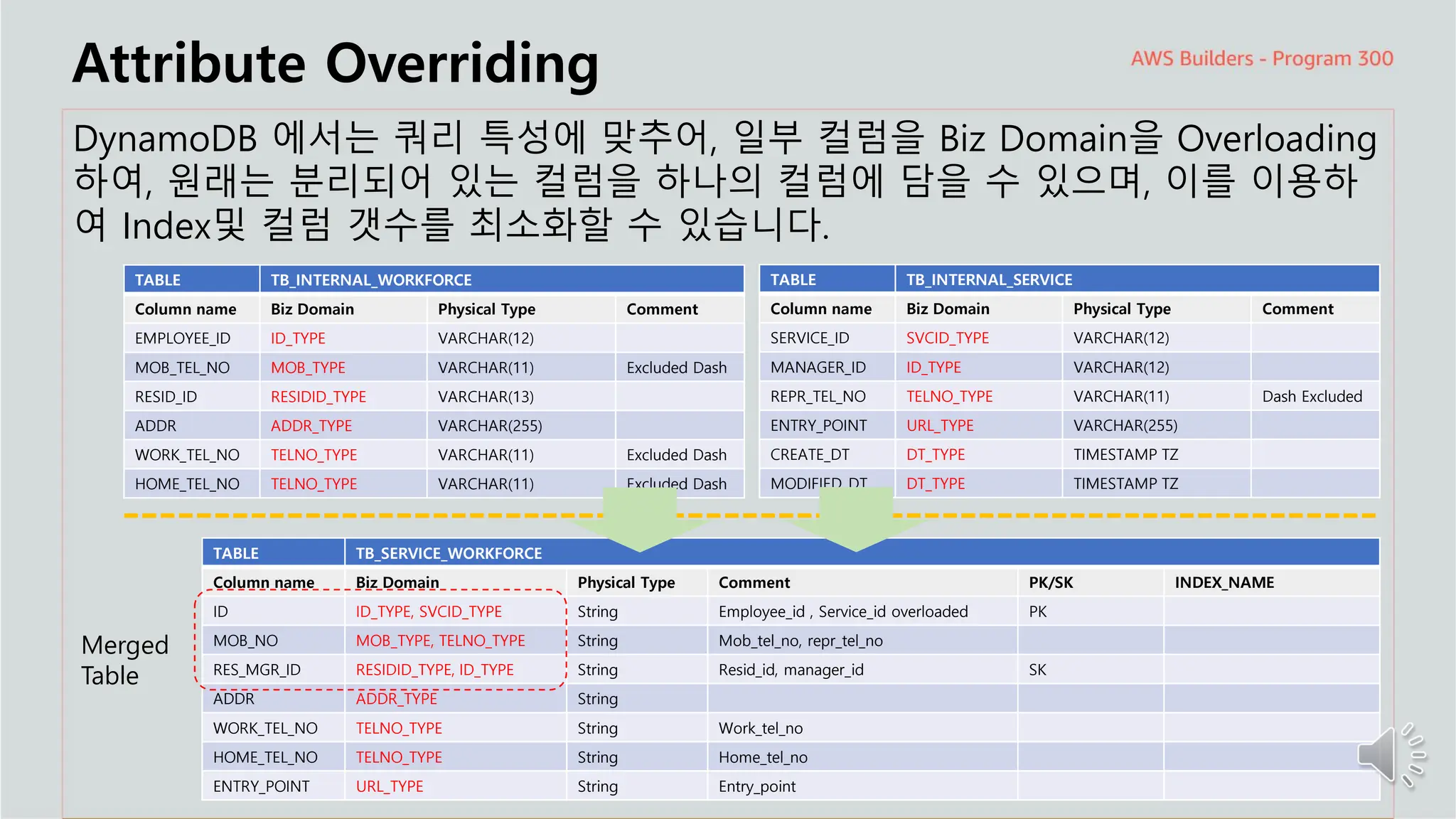
Attribute Overriding
DynamoDB에서는 쿼리 특성에 맞추어, 일부 컬럼을 Biz Domain을 Overloading
하여, 원래는 분리되어 있는 컬럼을 하나의 컬럼에 담을 수 있으며, 이를 이용하
여 Index및 컬럼 갯수를 최소화할 수 있습니다.
