Recommended
PDF
第73回 Machine Learning 15minutes ! IBM AI Foundation Modelsへの取り組み
PDF
Tokyo H2O.ai Meetup#2 by Iida
PDF
[Developers Summit 2017] MicrosoftのAI開発機能/サービス
PPTX
PPTX
Connect 2018 in Koriyama, with UDC - Microsoft AI Session
PDF
Azure Machine Learning� getting started
PDF
Watson.assistant chat bot-20200117
PPTX
PPTX
東北大学AIE - 機械学習中級編とAzure紹介
PDF
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
PDF
機械学習プロジェクトにおける Cloud AI Platform の使い方 (2018-11-19)
PDF
[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~
PPTX
1028 TECH & BRIDGE MEETING
PPTX
PDF
Amazonでのレコメンド生成における深層学習とAWS利用について
PPTX
PPTX
PDF
業界ごとのデータ分析を支援するIBM Data and AI Acceleratorsのご紹介
PPTX
20140711 evf2014 hadoop_recommendmachinelearning
PDF
アイコンで組み立てる Spark MLlib + ETLプログラム
PDF
kintone Cafe Japan 2016: kintone x 機械学習で実現する簡単名刺管理
PPTX
AIシステムの要求とプロジェクトマネジメント-前半:機械学習工学概論
PDF
Watson API トレーニング 20160716 rev02
PDF
PPTX
機械学習を使った「ビジネスになる」アプリケーションの作り方 V2
PPTX
機械学習を使った「ビジネスになる」アプリケーションの作り方 v1
PDF
[teratail Study ~機械学習編#2~] Microsoft AzureのAI関連サービス
PPTX
Microsoft AI セミナー - Microsoft AI Platform
PDF
PPTX
Drupal9 update (0214/2020)
More Related Content
PDF
第73回 Machine Learning 15minutes ! IBM AI Foundation Modelsへの取り組み
PDF
Tokyo H2O.ai Meetup#2 by Iida
PDF
[Developers Summit 2017] MicrosoftのAI開発機能/サービス
PPTX
PPTX
Connect 2018 in Koriyama, with UDC - Microsoft AI Session
PDF
Azure Machine Learning� getting started
PDF
Watson.assistant chat bot-20200117
PPTX
Similar to Auto ai workshop
PPTX
東北大学AIE - 機械学習中級編とAzure紹介
PDF
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
PDF
機械学習プロジェクトにおける Cloud AI Platform の使い方 (2018-11-19)
PDF
[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~
PPTX
1028 TECH & BRIDGE MEETING
PPTX
PDF
Amazonでのレコメンド生成における深層学習とAWS利用について
PPTX
PPTX
PDF
業界ごとのデータ分析を支援するIBM Data and AI Acceleratorsのご紹介
PPTX
20140711 evf2014 hadoop_recommendmachinelearning
PDF
アイコンで組み立てる Spark MLlib + ETLプログラム
PDF
kintone Cafe Japan 2016: kintone x 機械学習で実現する簡単名刺管理
PPTX
AIシステムの要求とプロジェクトマネジメント-前半:機械学習工学概論
PDF
Watson API トレーニング 20160716 rev02
PDF
PPTX
機械学習を使った「ビジネスになる」アプリケーションの作り方 V2
PPTX
機械学習を使った「ビジネスになる」アプリケーションの作り方 v1
PDF
[teratail Study ~機械学習編#2~] Microsoft AzureのAI関連サービス
PPTX
Microsoft AI セミナー - Microsoft AI Platform
More from Yasushi Osonoi
PDF
PPTX
Drupal9 update (0214/2020)
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PPTX
PPTX
Drupal haneda-2019-07-osonoi
PDF
PDF
Drupal on ibm_cloud_20160630
PDF
PPTX
プレゼン インフラエンジニア、アプリ開発者集まれ!今注目のクラウド 「Bluemix」、「soft layer」をはじめよう!(OSC福岡2015)
PPT
Drupal on bluemix20150902
PDF
Drupal overview @ Microsoft Azure on 1/19/2015
PPT
IBM SoftLayer @ Osc tokyo-2014-fall
PPT
PPTX
Auto ai workshop 1. 2. 2IBM Developer Advocacy 2019
機械学習 Hands-on 本日の概要
Watson StudioとWatson Machine Learningサービスを連携し、機械学習モデルを作成します。
作成したモデルをサービスとして公開し、外部からアクセスし結果を判定します。
作成するモデルは二値分類モデルと、回帰モデルの二種類です。
https://www.ibm.com/cloud/garage/dte/tutorial/ibm-watson-studio-autoai-modeling-rest-us
3. 3IBM Developer Advocacy 2019
本日の概要
Watson StudioとWatson Machine Learningサービスを連携し、機械学習モデルを作成します。
作成したモデルをサービスとして公開し、外部からアクセスし結果を判定します。
作成するモデルは二値分類モデルと、回帰モデルの二種類です。
https://www.ibm.com/cloud/garage/dte/tutorial/ibm-watson-studio-autoai-modeling-rest-us
4. 4IBM Developer Advocacy 2019
機械学習について
• 回帰 (Regression): 過去のデータから何かの値を予測する、教師あり学習に含まれます。
• 二値分類 (Binary Classification): 与えられたインプットが2つのクラスのうちどちらに分類されるか。
5. 6. 6IBM Developer Advocacy 2019
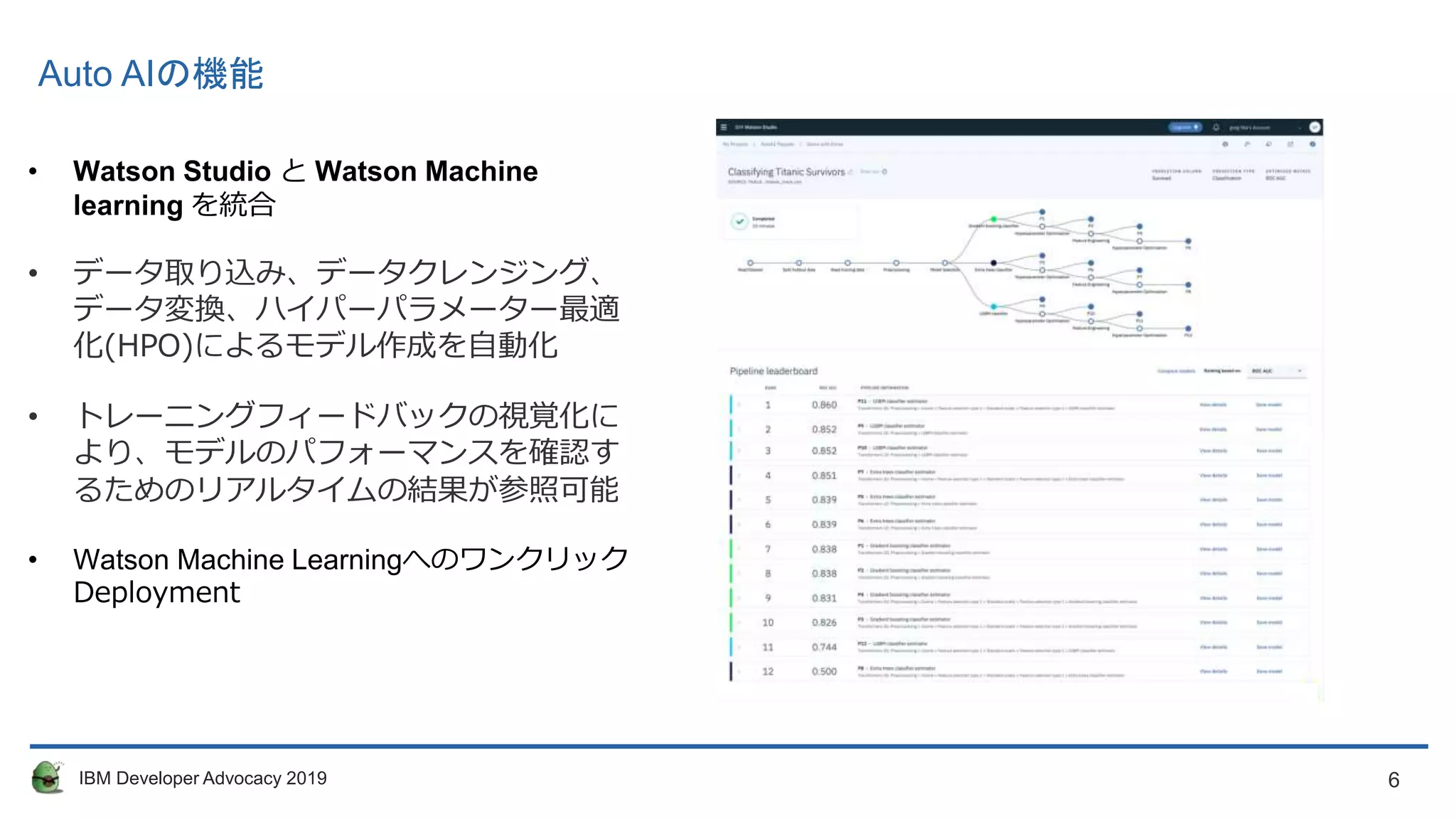
Auto AIの機能
• Watson Studio と Watson Machine
learning を統合
• データ取り込み、データクレンジング、
データ変換、ハイパーパラメーター最適
化(HPO)によるモデル作成を自動化
• トレーニングフィードバックの視覚化に
より、モデルのパフォーマンスを確認す
るためのリアルタイムの結果が参照可能
• Watson Machine Learningへのワンクリック
Deployment
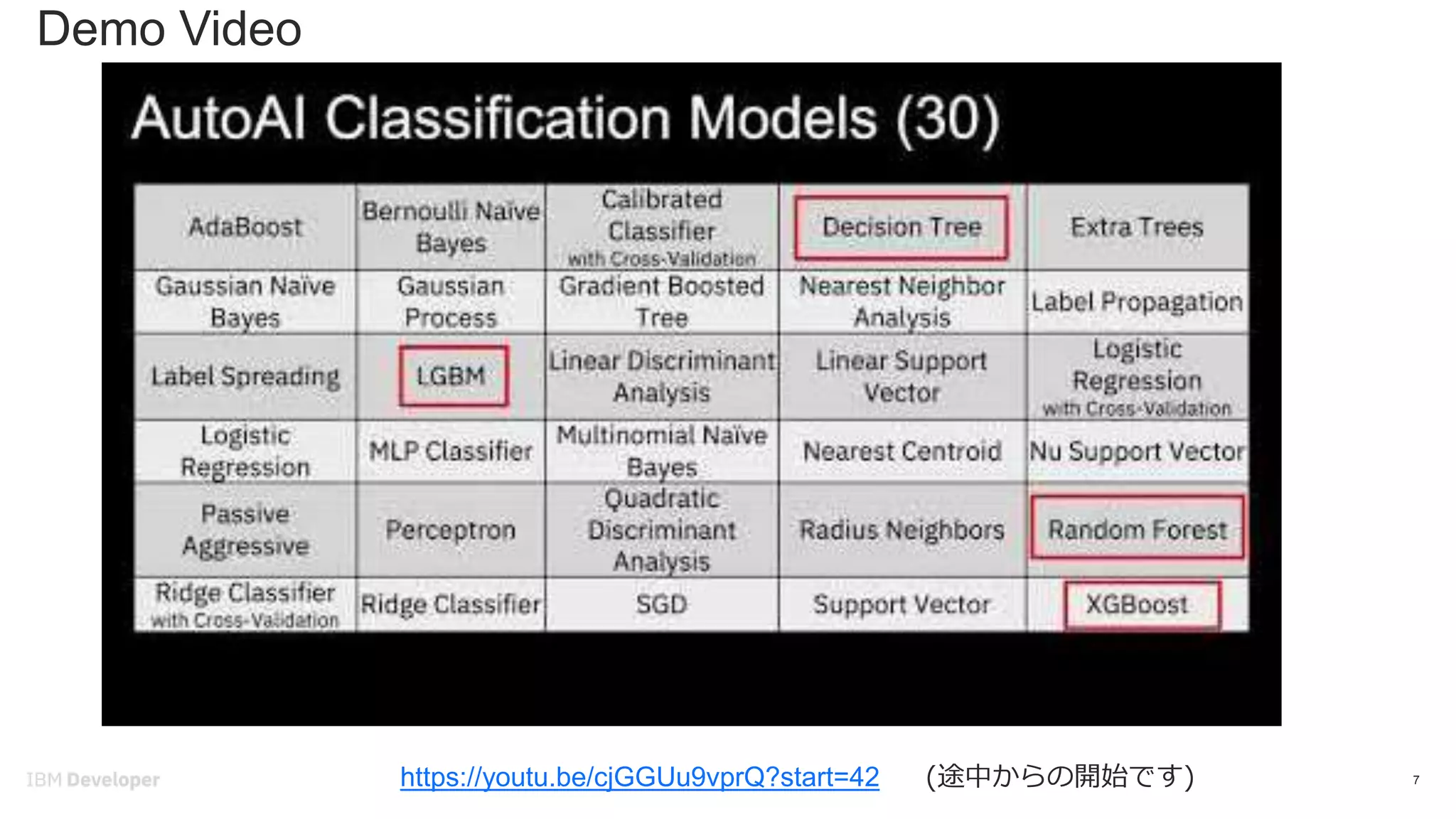
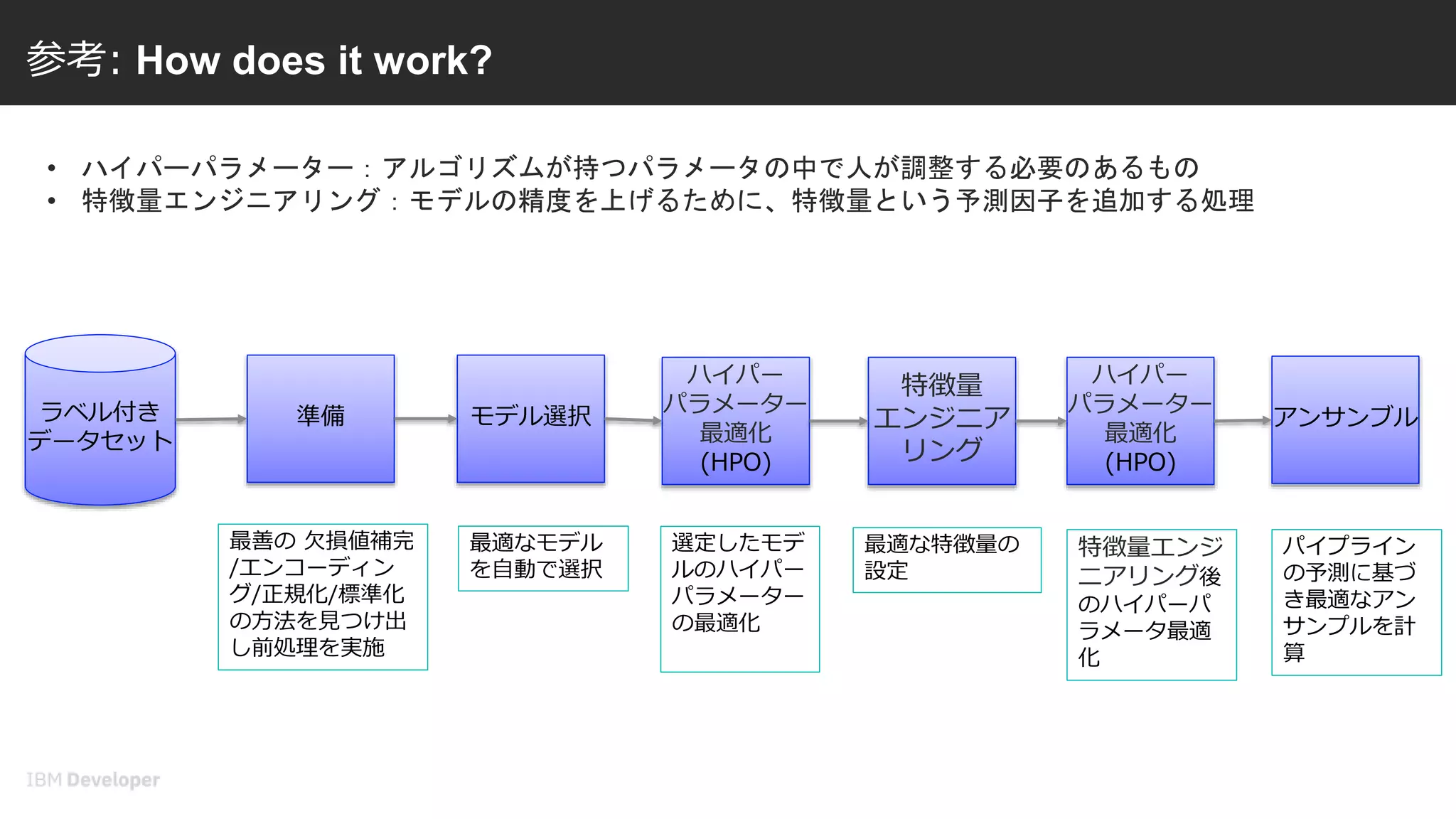
7. 8. 参考: How does it work?
