DBMS의 특징
- 데이터의무결성: 데이터에 오류가 있어서는 안된다
- 데이터의 독립성: DB의 크기를 변경하거나 저장소를
변경해도 기존에 작성한 응용 프로그램은 전혀 영향을
받지 않음
- 보안: DB에 아무나 접근하지 않고 계정에 따라 권한을
다르게 함
- 데이터 중복의 최소화
8.
DBMS의 종류
- 계층형(Hierarchical)데이터베이스 관리 시스템
- 네트워크(Network) 데이터베이스 관리 시스템
- 관계형(Relational) 데이터베이스 관리시스템
- 객체지향형(Object Oriented) 데이터베이스 관리 시스템
- NoSQL
9.
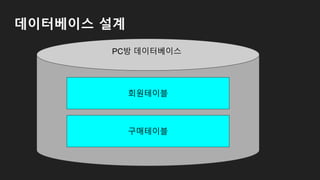
RDBMS(Relational Database ManagementSystem)
- 데이터베이스 테이블이라는 최소 단위로 구성
- 테이블은 하나이상의 열로 구성
ID 닉네임 직업
zzang 짱구 전사
hun 훈이 궁수
chul 철수 마법사
행(로우)
열(컬럼)
열이름
※ 테이블을 릴레이션 또는 엔티티라고도 부름
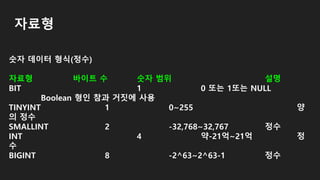
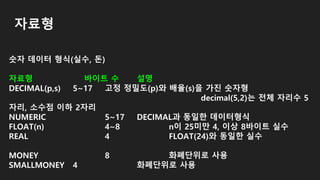
자료형
숫자 데이터 형식(정수)
자료형바이트 수 숫자 범위 설명
BIT 1 0 또는 1또는 NULL
Boolean 형인 참과 거짓에 사용
TINYINT 1 0~255 양
의 정수
SMALLINT 2 -32,768~32,767 정수
INT 4 약-21억~21억 정
수
BIGINT 8 -2^63~2^63-1 정수
19.
자료형
숫자 데이터 형식(실수,돈)
자료형 바이트 수 설명
DECIMAL(p,s) 5~17 고정 정밀도(p)와 배율(s)을 가진 숫자형
decimal(5,2)는 전체 자리수 5
자리, 소수점 이하 2자리
NUMERIC 5~17 DECIMAL과 동일한 데이터형식
FLOAT(n) 4~8 n이 25미만 4, 이상 8바이트 실수
REAL 4 FLOAT(24)와 동일한 실수
MONEY 8 화폐단위로 사용
SMALLMONEY 4 화폐단위로 사용
20.
자료형
문자 데이터 형식
자료형바이트 수 설명
CHAR(n) 0~8000 고정형 문자형
NCHAR(n) 0~8000 글자로는 0~4000자, 유니코드
고정 길이 문자형
VARCHAR(n|max) 0~2GB 가변길이 문자형
NVARCHAR(n|max) 0~2GB 유니코드 가변길이 문자형
BINARY(n) 0~8000 고정형 이진 데이터값
NVARBINARY(n|max)0~2GB 가변길이 이진 데이터값, 이미지/동영
상 등 저장
21.
자료형
날짜와 시간
자료형 바이트수 설명
DATETIME 8 날짜 1753-1-1~9999-12-31
까지 저장,
시간 00:00:00~23:59:59.997까지 저장
형식은 YYYY-MM-DD 시:분:초
밀리초(1/1000초) 단위까지 인식
DATETIME2 6~8 DATETIME 확장형 (100나노
초 단위까지 인식)
DATE 3 0001-1-1~9999-12-31까지
저장
TIME 5
DDL(Data Definition Language)
데이터베이스 개체를 생성/변경/삭제하는 역할을 하는 언어
CREATE, DROP, ALTER