TABLE TB_INTERNAL_WORKFORCE
Column name Biz Domain Physical Type Comment
EMPLOYEE_ID ID_TYPE VARCHAR(12)
MOB_TEL_NO MOB_TYPE VARCHAR(11) Excluded Dash
RESID_ID RESIDID_TYPE VARCHAR(13)
ADDR ADDR_TYPE VARCHAR(255)
WORK_TEL_NO TELNO_TYPE VARCHAR(11) Excluded Dash
HOME_TEL_NO TELNO_TYPE VARCHAR(11) Excluded Dash
TABLE TB_INTERNAL_SERVICE
Column name Biz Domain Physical Type Comment
SERVICE_ID SVCID_TYPE VARCHAR(12)
MANAGER_ID ID_TYPE VARCHAR(12)
REPR_TEL_NO TELNO_TYPE VARCHAR(11) Dash Excluded
ENTRY_POINT URL_TYPE VARCHAR(255)
CREATE_DT DT_TYPE TIMESTAMP TZ
MODIFIED_DT DT_TYPE TIMESTAMP TZ
TABLE TB_SERVICE_WORKFORCE
Column name Biz Domain Physical Type Comment PK/SK INDEX_NAME
ID ID_TYPE, SVCID_TYPE String Employee_id , Service_id overloaded PK
MOB_NO MOB_TYPE, TELNO_TYPE String Mob_tel_no, repr_tel_no
RES_MGR_ID RESIDID_TYPE, ID_TYPE String Resid_id, manager_id SK
ADDR ADDR_TYPE String
WORK_TEL_NO TELNO_TYPE String Work_tel_no
HOME_TEL_NO TELNO_TYPE String Home_tel_no
ENTRY_POINT URL_TYPE String Entry_point
Merged
Table
주요 주제
않좋은 예시– 일괄저장/일괄조회
로그인 부터 사용자 관련 데이터가 Instance (Structure)형태로 메모리에서 관리
합니다.여러건의 레코드의 경우 Collection 형태의 Attribute로 관리합니다.
Class UserInformation {
private String name;
private String password;
private bool isValid;
private accountId;
private List<Logs> histLogs;
private List<GameChar> characters;
private int totalGold;
}
여러건의 레코드를 Collection Attribute로 처리
[위 레코드에 대한 처리 방식]
private void storeToDDB(UserInformation userInfo) {
List<dynamodb.Item> splittedItems = DynamoDBMapper.convertToItem(userInfo)
splittedItems.foreach(x => table.putItem(x));
}
private UserInformation restoreFromDDB(String userid) {
List<dynamodb.Item> splittedItems = new ArrayList<dynamodb.Item>();
dynamodb.Item currentItem = table.getItem(“UserId”, userid); splittedItems.add(currentItem);
while((String nextPos = currentItem.getString(“NextPos”)) != null) {
currentItem = table.getItem(“UserId”, nextPos); splittedItems.add(currentItem);
}
return DynamoDBMapper.convertToUserItem(splittedItems);
}
하나의 Instance를
DynamoDB Item으로 Split하
여 한꺼번에 저장
여러개의 DynamoDB Item을
추적하여, 뭉친다음 하나의
Instance로 제공
50.
주요 주제
않좋은 예시– DDB Table
게임의 로그인 부터 사용자의 모든 데이터를 하나의 Row에 대응
개인별 로그성 데이터의 누적 및 관리
한번에 모든 데이터를 읽어서 Application이 관리
쓰기는 중요도에 따라 Batch형태, 또는 실시간으로 수행
On the fly data loss에 대한 Reconstruction 을 위한 Application 로직 중요
ID(Part) VALID NAME PWD LOGHIST ACCID 기타등등
USER001 YES HANK 202cb…
[“2019-12-31 14:..”,
“2020-01-03
16:1…”,…]
USER002 YES IGUANA 962ac… [“2020-01-14 15:..”,
“2020-01-23
17:1…”,…]
03-240-X
USER004 NO LILY 59075…
[“2020-01-30 17:..”,
“2020-02-03
16:1…”,…]
01-210-X
51.
주요 주제
않좋은 예시– DDB Table
[설계 원칙]
1 사용자 정보는 1 ROW 이상으로 구성됩니다.
400KB/ row – data split read/ write: 400KB가 넘어가면 끝에 continue할 Key값을
추가하여 다음 ROW를 알 수 있고, 이를 활용하여 이어 읽기가 가능해 집니다.