ラベル付き
データセット
準備 モデル選択
ハイパー
パラメーター
最適化
(HPO)
特徴量
エンジニア
リング
ハイパー
パラメーター
最適化
(HPO)
アンサンブル
最善の 欠損値補完
/エンコーディン
グ/正規化/標準化
の方法を見つけ出
し前処理を実施
最適なモデル
を自動で選択
選定したモデ
ルのハイパー
パラメーター
の最適化
特徴量エンジ
ニアリング後
のハイパーパ
ラメータ最適
化
最適な特徴量の
設定
パイプライン
の予測に基づ
き最適なアン
サンプルを計
算
• ハイパーパラメーター:アルゴリズムが持つパラメータの中で人が調整する必要のあるもの
• 特徴量エンジニアリング:モデルの精度を上げるために、特徴量という予測因子を追加する処理
9. 9IBM Developer Advocacy 2019
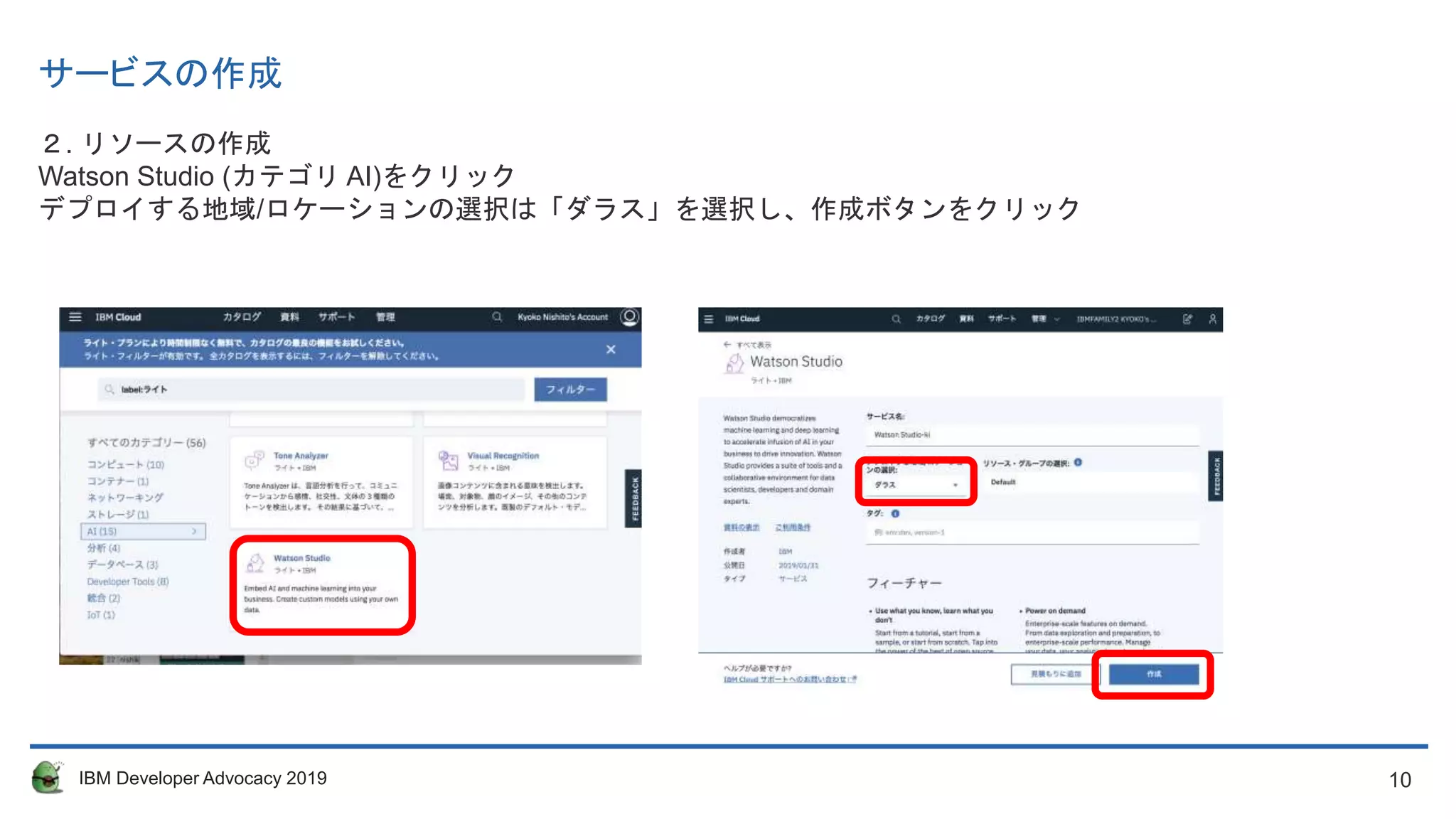
サービスの作成
まずはIBM Cloud上で、Watson Studioのサービスを作成します。
前回のハンズオンで実施済みの方はスキップしてください。
1. 「カタログ」をクリック
10. 11. 11IBM Developer Advocacy 2019
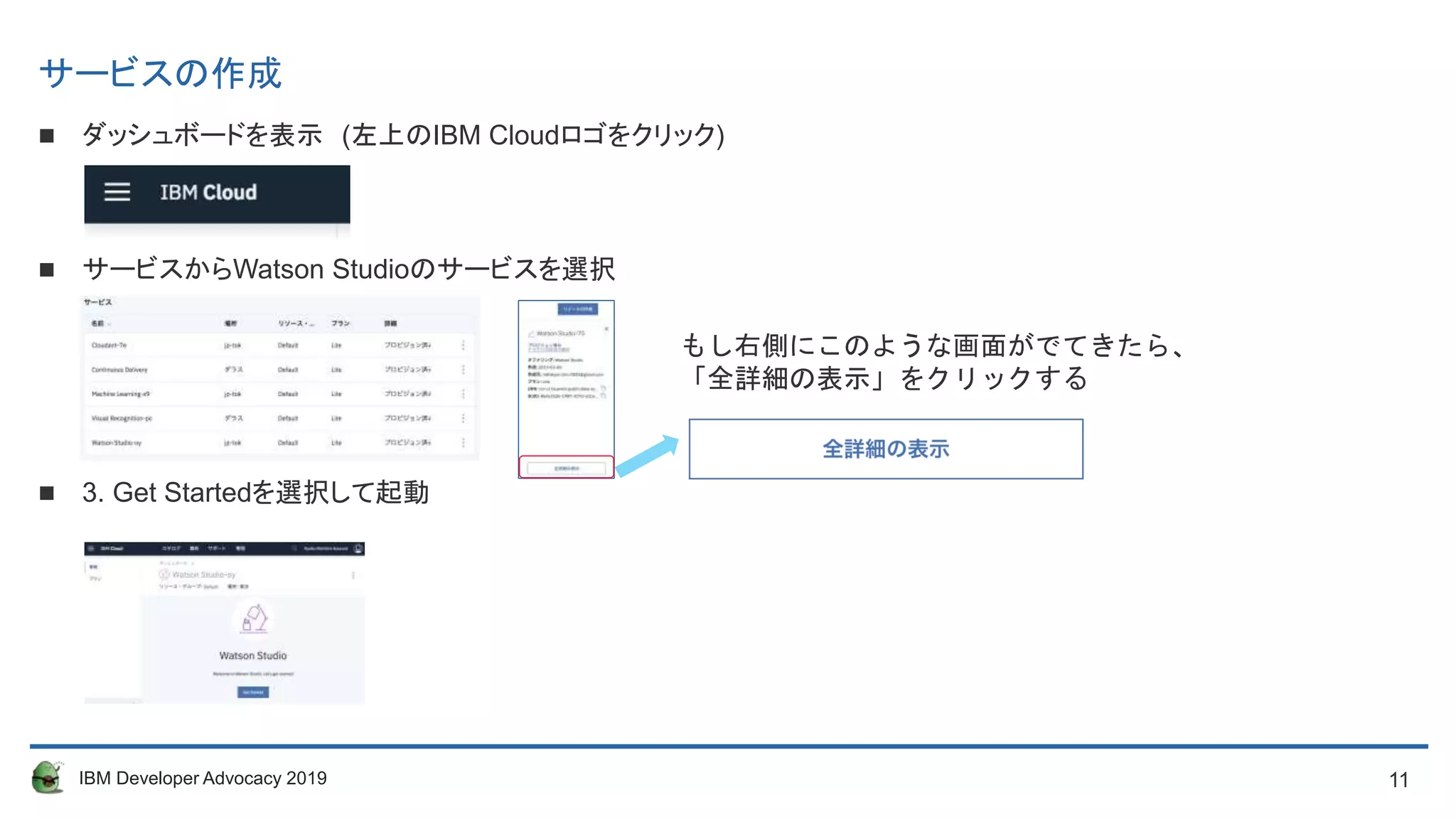
サービスの作成
ダッシュボードを表示 (左上のIBM Cloudロゴをクリック)
サービスからWatson Studioのサービスを選択
3. Get Startedを選択して起動
もし右側にこのような画面がでてきたら、
「全詳細の表示」をクリックするもし右側にこのような画面がでてきたら、
「全詳細の表示」をクリックする
12. 12IBM Developer Advocacy 2019