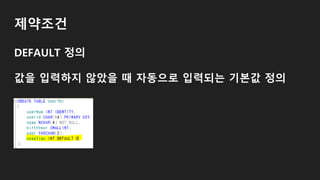
DCL(Data Control Language)
데이터베이스에 접근하거나 객체에 권한을 주는 등 역할을
하는 언어
GRANT, REVOKE, COMMIT, ROLLBACK
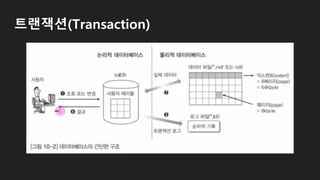
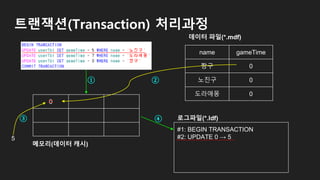
트랜잭션(Transaction) 처리과정
5 00
name gameTime
짱구 0
노진구 0
도라애몽 0
#1: BEGIN TRANSACTION
#2: UPDATE 0 → 5
#3: UPDATE 0 → 7
#4: UPDATE 0 → 3
로그파일(*.ldf)
메모리(데이터 캐시)
데이터 파일(*.mdf)
7
①
②
③
④
3
51.
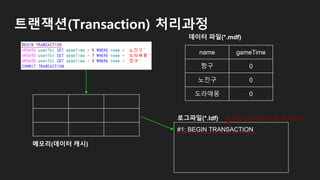
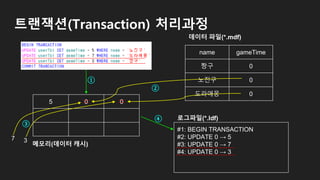
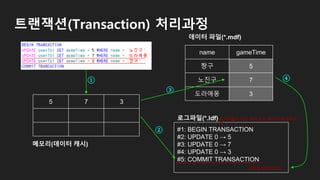
트랜잭션(Transaction) 처리과정
5 73
name gameTime
짱구 5
노진구 7
도라애몽 3
#1: BEGIN TRANSACTION
#2: UPDATE 0 → 5
#3: UPDATE 0 → 7
#4: UPDATE 0 → 3
#5: COMMIT TRANSACTION
로그파일(*.ldf)
메모리(데이터 캐시)
데이터 파일(*.mdf)
①
②
③
④
로그파일의 시작 위치 또는 마지막 체크포인
트
새로운 체크포인트
52.
트랜잭션(Transaction)의 특징
- 원자성:트랜잭션에 포함되는 모든 작업이 성공적으로 처
리되지 않으면 어떤 작업도 처리되지 않아야함
- 일관성: 시작되기 전과 종료 후 DB가 올바르고 일관된 상
태가 되도록 처리되어야 함
- 고립성: 한 트랜잭션에서 DB를 변경한 내용은 커밋될 때
까지 다른 어떤 질의나 트랜잭션과도 고립되어야 함
- 영속성: 일단 커밋 후 트랜잭션에 의해 변경된 내용은 영
구적이어야 한다.
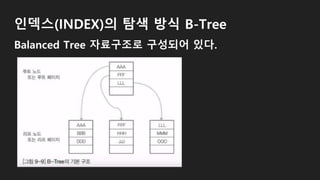
인덱스(INDEX) 종류와 특징
클러스터형인덱스: 영어 사전과 같이 책 내용 자체가 순서대
로 정렬되어 있는 형태, 테이블당 한 개만 생성 가능
비클러스터형 인덱스: 책 위에 <찾아보기>가 있는 일반책과
같이 되어있는 형태, 테이블당 여러 개 생성 가능
클러스터형 인덱스는 행 데이터를 인덱스로 지정한 열에 맞
춰 자동 정렬
62.
자동으로 생성되는 인덱스(INDEX)
인덱스는테이블의 열 단위에 생성된다.
제약조건의 PRIMARY KEY로 생성하면 클러스터형 인덱스가
자동으로 생성
userId를 PRIMARY KEY로
지정하였기에 정렬된 테이블
63.
자동으로 생성되는 인덱스(INDEX)
제약조건의UNIQUE로 생성할 경우 비클러스터형 인덱스로
생성
즉, 자동으로 인덱스를 생성해주는 제약 조건은
PRIMARY KEY와 UNIQUE 뿐이다.
64.
인덱스(INDEX) 생성
테이블을 생성할때
CREATE TABLE
(
열이름 자료형 제약조건
CLUSTERED|NONCLUSTERED
)
PRIMARY KEY의 경우에도 명시적으로 비클러스터형 인덱스
를 줄 수 있다.