읽을 때는 모두 다 읽고, 쓸 때도 모든 데이터를 한번에 Flush 하는 형태가 됩니다.
ID(Part) VALID NAME PWD LOGHIST 기타데이터 NEXTROW
USER001 YES HANK 202cb…
[“2019-12-31 14:..”,
“2020-01-03 16:1…”,…] [“aaa”, …] USER001-p13
ID(Part) VALID DEX GOLD LASTPOS NEXTROW
USER001-p13 YES 16 47782 [12345,77863,43]
END
52.
주요 주제
않좋은 예시– 문제점
읽기 낭비: Workload에 맞는 쿼리 튜닝을 수행할 수 없습니다.
예) User ID/ PWD만 확인
오브젝트가 처음에는 작지만 게임이 진행되면서 커지는 문제
최초 5KB만 읽고 쓰다가 이젠 2MB씩 읽고 쓰고 있음
LOG성 자료 확인/제거가 Batch로 동작. 대량의 Read/ Write가 발생합니다.
Main Block이 아닌 Row에 있는 데이터를 한번에 가져올 방법이 없습니다.
사용자 데이터 크기를 어플리케이션에서 직접적으로 관리해주어야 합니다.
주요 주제
접근 방식
데이터(컬럼)의특성을 알아야 합니다.
데이터를 특성에 따라 분류해야 합니다.
자주 사용하는 데이터와 자주 사용하지 않는 데이터
그룹으로 처리되는 데이터
속성에 따라 분류 – Status / Count
로그성 데이터
컬럼을 레코드로 분리합니다.
분리된 레코드의 키 설계를 수행합니다.
SORT Key의 디자인
데이터의 중복과 Composite Key
55.
주요 주제
데이터의 특성이해
데이터를 온전히 파악할 필요가 있습니다
데이터를 어떤 빈도로, 어떤 의도로 접근할지 알아야합니다
[예시]
읽기가 잦은 데이터 – ID/ PWD
쓰기/갱신이 잦은 데이터 – Character 속성, ITEM
유효기간이 있는 데이터 – LOG성 데이터들
기타 등등
56.
주요 주제
데이터 컬럼그룹핑
사용자 초기 로그인 시에 활용되는 컬럼
ID PWD NAME
USER001 YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID DEX GOLD ITEMS
USER001 YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간이 지나면, 제거해야 하는 자료들
ID LOGHIST
USER001 [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]
ID(Part) VALID NAME PWD LOGHIST ITEMS NEXTROW
USER001 YES HANK 202cb… [“2019-12-31 14:..”,
“2020-01-03 16:1…”,…]
[“aaa”, …] USER001-p13
ID(Part) VALID DEX GOLD LASTPOS NEXTROW
USER001-p13 YES 16 47782 [12345,77863,43] END
57.
주요 주제
레코드 분리검증
단일 레코드를 여러개의 컬럼 그룹으로 구분하여, 레코드를 생성할 수도 있으며,
LSI, GSI를 이용하여 구현할 수도 있습니다. 제일 중요한 판단 기준은 해당 자료의
생성/조회 시점에 같이 이용이 필요한지에 따라 다릅니다.
• 사용자 초기 로그인 시에 활용되는 컬럼
ID PWD NAME
USER001 YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID DEX GOLD ITEMS
USER001 YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간후 삭제
ID LOGHIST
USER001 [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]
사용자 등록/로그인시에만 주로
활용됩니다. 즉 독립적인 레코드로
구성해도 좋습니다.
게임 진행이 종료될 경우, 또는 주기적으로
저장할 경우, 활용됩니다. 다른 컬럼과의
종속관계가 낮아 독립적인 레코드 구성 O
시간대에 따른 추가 Record가 생성이 되며,
TTL적용을 위하여 독립 레코드 구성에
적합함
58.
주요 주제
분리된 레코드의Sort Key 설계
일단, 분리된 레코드에 Sort Key를 제공하여, Primary Key를 구성하여, 개별 Record
로 인식할 수 있게 하며, 조회 조건을 고려하여 Composite SortKey로 추가 조회 조
건으로 활용할 수 있게 제공
• 사용자 초기 로그인 시에 활용되는 컬럼
ID SK(SortKey) PWD NAME
USER001 “LOGIN” YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID SK(SortKey) DEX GOLD ITEMS
USER001 ‘ServerId’+’:” + ‘CharId’ YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간후 삭제
ID SK(SortKey) LOGHIST
USER001 “LOG”+‘:’+‘ServerId’+’:”+‘Serial’ [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]
59.