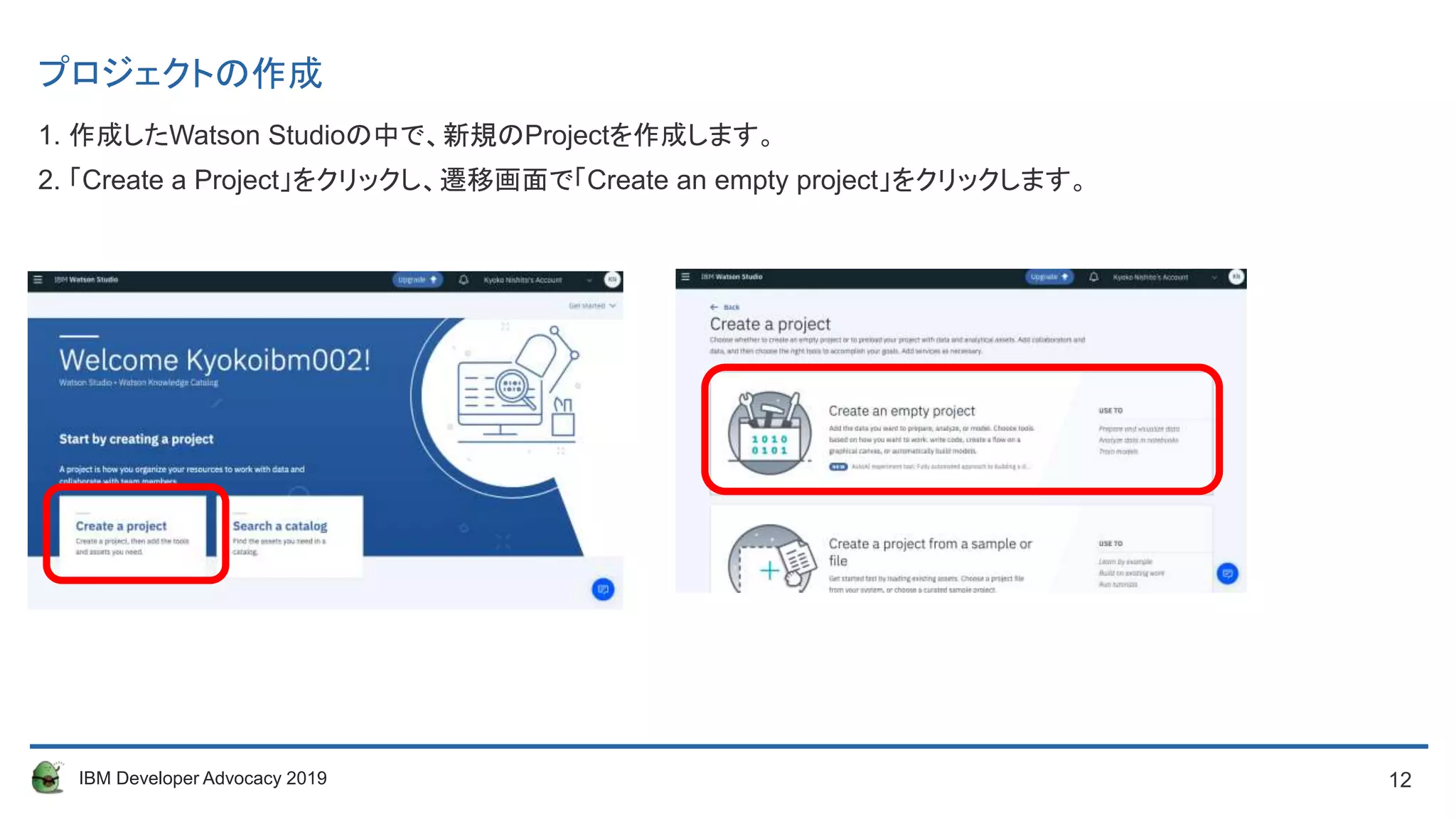
プロジェクトの作成
1. 作成したWatson Studioの中で、新規のProjectを作成します。
2. 「Create a Project」をクリックし、遷移画面で「Create an empty project」をクリックします。
13. 13IBM Developer Advocacy 2019
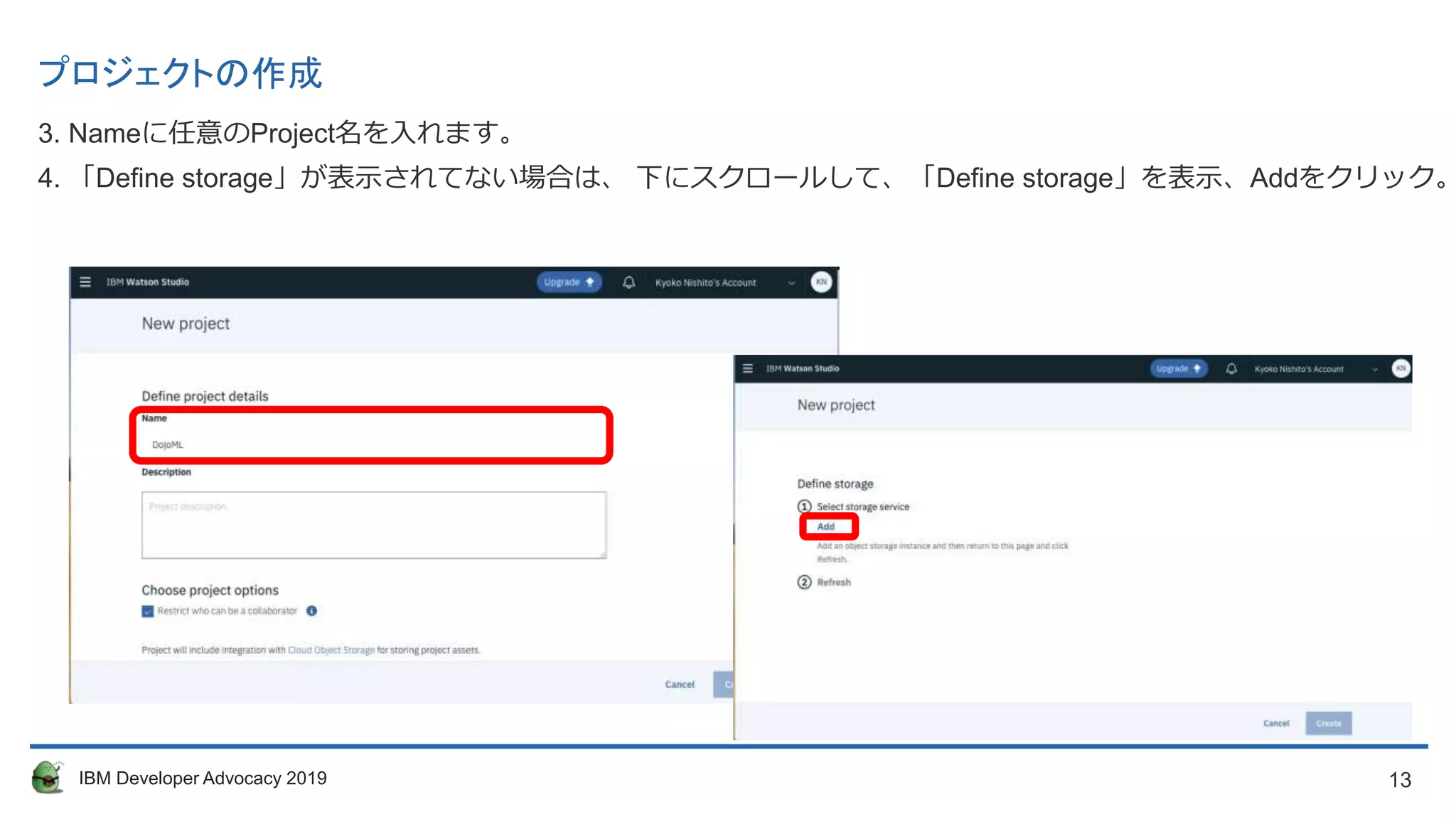
プロジェクトの作成
3. Nameに任意のProject名を入れます。
4. 「Define storage」が表示されてない場合は、 下にスクロールして、「Define storage」を表示、Addをクリック。
14. 14IBM Developer Advocacy 2019
プロジェクトの作成
Liteが選択されていることを確認して[Create]をクリックします。
Confirm Creationのダイアログはそのまま[Confirm]をクリックします。
15. 15IBM Developer Advocacy 2019
プロジェクトの作成
New Projectの画面になるので、 Define Storage の②Refreshをクリックします 。
Storageが表示された後、[Create]をクリックします。
16. 16IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[Settings]をクリックします。
Associated servicesから[+Add services]をクリックして[Watson]を選択]を選択