![데이터베이스 생성(CREATE DATABASE)
CREATE DATABASE [데이터베이스명]](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-13-320.jpg)
![데이터베이스 선택(USE)
USE [데이터베이스명]](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-14-320.jpg)

![테이블 생성하기(CREATE TABLE)
CREATE TABLE [테이블명]
(
열이름1 자료형 제약조건,
열이름2 자료형 제약조건,
열이름3 자료형 제약조건
);](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-17-320.jpg)







![데이터 추가하기(INSERT INTO)
INSERT INTO [테이블명] VALUES(값들…)](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-28-320.jpg)
![테이블 삭제하기(DROP TABLE)
DROP TABLE [테이블명]
위 개그를 더 자세히 이해하기 위해서는 SQL 인젝션에 대해 알아볼 필요가 있습니다](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-29-320.jpg)
![테이블 조회(SELECT ~ FROM ~)
SELECT [컬럼명] FROM [테이블명]
*을 붙일 경우 모든 컬럼(열)을 출력](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-30-320.jpg)

![컬럼에 별칭 붙이기(AS)
SELECT [컬럼명] AS [별칭] FROM [테이블명]](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-32-320.jpg)
![테이블 조회 조건(WHERE)
SELECT [컬럼명] FROM [테이블명] WHERE [조건]](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-33-320.jpg)
![원하는 순서대로 정렬하여 출력(ORDER BY)
SELECT [컬럼명] FROM [테이블명]
ORDER BY [정렬 대상 컬럼명]](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-34-320.jpg)

![묶어서 조회 (GROUP BY)
SELECT ~ FROM ~ GROUP BY [묶을 컬럼]
이때 사용한 SUM은 집계함수. 액셀에서 SUM AVG등 동
일한 기능을 하는 함수가 SQL에도 존재.](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-36-320.jpg)
![데이터의 수정 (UPDATE)
UPDATE [테이블명]
SET [열1 = 값1], [열2 = 값2] …
WHERE [조건]
조건을 안쓰면 모든 열의 값이 변경됨](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-37-320.jpg)
![데이터 삭제 (DELETE)
DELETE [테이블명] WHERE [조건]
조건을 안쓰면 모든 행데이터 삭제](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-38-320.jpg)










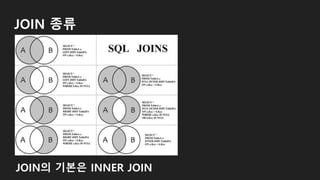
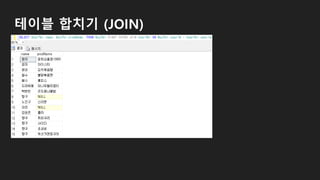
![테이블 합치기 (JOIN)
SELECT [조회를 원하는 컬럼] FROM [A테이블]
JOIN [B테이블] ON 합치는 조건](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-54-320.jpg)
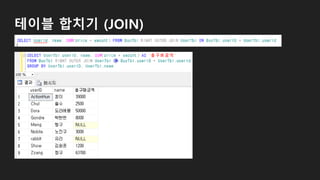
![테이블 합치기 (JOIN)
SELECT [조회를 원하는 컬럼] FROM [A테이블]
JOIN [B테이블] ON 합치는 조건](https://image.slidesharecdn.com/181215mssqldatabase-181217012212/85/181215-MS-SQL-55-320.jpg)