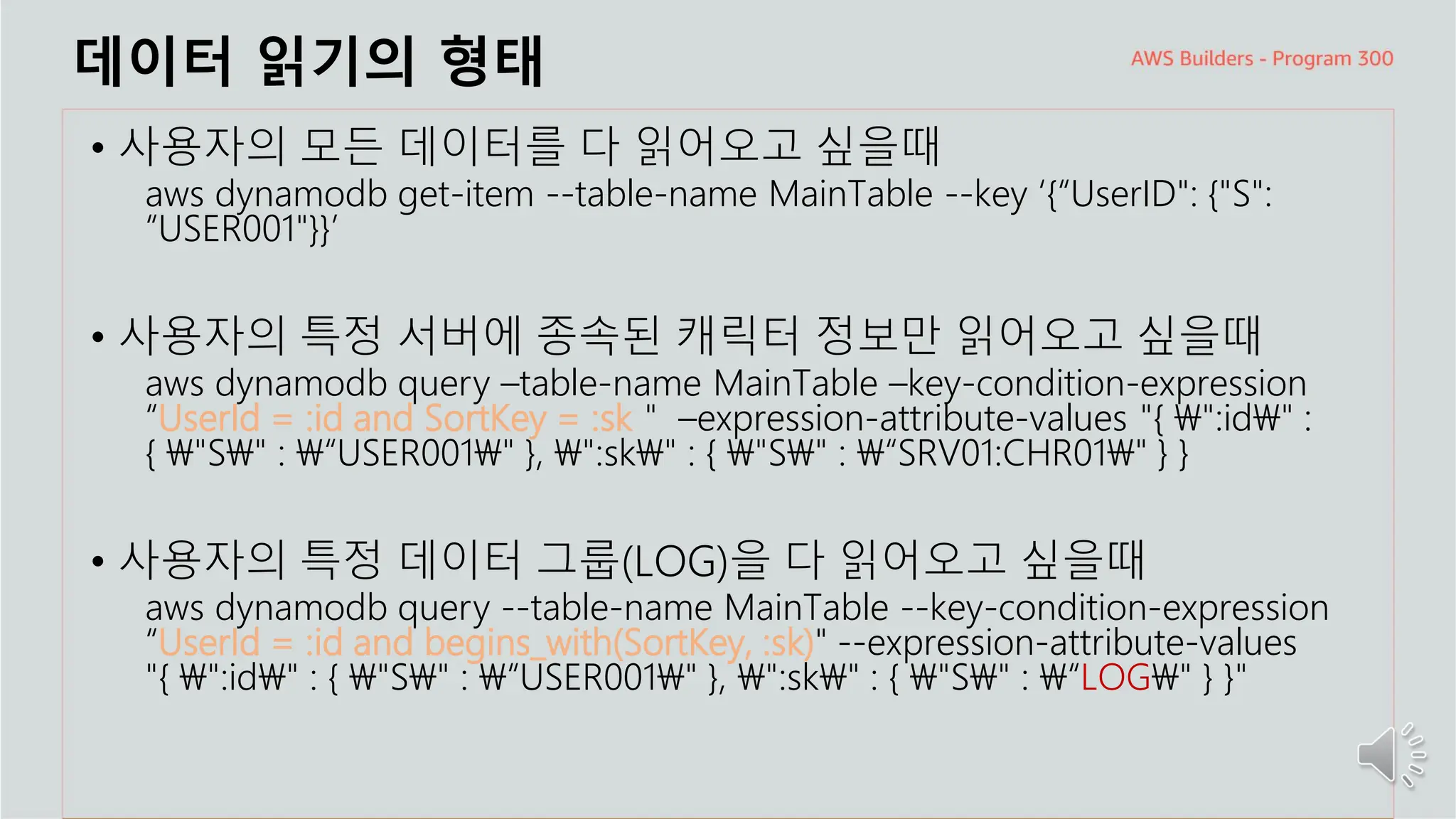
주요 주제
데이터 읽기의형태
• 사용자의 모든 데이터를 다 읽어오고 싶을때
aws dynamodb get-item --table-name MainTable --key ‘{“UserID": {"S":
“USER001"}}’
• 사용자의 특정 서버에 종속된 캐릭터 정보만 읽어오고 싶을때
aws dynamodb query –table-name MainTable –key-condition-expression
“UserId = :id and SortKey = :sk" –expression-attribute-values "{ ":id" :
{ "S" : “USER001" }, ":sk" : { "S" : “SRV01:CHR01" } }
• 사용자의 특정 데이터 그룹(LOG)을 다 읽어오고 싶을때
aws dynamodb query --table-name MainTable --key-condition-expression
“UserId = :id and begins_with(SortKey, :sk)" --expression-attribute-values
"{ ":id" : { "S" : “USER001" }, ":sk" : { "S" : “LOG" } }"
60.