17. 17IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[New]のタブが選択された画面が表示された場合
- 1. スクロールしてPLANでLiteが選択されていることを確認して一番下の[Create]をクリック 。
- 2. Confirmの画面でRegionがDallasになっていることを確認して[Confirm]をクリック
18. 18IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[Settings] の画面に戻ります。
Associated servicesに追加したサービスのインスタンスが追加されていることを確認します。
19. 19IBM Developer Advocacy 2019
これで準備は完了です。
次のぺージ、Creating an AutoAI model for binary classificationから進めていきましょう。
年齢、年収、使用状況から電話回線を解約するかどうかを予測する機械学習モデルを作成します
以下のサイトの内容と同様です。
https://www.ibm.com/cloud/garage/dte/tutorial/ibm-watson-studio-autoai-modeling-rest-us
20. 20IBM Developer Advocacy 2019
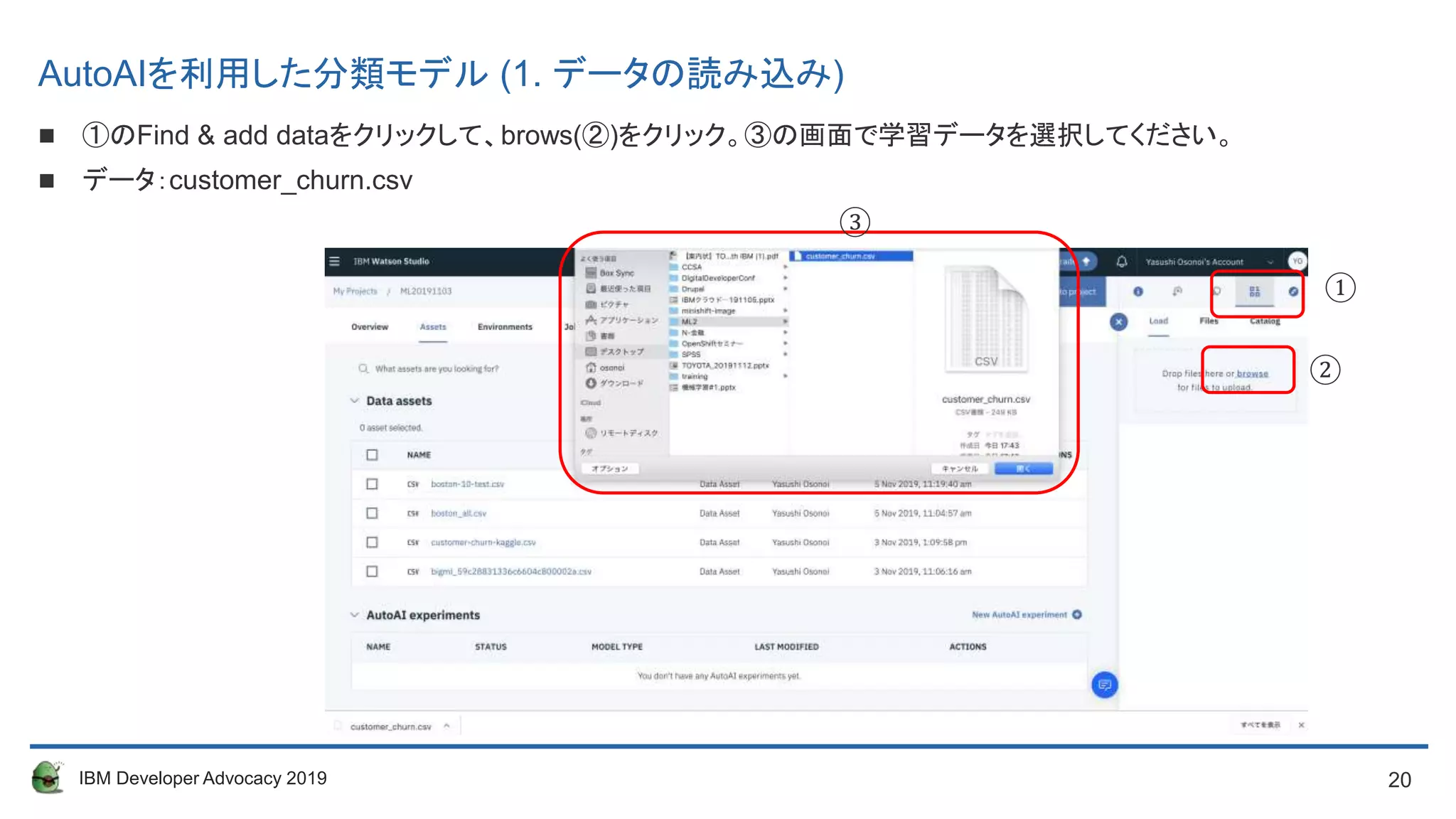
AutoAIを利用した分類モデル (1. データの読み込み)
①のFind & add dataをクリックして、brows(②)をクリック。③の画面で学習データを選択してください。
データ:customer_churn.csv
①
②
③
21. 22. 23. 23IBM Developer Advocacy 2019
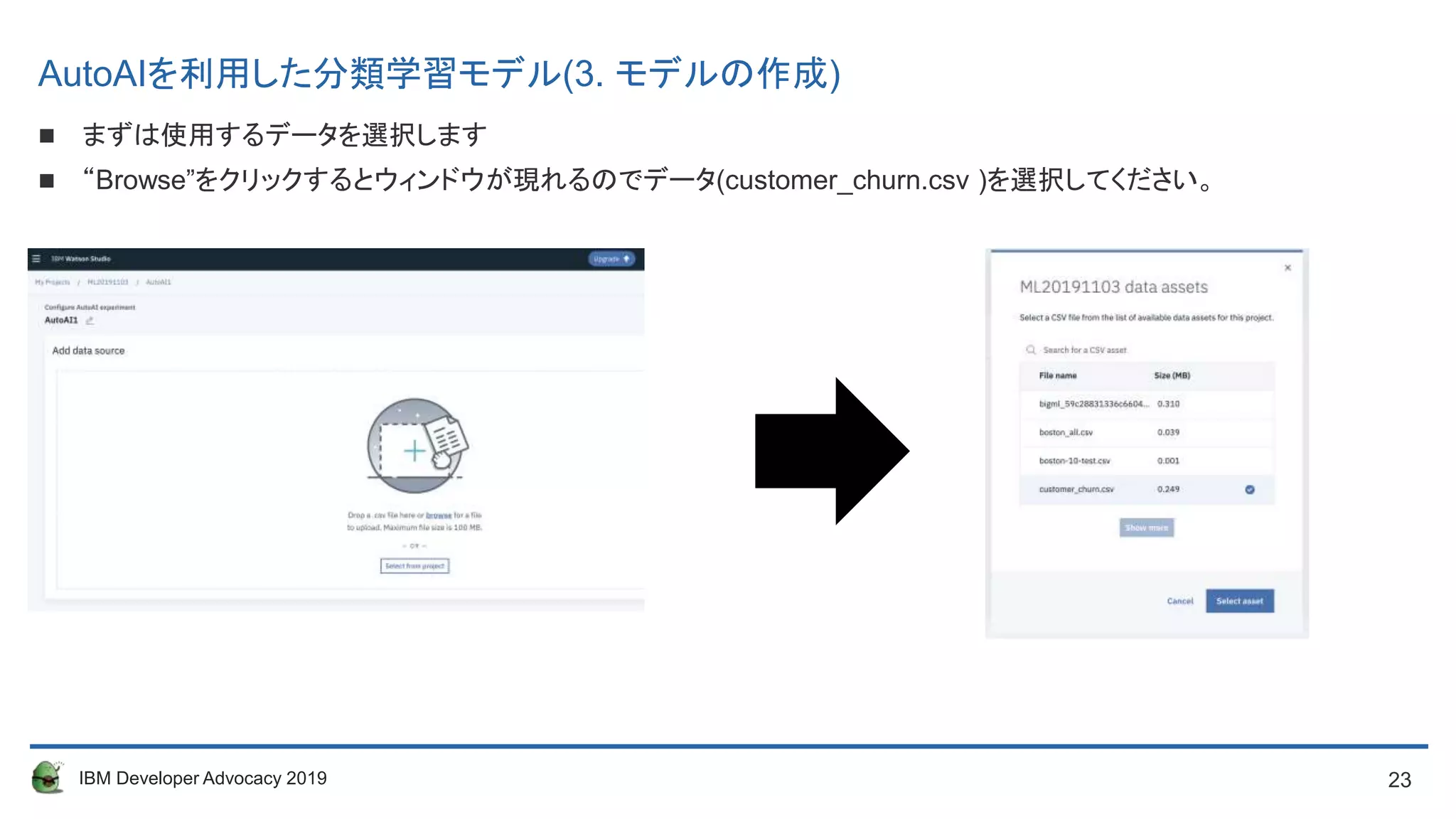
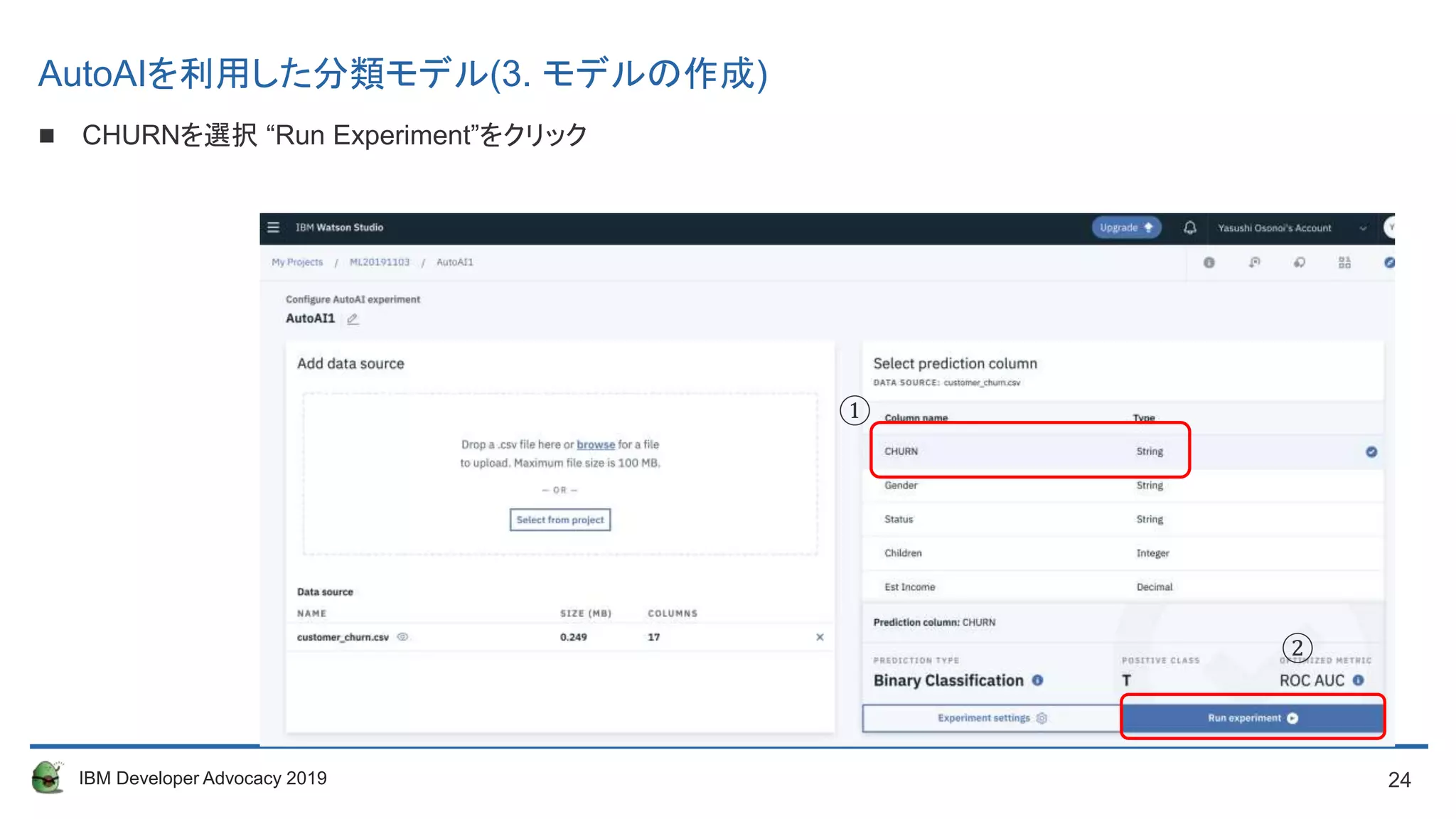
AutoAIを利用した分類学習モデル(3. モデルの作成)
まずは使用するデータを選択します
“Browse”をクリックするとウィンドウが現れるのでデータ(customer_churn.csv )を選択してください。
24. 25. 26. 26IBM Developer Advocacy 2019
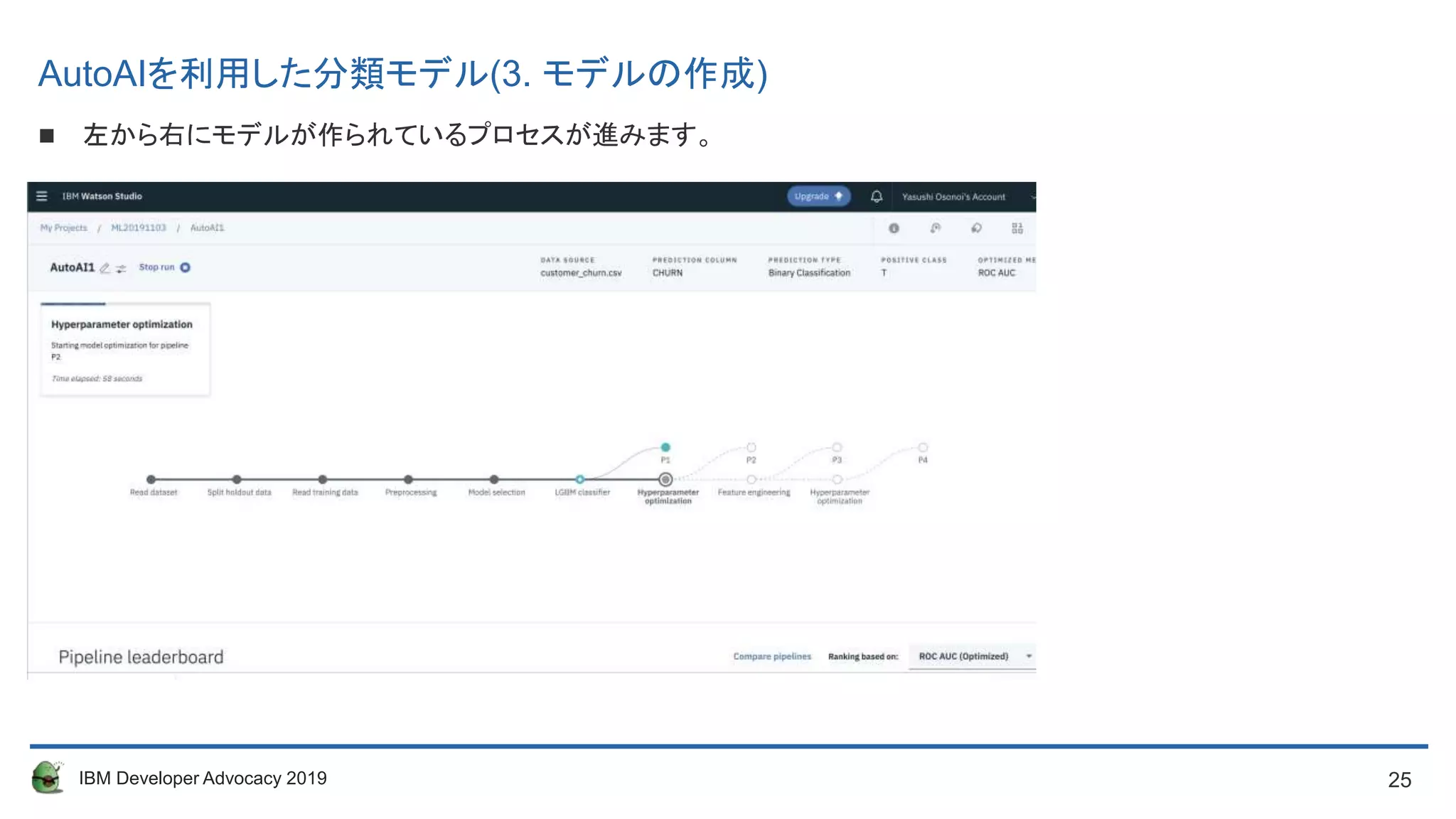
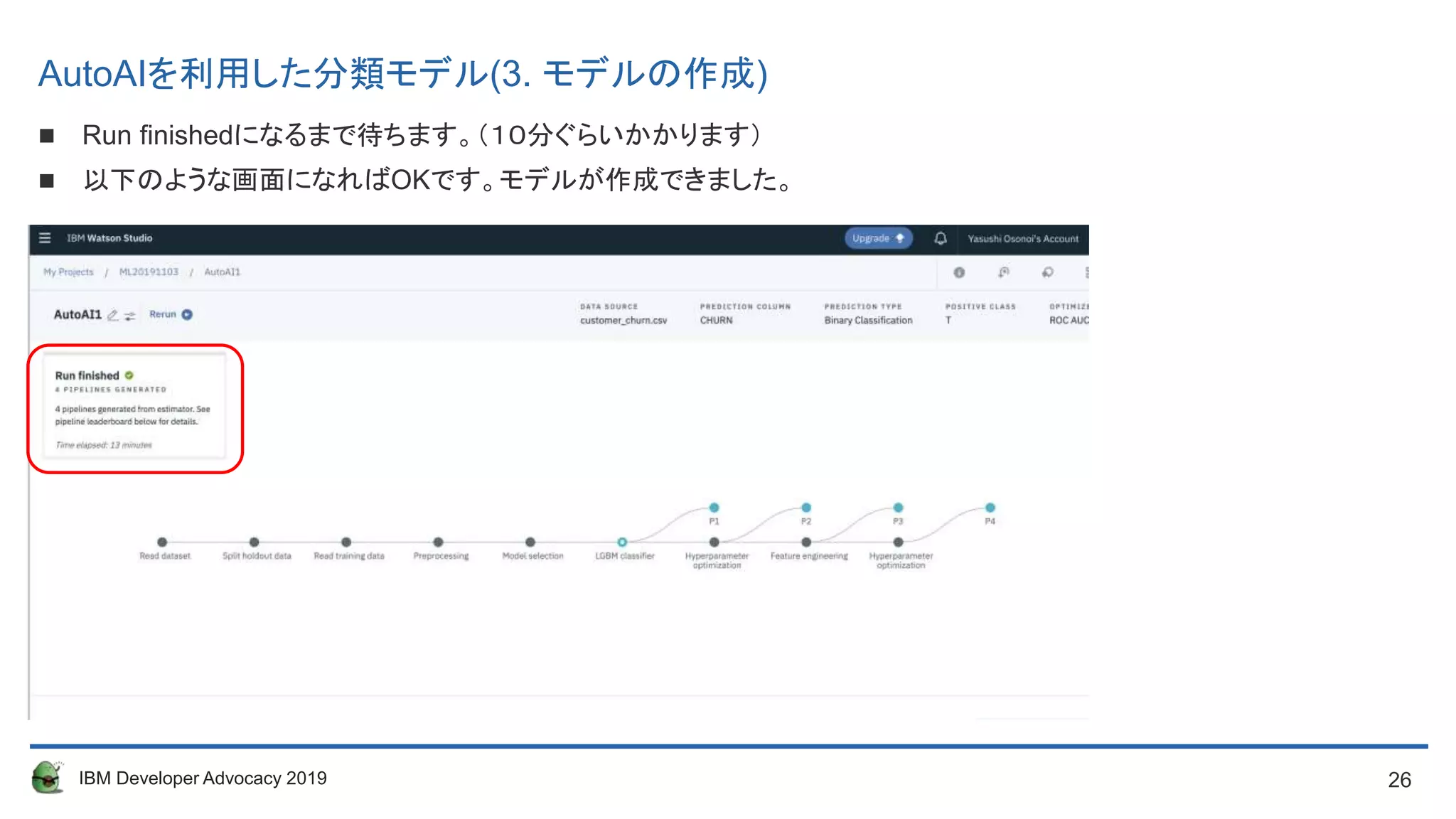
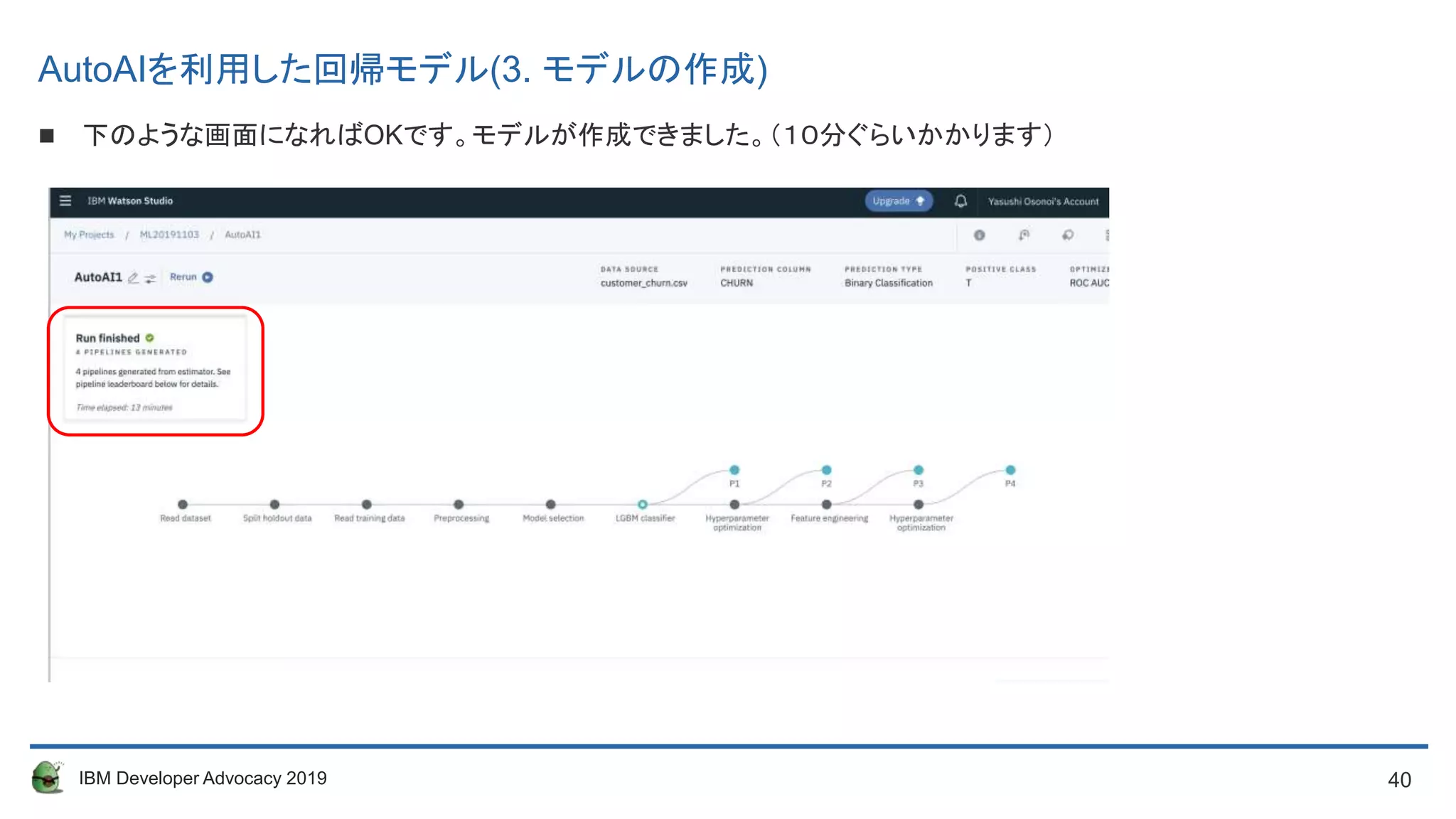
Run finishedになるまで待ちます。(10分ぐらいかかります)
以下のような画面になればOKです。モデルが作成できました。
AutoAIを利用した分類モデル(3. モデルの作成)
27. 27IBM Developer Advocacy 2019
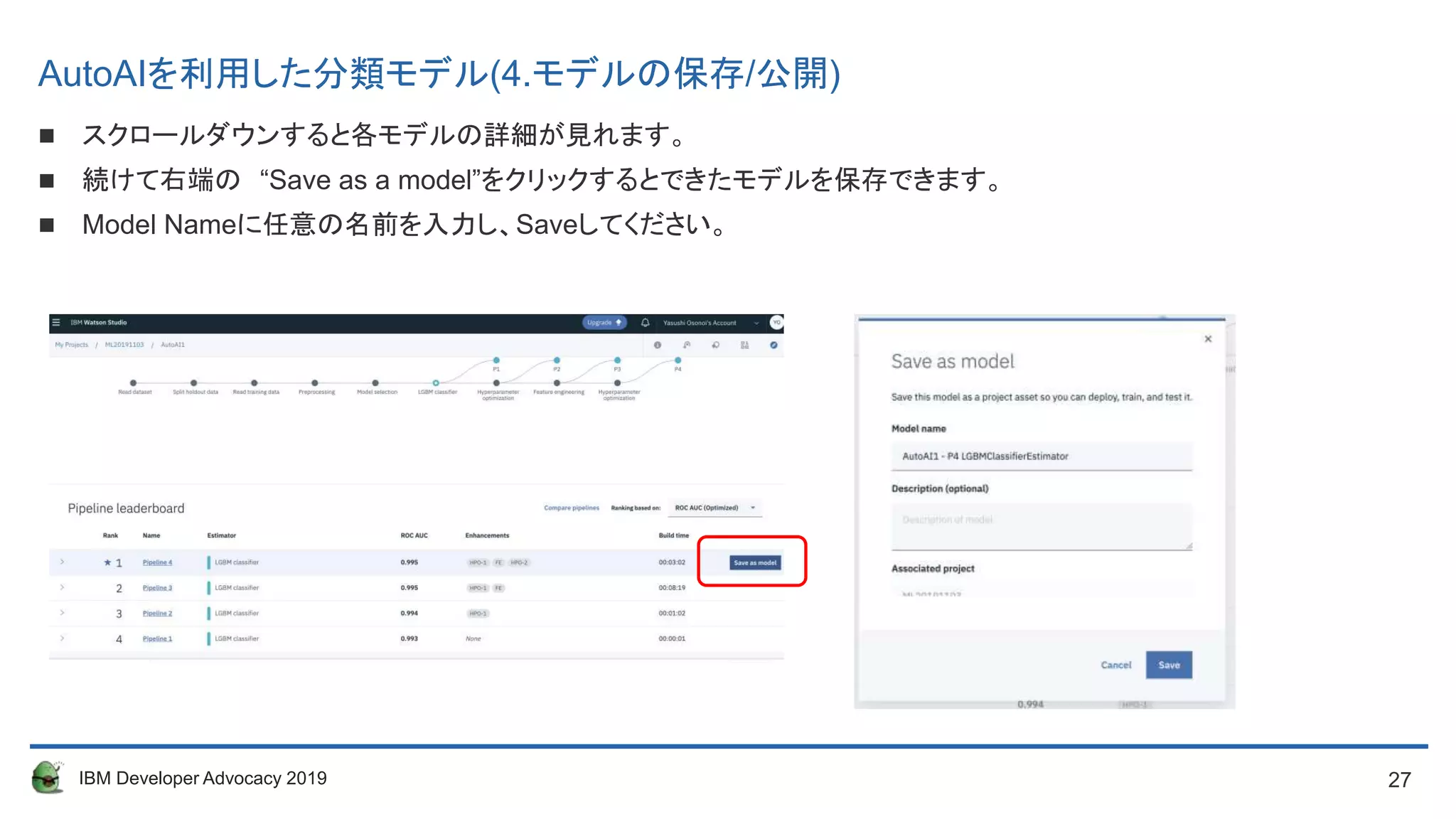
AutoAIを利用した分類モデル(4.モデルの保存/公開)
スクロールダウンすると各モデルの詳細が見れます。
続けて右端の “Save as a model”をクリックするとできたモデルを保存できます。
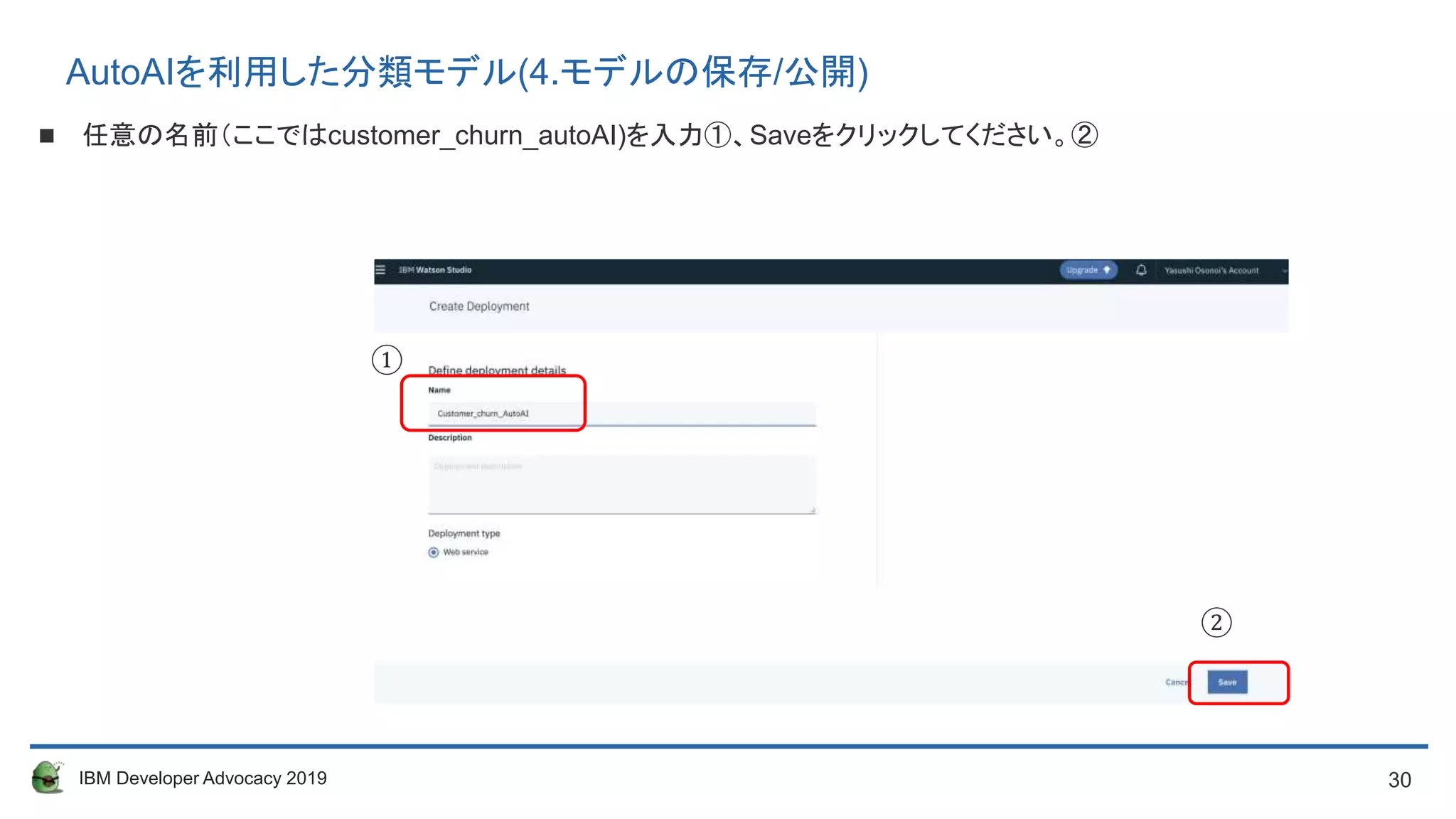
Model Nameに任意の名前を入力し、Saveしてください。
28. 28IBM Developer Advocacy 2019
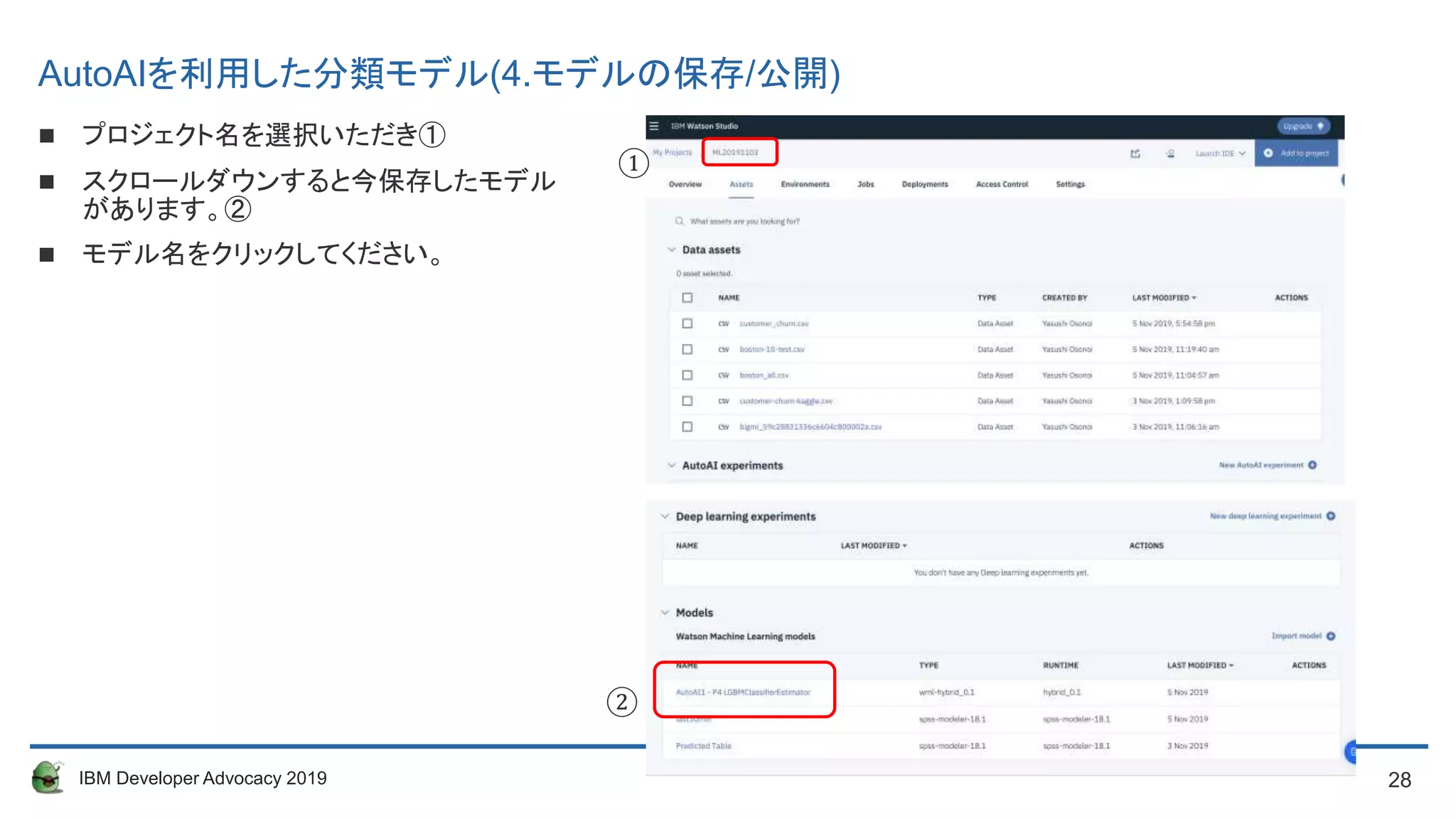