주요 주제
DynamoDB Workshopfor workload
• DynamoDB 설계 경험을 가지고 있는 Special SA가 투입되어, 실제
사용자 Workload를 같이 분석하고,
• DynamoDB 레이아웃을 같이 분석하거나,
• 기존에 있던 DynamoDB 설계를 같이 Review해주는 Deep Dive
Session
• 담당자 : Khim, SungSoo (sungsook@amazon.com)
Park, KyungPyo (kyunp@amazon.com)








![주요 주제
Index Key 설계 - 1
Key-Value 구조에서는 보통 다양한 Key를 구성하여, 인덱스 효과를 생성할
수 있습니다. 즉, 기준이 되는 Item Record를 하나 구성하면서, Filter에 활
용될 Key를 추가할 수 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
인덱스를 생성해서
조회속도를 업!
인덱스용 키를 별도로
생성해서
조회
USER#MOB#010-1234-5678 USER#USER001
USER#MOB#010-5678-1234 USER#USER002](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-19-2048.jpg)
![주요 주제
Index Key 설계 - 2
실제 상황에서는 다양한 Filter조건을 이용하여 Record 검색을 수행합니다.
이럴 경우, Index용 Key를 AND 조건의 경우 모두 Concatenate하여 대리
수행할 수 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
인덱스를 생성해서
조회속도를 업!
서울 사는 “일동"이
를 어떻게 찾을까?
USER#HONGILDONG#Seoul, Korea USER#USER001
USER#KIMCHEONSOO#Busan, Korea USER#USER002](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-20-2048.jpg)
![주요 주제
Index Key 설계 - 3
만약, Unique가 아닌 값을, Filter조건을 위하여, Key로 생성하였을 경우에
는, Database에서 제공하는 솔루션을 활용하여야 합니다. 예를 들어, Redis
의 List를 이용하거나, DDB의 Index를 이용합니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER955 HONGILDONG 160424-3654321 010-5678-1234 Seoul, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#HONGILDONG#Seoul, Korea [ USER#USER001, USER#USER955 ]
USER#USER955
{ “name” : “HONGILDONG”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Seoul, Korea” }
Composite 인덱스
를 생성해서 조회
속도를 업!
아 주소가 비슷한 동
명이인이 있다니!!!](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-21-2048.jpg)
![주요 주제
Index Key 설계 - 4
OR 조건 검색이 필요할 경우에는, OR 전체를 묶는 새로운 키를 생성할 수
도 있습니다.
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#HONGILDONG#Seoul, Korea [ USER#USER001, USER#USER955 ]
USER#HONGILDONG#010-1234-4578 [ USER#USER001 ]
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-
3654321”, “mob”:”010-5678-1234”, “addr” : “Busan,
Korea” }
아 주소가 비슷한 동
명이인이 있다니!!!