プロジェクト名を選択いただき①
スクロールダウンすると今保存したモデル
があります。②
モデル名をクリックしてください。
①
②
AutoAIを利用した分類モデル(4.モデルの保存/公開)
29. 29IBM Developer Advocacy 2019
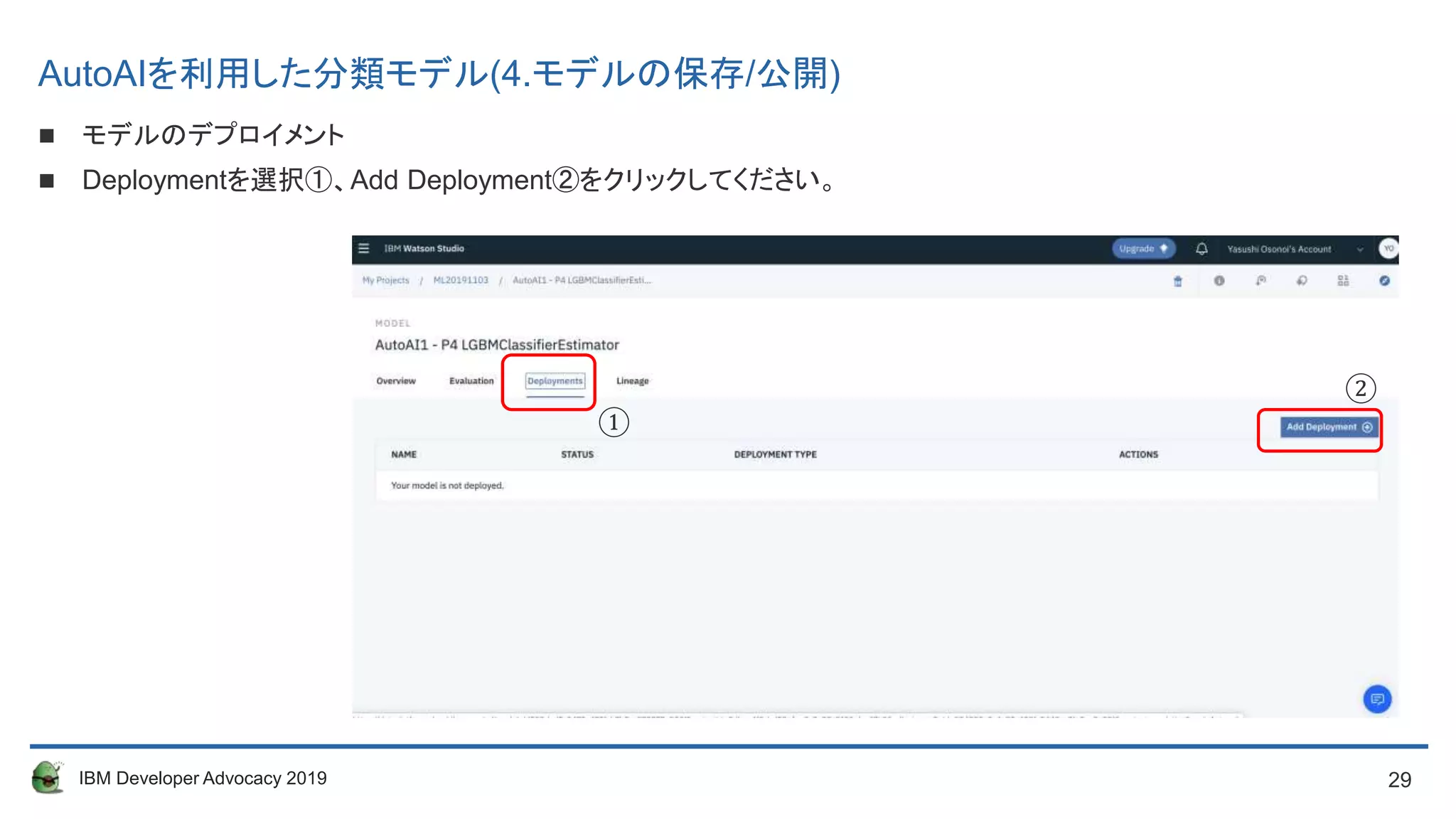
モデルのデプロイメント
Deploymentを選択①、Add Deployment②をクリックしてください。
①
②
AutoAIを利用した分類モデル(4.モデルの保存/公開)
30. 31. 32. 32IBM Developer Advocacy 2019
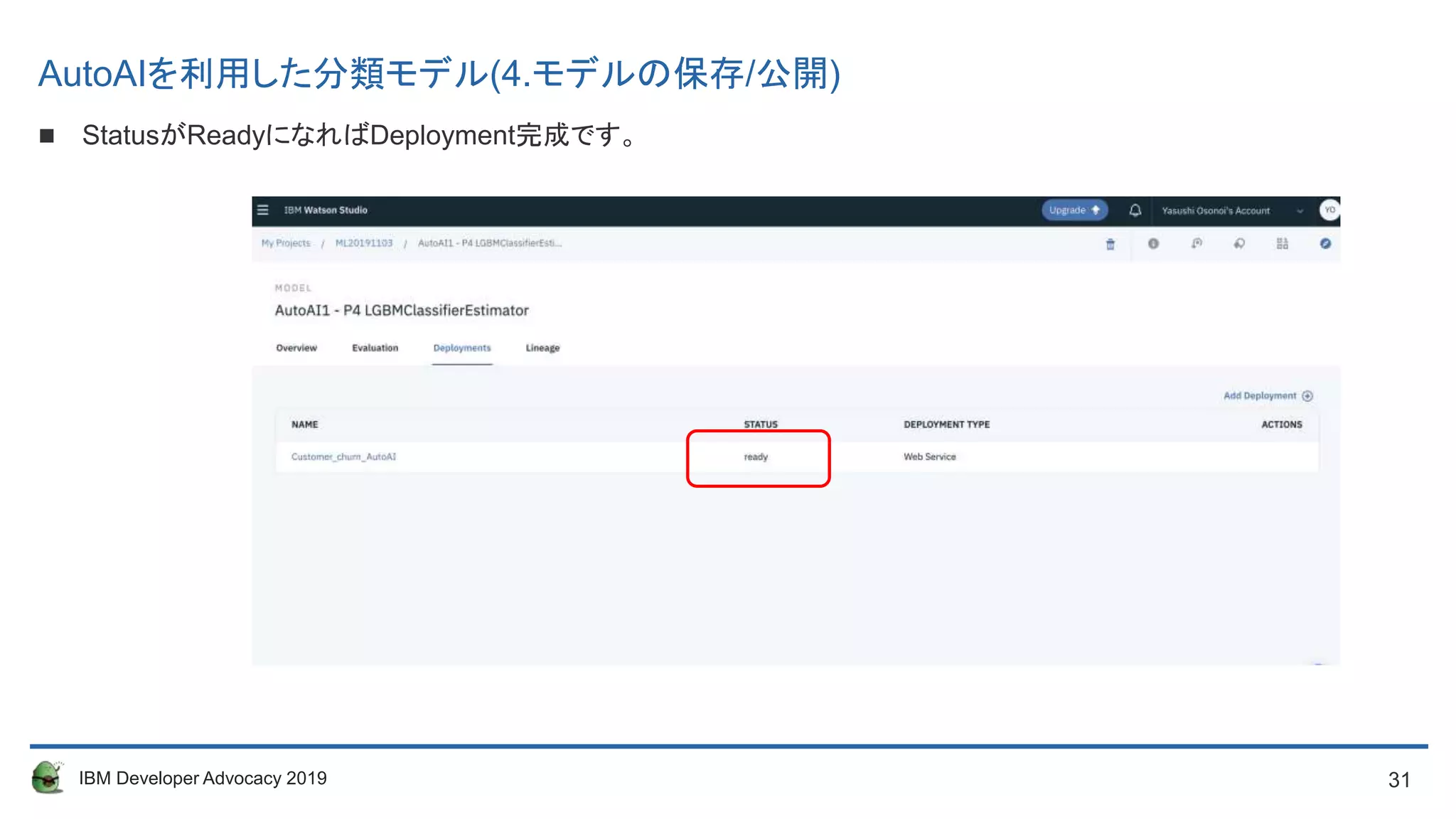
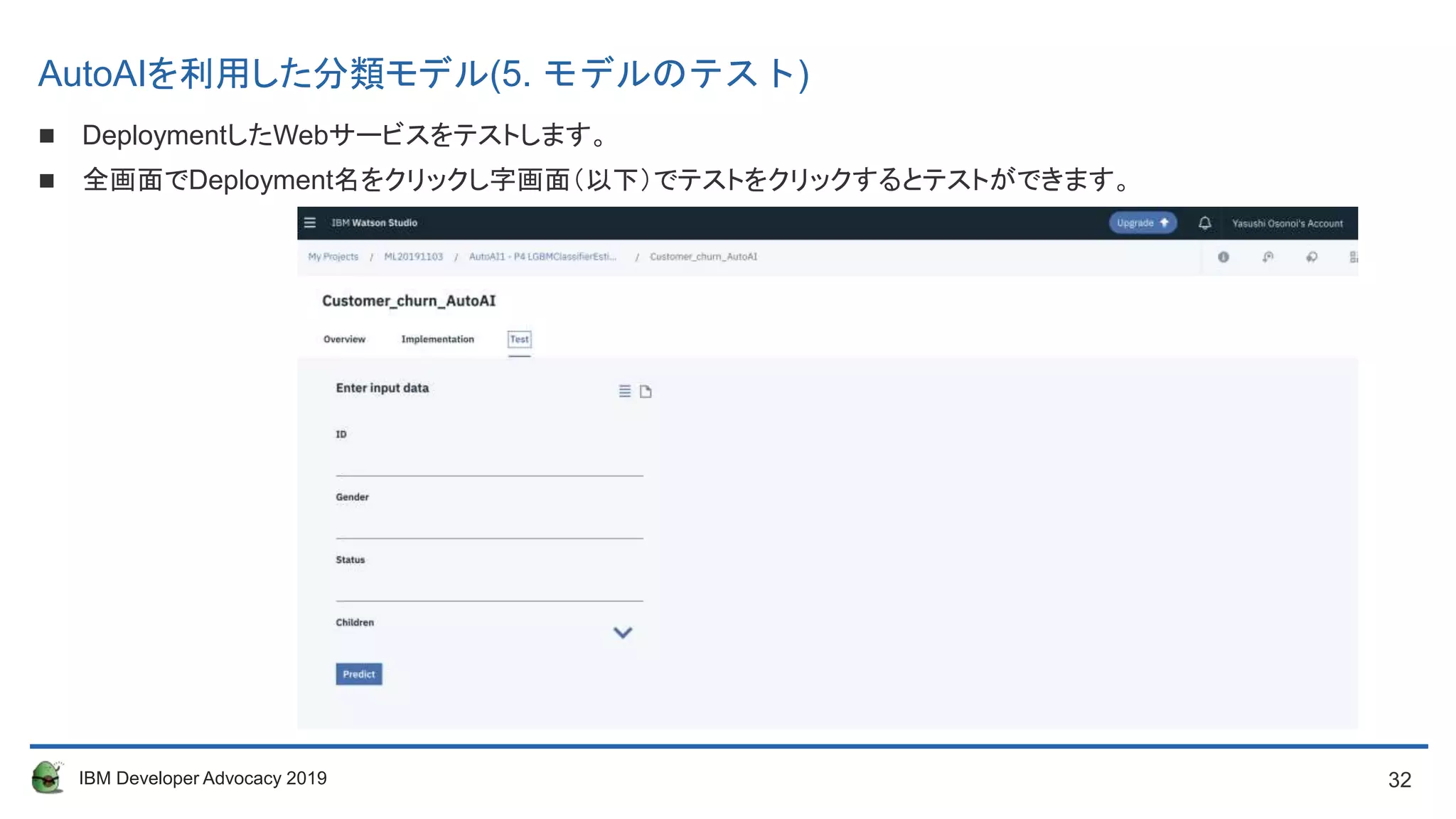
AutoAIを利用した分類モデル(5. モデルのテスト)
DeploymentしたWebサービスをテストします。
全画面でDeployment名をクリックし字画面(以下)でテストをクリックするとテストができます。
33. 33IBM Developer Advocacy 2019
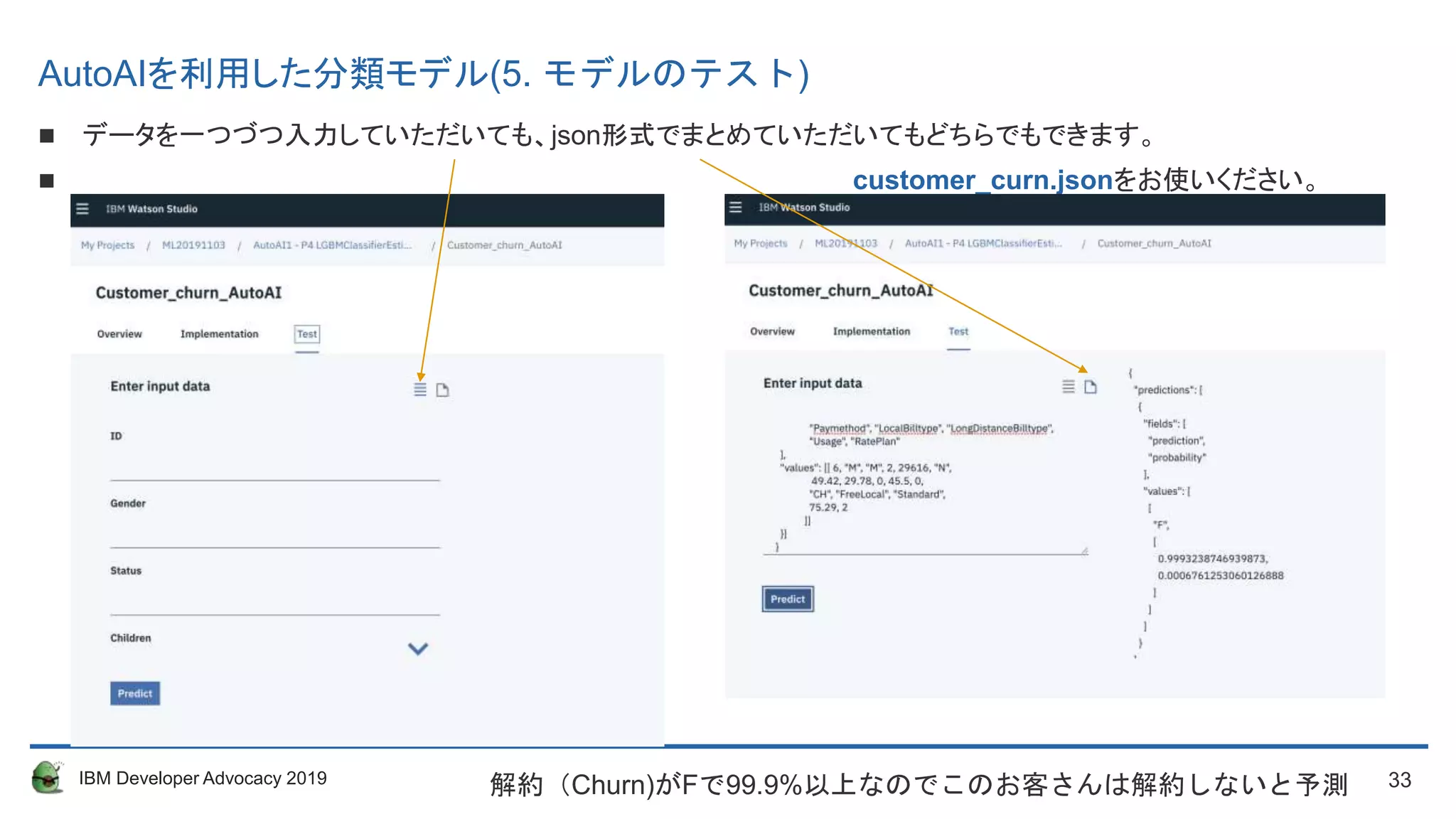
データを一つづつ入力していただいても、json形式でまとめていただいてもどちらでもできます。
customer_curn.jsonをお使いください。
解約(Churn)がFで99.9%以上なのでこのお客さんは解約しないと予測
AutoAIを利用した分類モデル(5. モデルのテスト)
34. 34IBM Developer Advocacy 2019
AutoAIを使用して回帰モデルを作成する
住所、その地区の環境などから住宅価格を予測するモデルを作成します。
使用するデータは boston_house_price.csv です。
前回作成したモデルを、AutoAIを使用して作成します。
35. 35IBM Developer Advocacy 2019
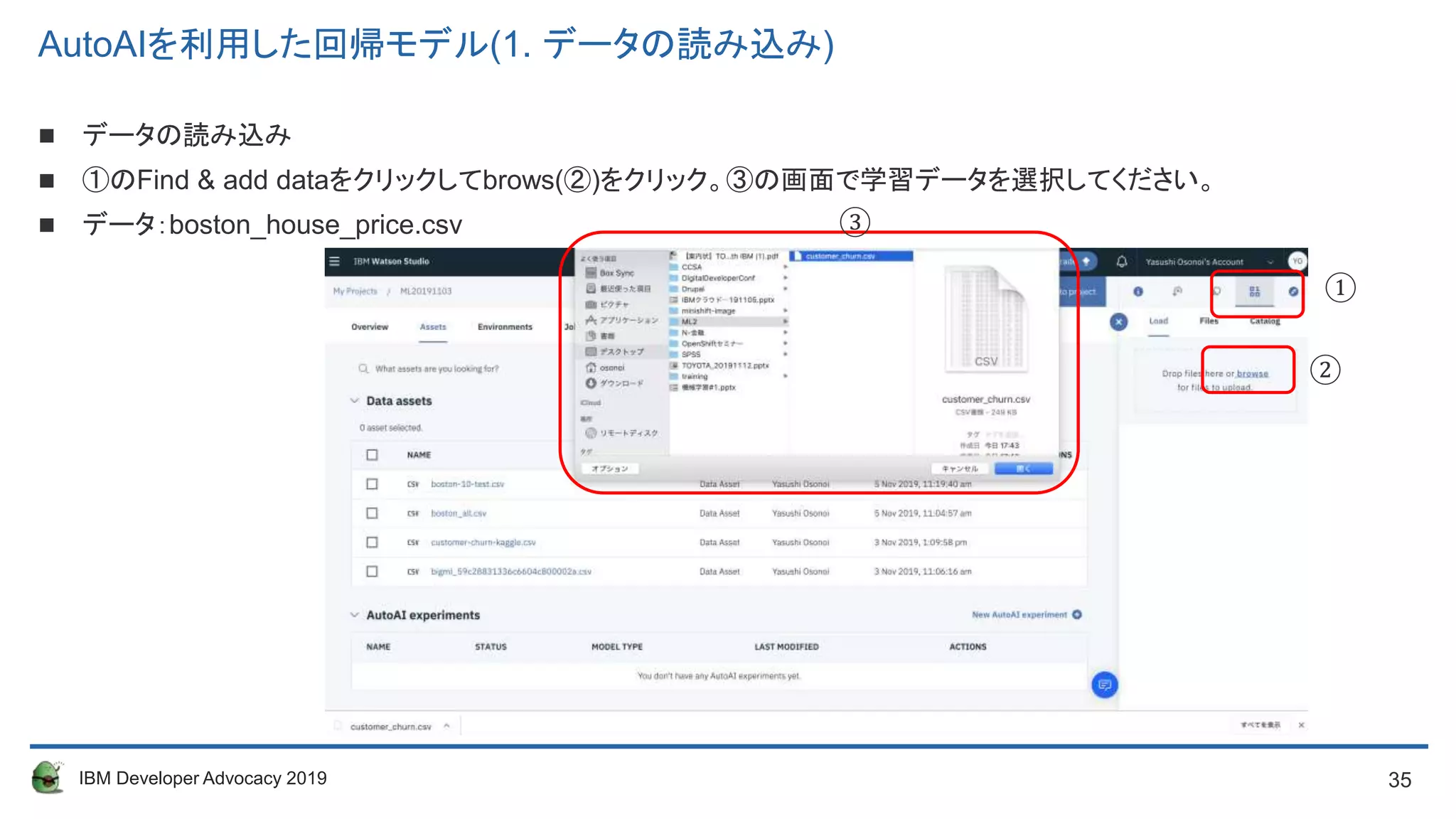
AutoAIを利用した回帰モデル(1. データの読み込み)
データの読み込み
①のFind & add dataをクリックしてbrows(②)をクリック。③の画面で学習データを選択してください。
データ:boston_house_price.csv
①
②
③
36. 36IBM Developer Advocacy 2019
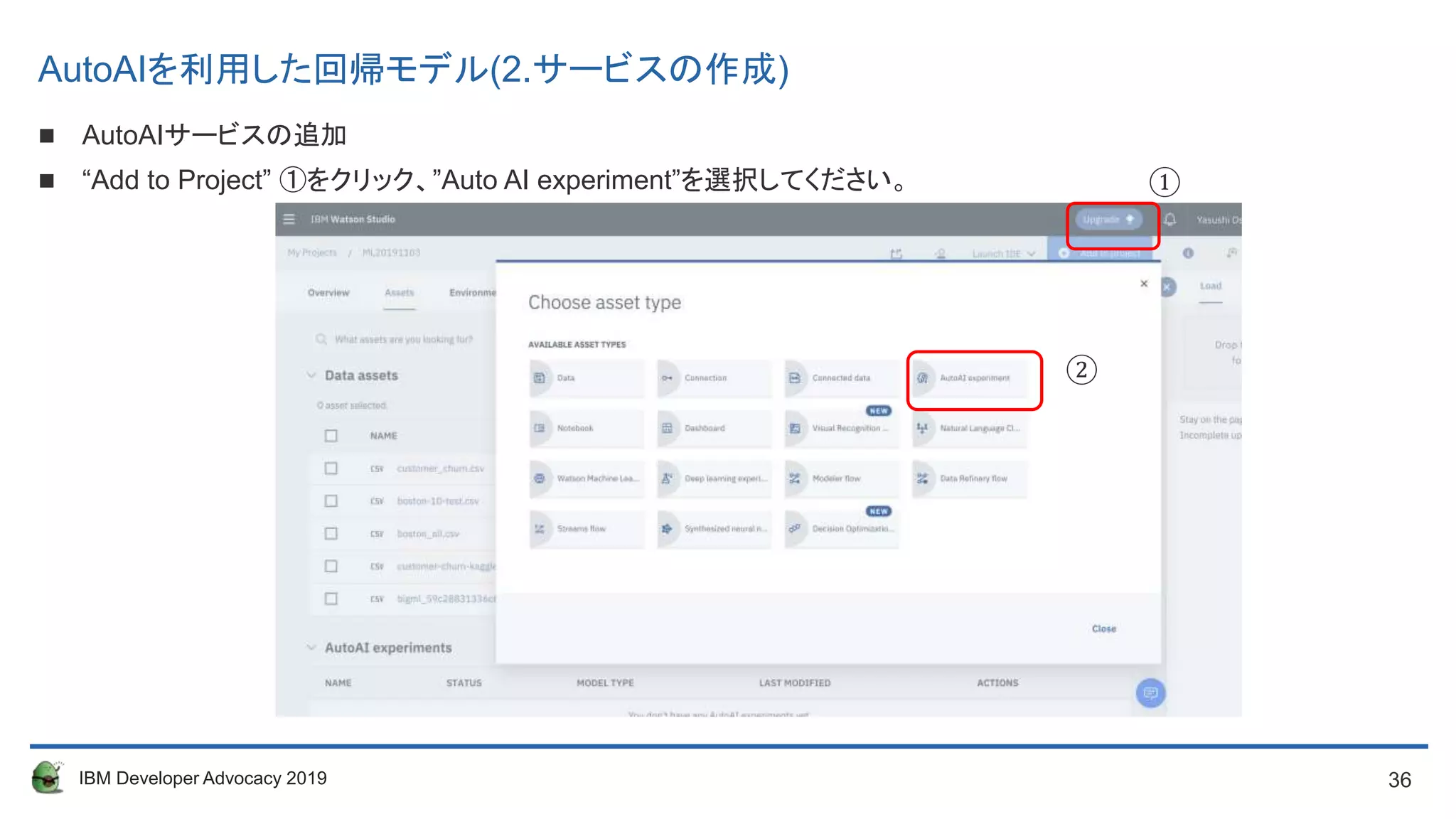
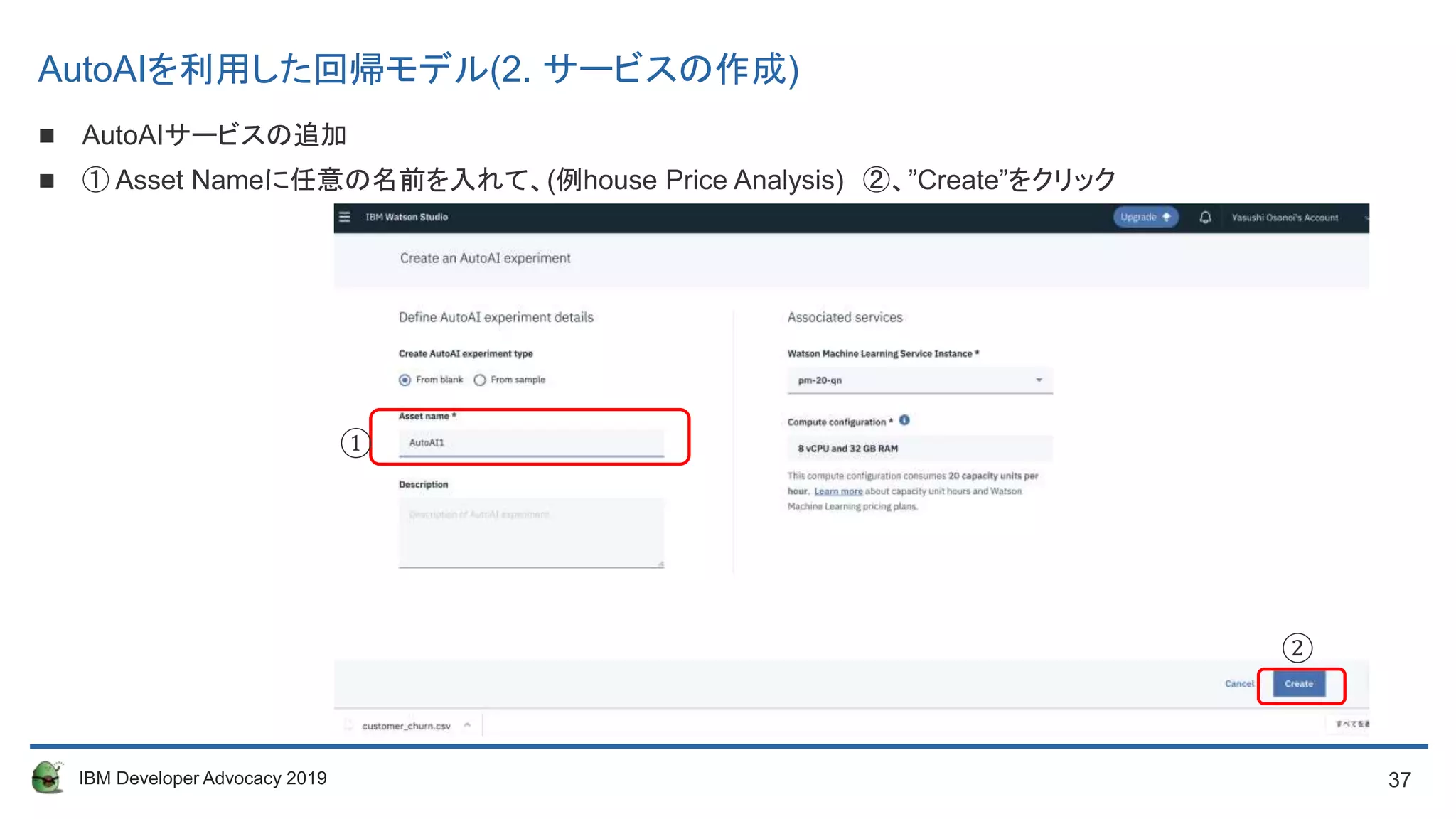
AutoAIサービスの追加
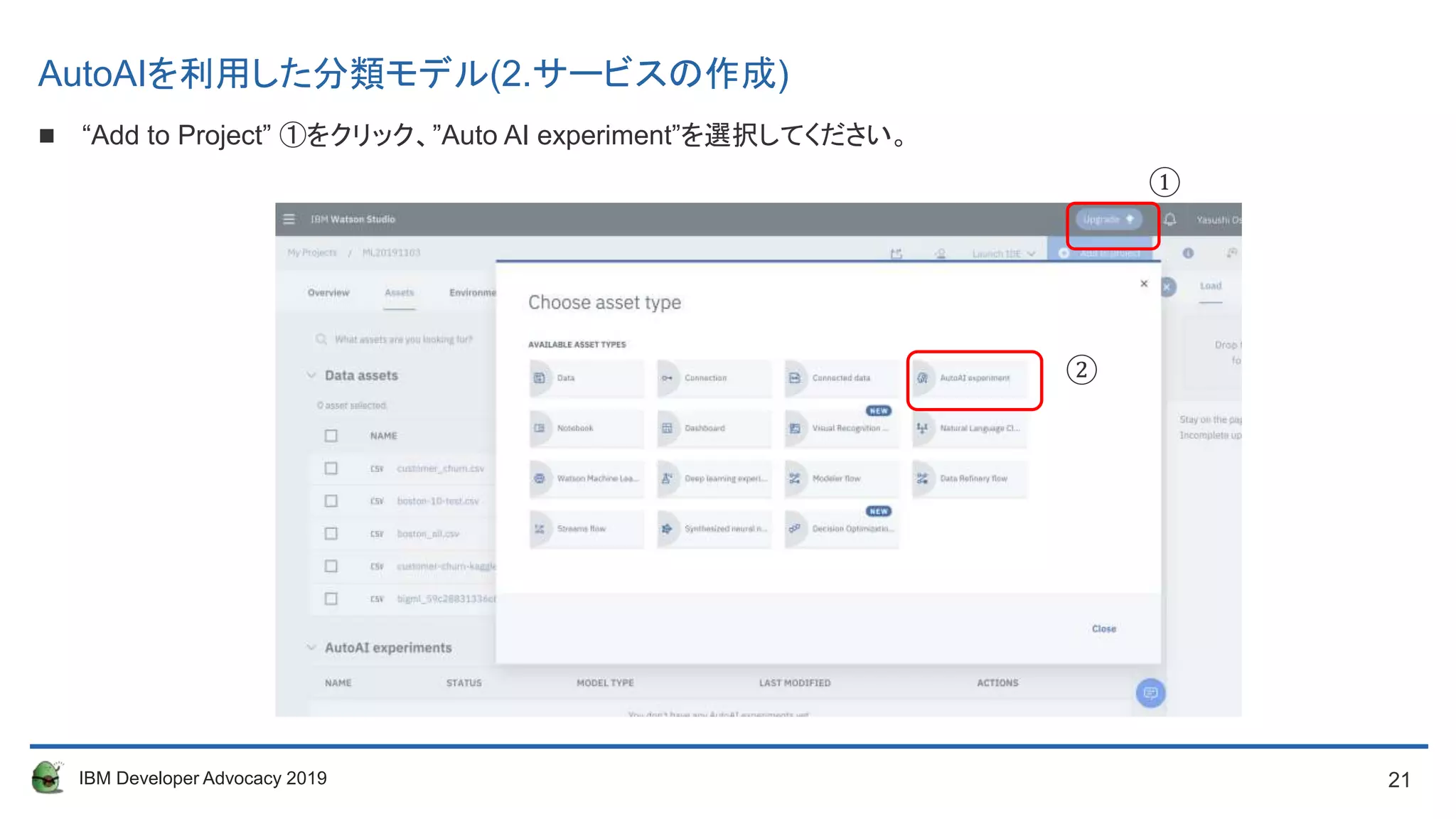
“Add to Project” ①をクリック、”Auto AI experiment”を選択してください。 ①
②
AutoAIを利用した回帰モデル(2.サービスの作成)
37. 37IBM Developer Advocacy 2019
AutoAIサービスの追加
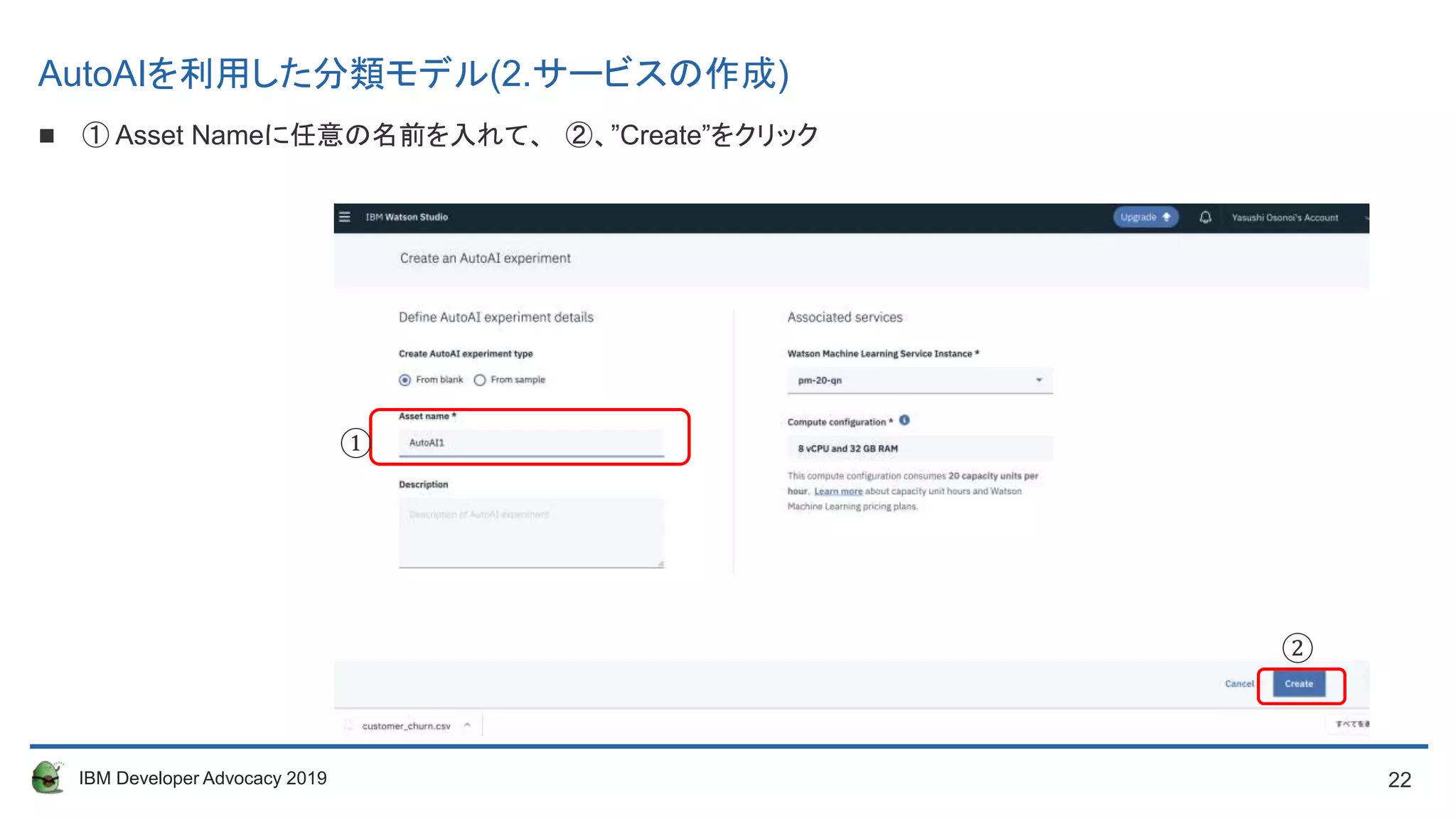
① Asset Nameに任意の名前を入れて、(例house Price Analysis) ②、”Create”をクリック
①
②
AutoAIを利用した回帰モデル(2. サービスの作成)
38. 38IBM Developer Advocacy 2019