SELECT ITEM_ID, RES_ID
FROM TB_USER
WHERE NAME = ‘HONGILDONG’ AND
( ADDR = ‘SEOUL, Korea’ OR MOB = ‘010-5678-1234’ )](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-22-2048.jpg)
![주요 주제
Aggregation
Key만 제공되는 Database에서는 Aggregation이 기본적으로 제공되지 않
습니다. 하지만, 필요시에는 Attribute를 추가하거나, 별도의 “통계KEY”를
구성하여
ElastiCache
ITEM_ID (PK) NAME RES_ID MOB ADDR
USER001 HONGILDONG 170724-4123456 010-1234-5678 Seoul, Korea
USER002 KIMCHEONSOO 160424-3654321 010-5678-1234 Busan, Korea
[RDBMS Format – TB_USER]
[Key Value format]
KEY VALUE
USER#SEOUL#USER_COUNT 3
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER002
{ “name” : “KIMCHEONSOO”, “res_id”: “160424-3654321”,
“mob”:”010-5678-1234”, “addr” : “Busan, Korea” }
서울 사는 유저들에 대해서 실
시간 통계를 구하고 싶은데 어
떻게 하지 ?
사용자가 추가될 때마다, +1을
해주어야 겠다.
SELECT ADDR, COUNT(1) as USER_COUNT
FROM TB_USER
WHERE ADDR = ‘Seoul, Korea’](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-23-2048.jpg)
![주요 주제
Record & Column conversion
Value에서, 다양한 형태의 자료구조를 제공하는 Database도 있지만, 기본
적으로, String은 대부분의 Key Value Database에서 모두 제공합니다.
String Value의 경우, JSON Type같이 Column Name(Attribute)가 포함될
경우, Record / Column의 경계가 매우 모호해지며, 다양한 응용이 생깁니
다.
ElastiCache
[Key Value format]
KEY VALUE
USER#USER001
{ “name”:”HONGILDONG”, “res_id”:”170724-4123456”,
“mob”:”010-1234-5678”, “addr” : “Seoul, Korea” }
USER#USER001#SECRET { “credential”:”3bac-de3c-....”, “secretToekn”: “abcdef” }
아 나는 Credential 정보를 접근
하게 하고 싶지 않아, “레코드"
를 분리해야 겠군!](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-24-2048.jpg)




![주요 주제
Partitioning
Redis/DynamoDB 모두 Sharding(Clustering)기능을 제공합니다. Redis는
사용자가 요청할 경우 Node 추가 시, Slot을 조정하여 이를 해결하고,
DynamoDB는 WCU/RCU와 용량을 판단하여, 자동 조정하게 되어 있습니
다.
[REDIS] [DynamoDB]](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-29-2048.jpg)

![주요 주제
Autoscaling (in Provisioned Capacity)
Provisioned IOPS를 사용할 경우에는 아래 권고사항을 유념하여 설정하시
기 바랍니다.
1. 반드시, WCU/RCU에 대한 개별적인 정책을 세우셔야 합니다.
2. GSI를 사용하신다면, 반드시 Master Table과 동일한 Autoscaling정책을 구성하십시요.
3. 만약, Global Table기능을 활용한다면, “모든 리전”에 동일한 Autoscaling 정책을 지정합니다.
4. 대형 이벤트를 준비하신다면, Scale-in 이벤트를 잠시 비활성화 할 수 있습니다.
5. Scale In-out이 발생하는 기준을 확신하십시요.
[Scale out] trigger
: Two continuous 1 minute windows over target utilization
[Scale in] trigger
: 15 continuous 1 minute windows under 80% target utilization](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-35-2048.jpg)



![주요 주제
Join의 개념을 다르게 볼 수 있을까?
RDBMS에서 JOIN은 서로 다른 두개의 테이블과 레코드를 하나로 묶습니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
ACC_ID BAL USER_ID
03-240-X 1,000,000 USER001
SELECT A.ID, A.NAME, A.TEL, A.ADDR, B.ACC_ID, B.BAL FROM USER A JOIN ACCOUNT B ON (A.ID = B.USER_ID) WHERE A.ID = “USER001”
--------------------------------------------------------------------------------------------------------------------------------
USER001, HNK, 821010XX, Seoul..., 03-240-X, 1000000
[Coding] String id = resultset.getString(1); String name = resultset.getString(2); String telno = resultset.getString(3); ...; String accounted = resultset.getString(5); ...
ID(Part) SK(Sort) NAME TEL ADDR ACC_ID BAL
USER001 USER HNK 821010xx Seoul...
USER001 ACC 03-240-X 1,000,000
Query
{ “TableName” : “USERMASTER”, “ProjectionExpression” : “id, sortkey, name, tel, addr, acc_id, bal”, “KeyConditionExpression” : “id = :v1”, ... }
[Coding] ItemCollection<UserMaster> items = table.query(spec); Iterator<Item> iterator = items.iterator(); Item item = null;
while(iterator.hasNext()) { item = iterator.next(); if( item.get(“sk“).equals( “USER” ) classmap(targetBean, User.class, item ) else classmap(targetBean, Acc.class,item) }
DynamoDB에서 JOIN 개념은 두개의 레코드를 한번에 조회하는 것입니다.](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-42-2048.jpg)
![주요 주제
여러 레코드를 하나의 레코드로
예를 들어, “사용자 테이블“, “초기 접속 서버“를 테이블로 나누어서 설계를 하였
다면 하면, 아래와 같이 구성할 수 있습니다.
ID NAME TEL ADDR
USER001 HNK 821010xx Seoul...
SRV_ID USER_ID REGION
SRV_001_LOBBY USER001 SEOUL
SRV_002_WORLD USER001 SEOUL
SRV_003_WORLD USER001 TOKYO
ID NAME TEL ADDR INIT_SERVER
USER001 HNK 821010xx Seoul... { servers : [ {
server_id : “SRV_001_LOBBY”,
region : “SEOUL”
}, {
server_id : “SRV_002_WORLD”,
region : “SEOUL”
}, {
server_id : “SRV_003_WORLD”,
region : “SEOUL”
} ]
}
만약, “초기 접속 서버” 정보가 고정적이고, 사용자 정보 특히 로그인 시점의 정
보와 밀접하게 연결되어 있다면, 여러 레코드를 하나의 레코드로 묶어서 제공해
줄 수 있게 됩니다.](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-45-2048.jpg)

![주요 주제
않좋은 예시 – 일괄저장/일괄조회
로그인 부터 사용자 관련 데이터가 Instance (Structure)형태로 메모리에서 관리
합니다.여러건의 레코드의 경우 Collection 형태의 Attribute로 관리합니다.
Class UserInformation {
private String name;
private String password;
private bool isValid;
private accountId;
private List<Logs> histLogs;
private List<GameChar> characters;
private int totalGold;
}
여러건의 레코드를 Collection Attribute로 처리
[위 레코드에 대한 처리 방식]
private void storeToDDB(UserInformation userInfo) {
List<dynamodb.Item> splittedItems = DynamoDBMapper.convertToItem(userInfo)
splittedItems.foreach(x => table.putItem(x));
}
private UserInformation restoreFromDDB(String userid) {
List<dynamodb.Item> splittedItems = new ArrayList<dynamodb.Item>();
dynamodb.Item currentItem = table.getItem(“UserId”, userid); splittedItems.add(currentItem);
while((String nextPos = currentItem.getString(“NextPos”)) != null) {
currentItem = table.getItem(“UserId”, nextPos); splittedItems.add(currentItem);
}
return DynamoDBMapper.convertToUserItem(splittedItems);
}
하나의 Instance를
DynamoDB Item으로 Split하
여 한꺼번에 저장
여러개의 DynamoDB Item을
추적하여, 뭉친다음 하나의
Instance로 제공](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-49-2048.jpg)
![주요 주제
않좋은 예시 – DDB Table
게임의 로그인 부터 사용자의 모든 데이터를 하나의 Row에 대응
개인별 로그성 데이터의 누적 및 관리
한번에 모든 데이터를 읽어서 Application이 관리
쓰기는 중요도에 따라 Batch형태, 또는 실시간으로 수행
On the fly data loss에 대한 Reconstruction 을 위한 Application 로직 중요
ID(Part) VALID NAME PWD LOGHIST ACCID 기타등등
USER001 YES HANK 202cb…
[“2019-12-31 14:..”,
“2020-01-03
16:1…”,…]
USER002 YES IGUANA 962ac… [“2020-01-14 15:..”,
“2020-01-23
17:1…”,…]
03-240-X
USER004 NO LILY 59075…
[“2020-01-30 17:..”,
“2020-02-03
16:1…”,…]
01-210-X](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-50-2048.jpg)
![주요 주제
않좋은 예시 – DDB Table
[설계 원칙]
1 사용자 정보는 1 ROW 이상으로 구성됩니다.
400KB/ row – data split read/ write: 400KB가 넘어가면 끝에 continue할 Key값을
추가하여 다음 ROW를 알 수 있고, 이를 활용하여 이어 읽기가 가능해 집니다.
읽을 때는 모두 다 읽고, 쓸 때도 모든 데이터를 한번에 Flush 하는 형태가 됩니다.
ID(Part) VALID NAME PWD LOGHIST 기타데이터 NEXTROW
USER001 YES HANK 202cb…
[“2019-12-31 14:..”,
“2020-01-03 16:1…”,…] [“aaa”, …] USER001-p13
ID(Part) VALID DEX GOLD LASTPOS NEXTROW
USER001-p13 YES 16 47782 [12345,77863,43]
END](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-51-2048.jpg)



![주요 주제
데이터의 특성 이해
데이터를 온전히 파악할 필요가 있습니다
데이터를 어떤 빈도로, 어떤 의도로 접근할지 알아야합니다
[예시]
읽기가 잦은 데이터 – ID/ PWD
쓰기/갱신이 잦은 데이터 – Character 속성, ITEM
유효기간이 있는 데이터 – LOG성 데이터들
기타 등등](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-55-2048.jpg)
![주요 주제
데이터 컬럼 그룹핑
사용자 초기 로그인 시에 활용되는 컬럼
ID PWD NAME
USER001 YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID DEX GOLD ITEMS
USER001 YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간이 지나면, 제거해야 하는 자료들
ID LOGHIST
USER001 [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]
ID(Part) VALID NAME PWD LOGHIST ITEMS NEXTROW
USER001 YES HANK 202cb… [“2019-12-31 14:..”,
“2020-01-03 16:1…”,…]
[“aaa”, …] USER001-p13
ID(Part) VALID DEX GOLD LASTPOS NEXTROW
USER001-p13 YES 16 47782 [12345,77863,43] END](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-56-2048.jpg)
![주요 주제
레코드 분리 검증
단일 레코드를 여러개의 컬럼 그룹으로 구분하여, 레코드를 생성할 수도 있으며,
LSI, GSI를 이용하여 구현할 수도 있습니다. 제일 중요한 판단 기준은 해당 자료의
생성/조회 시점에 같이 이용이 필요한지에 따라 다릅니다.
• 사용자 초기 로그인 시에 활용되는 컬럼
ID PWD NAME
USER001 YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID DEX GOLD ITEMS
USER001 YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간후 삭제
ID LOGHIST
USER001 [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]
사용자 등록/로그인시에만 주로
활용됩니다. 즉 독립적인 레코드로
구성해도 좋습니다.
게임 진행이 종료될 경우, 또는 주기적으로
저장할 경우, 활용됩니다. 다른 컬럼과의
종속관계가 낮아 독립적인 레코드 구성 O
시간대에 따른 추가 Record가 생성이 되며,
TTL적용을 위하여 독립 레코드 구성에
적합함](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-57-2048.jpg)
![주요 주제
분리된 레코드의 Sort Key 설계
일단, 분리된 레코드에 Sort Key를 제공하여, Primary Key를 구성하여, 개별 Record
로 인식할 수 있게 하며, 조회 조건을 고려하여 Composite SortKey로 추가 조회 조
건으로 활용할 수 있게 제공
• 사용자 초기 로그인 시에 활용되는 컬럼
ID SK(SortKey) PWD NAME
USER001 “LOGIN” YES HANK
자주 내용이 변경되면서, 조회가 빈번하게 발생하는 경우.
ID SK(SortKey) DEX GOLD ITEMS
USER001 ‘ServerId’+’:” + ‘CharId’ YES HANK [{itemcd : “guntlet”, amount : 2...}]
히스토리 성의 자료로, 추가가 되면서, 특정 기간후 삭제
ID SK(SortKey) LOGHIST
USER001 “LOG”+‘:’+‘ServerId’+’:”+‘Serial’ [“2019-12-31 14:..”, “2020-01-03 16:1…”,…]](https://image.slidesharecdn.com/awsbuildersaws300nosql-240831060235-353a1124/75/AWS-Builders_AWS-300_NoSQL-pdf-58-2048.jpg)












![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











![[스마트스터디]모바일 애플리케이션 서비스에서의 로그 수집과 분석](https://cdn.slidesharecdn.com/ss_thumbnails/redismongodbmysql-171107063045-thumbnail.jpg?width=640&height=640&fit=bounds)