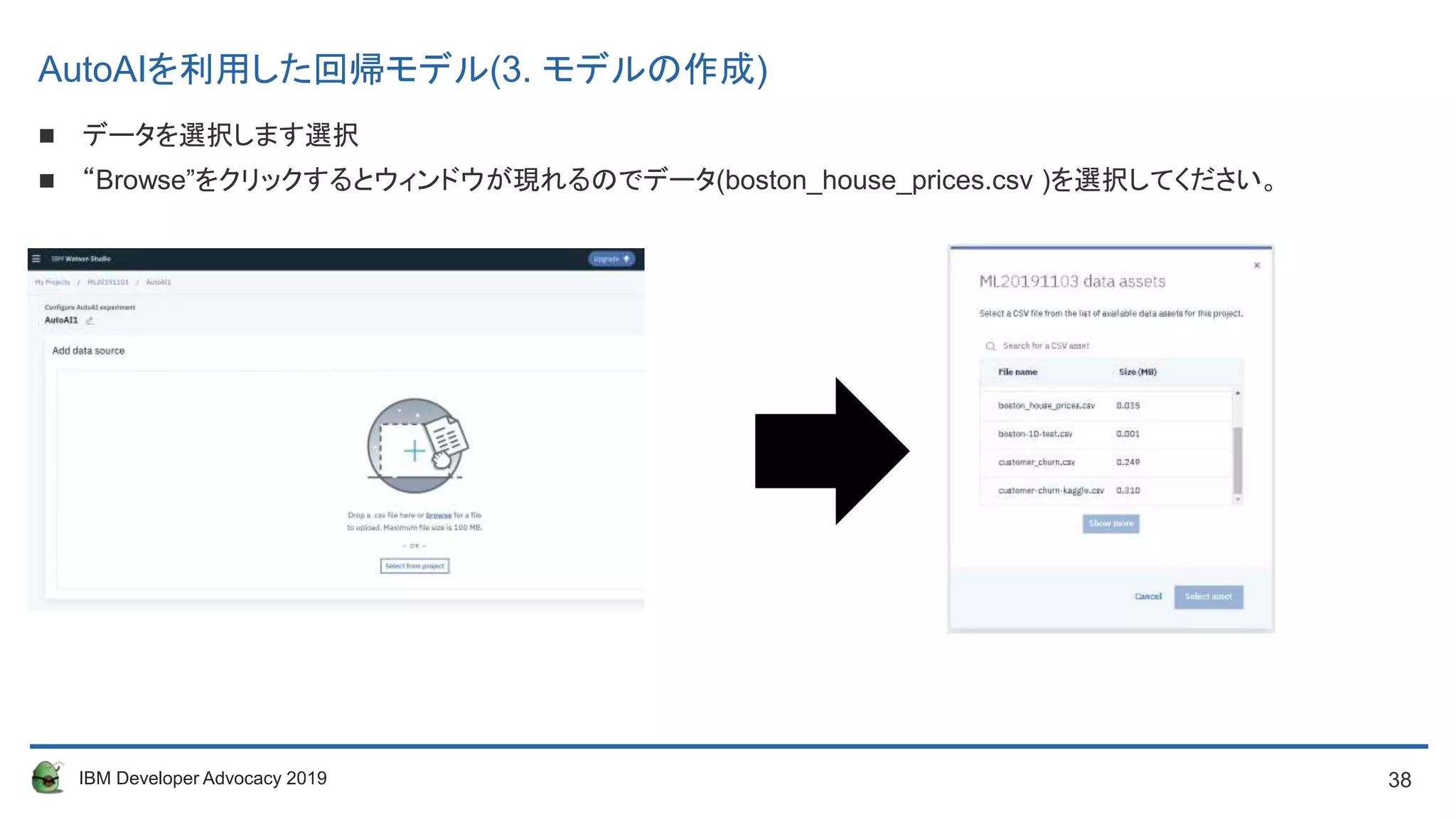
データを選択します選択
“Browse”をクリックするとウィンドウが現れるのでデータ(boston_house_prices.csv )を選択してください。
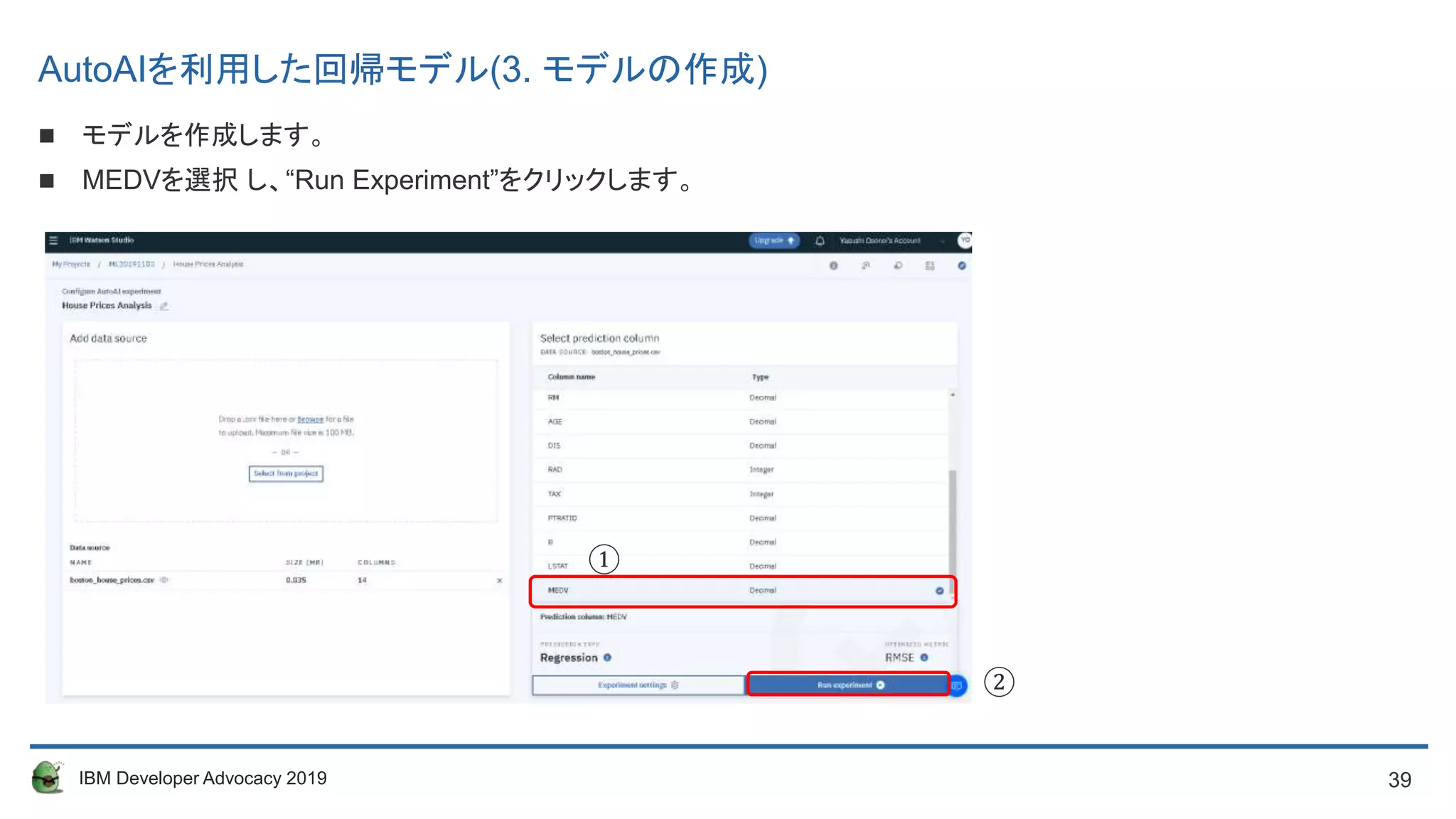
AutoAIを利用した回帰モデル(3. モデルの作成)
39. 40. 41. 41IBM Developer Advocacy 2019
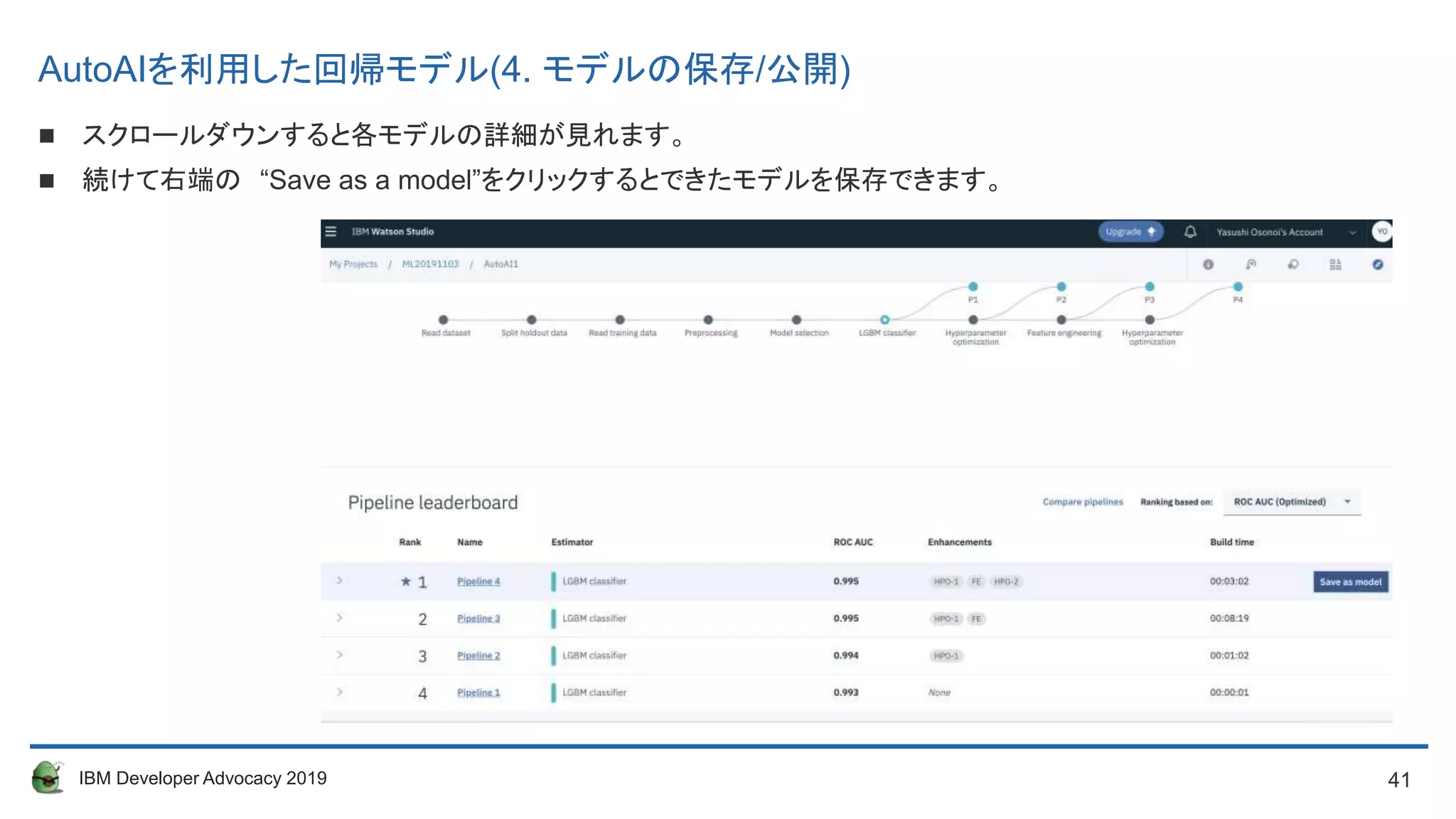
スクロールダウンすると各モデルの詳細が見れます。
続けて右端の “Save as a model”をクリックするとできたモデルを保存できます。
AutoAIを利用した回帰モデル(4. モデルの保存/公開)
42. 42IBM Developer Advocacy 2019
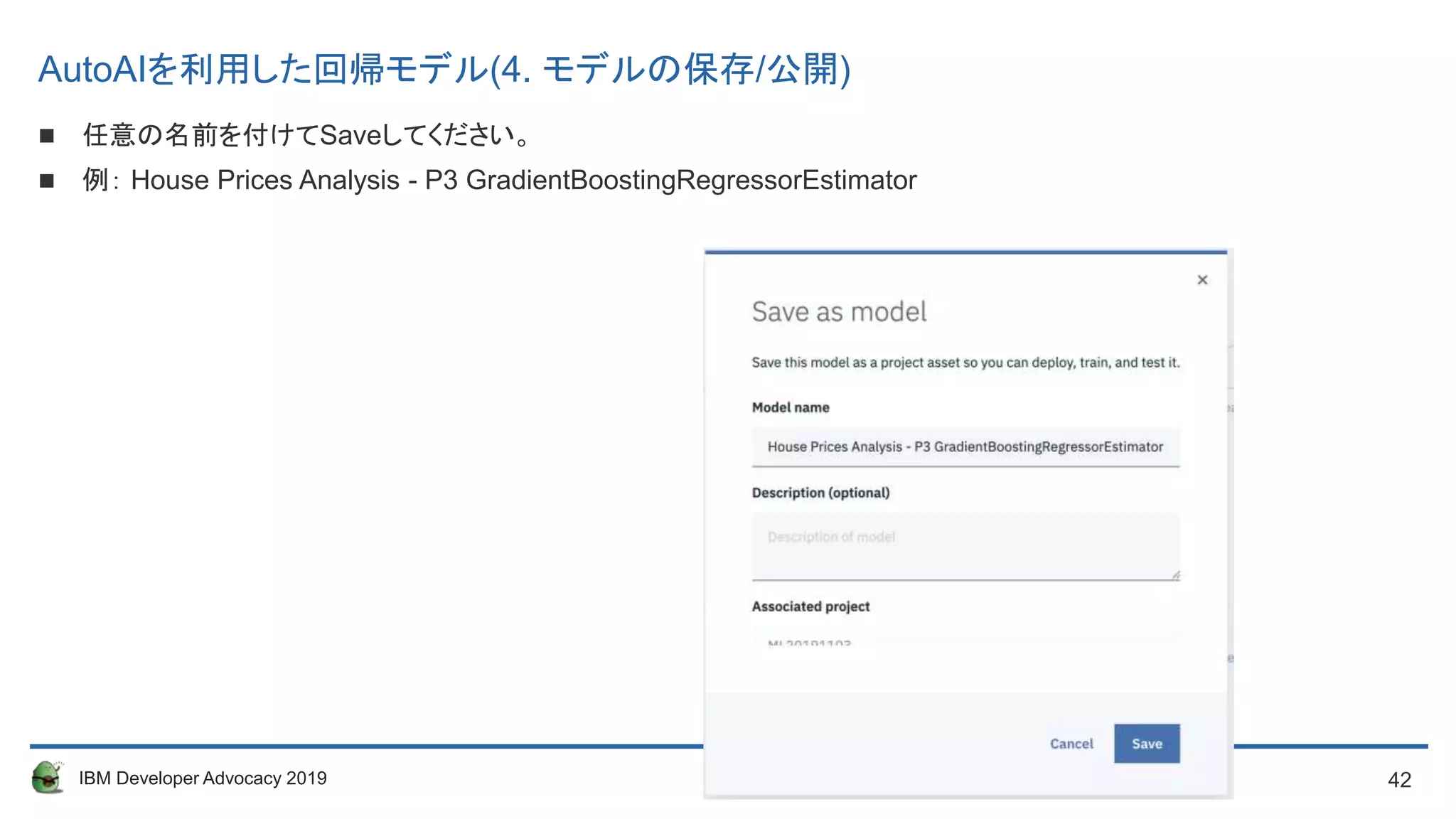
任意の名前を付けてSaveしてください。
例: House Prices Analysis - P3 GradientBoostingRegressorEstimator
AutoAIを利用した回帰モデル(4. モデルの保存/公開)
43. 43IBM Developer Advocacy 2019
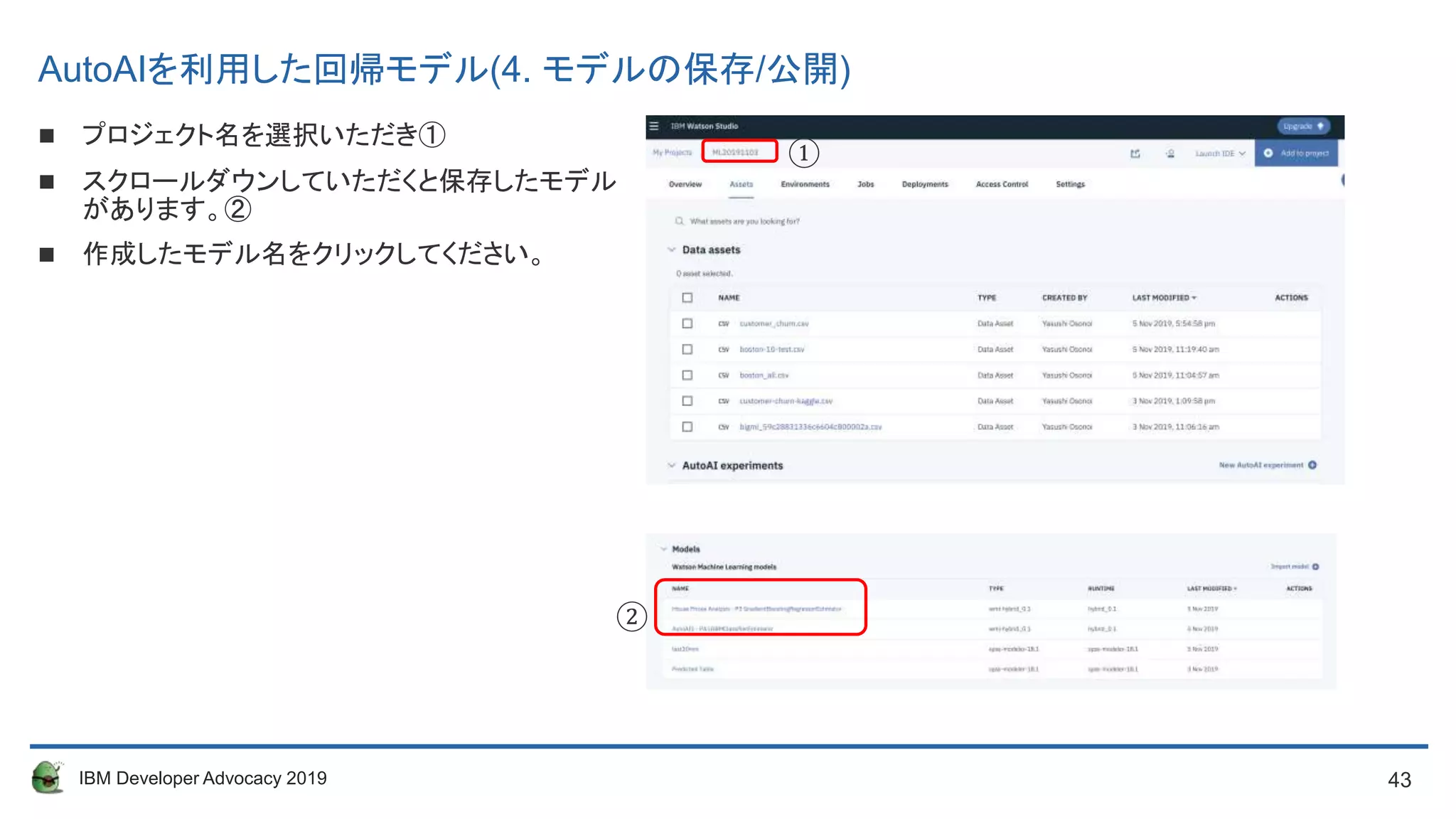
プロジェクト名を選択いただき①
スクロールダウンしていただくと保存したモデル
があります。②
作成したモデル名をクリックしてください。
①
②
AutoAIを利用した回帰モデル(4. モデルの保存/公開)
44. 44IBM Developer Advocacy 2019
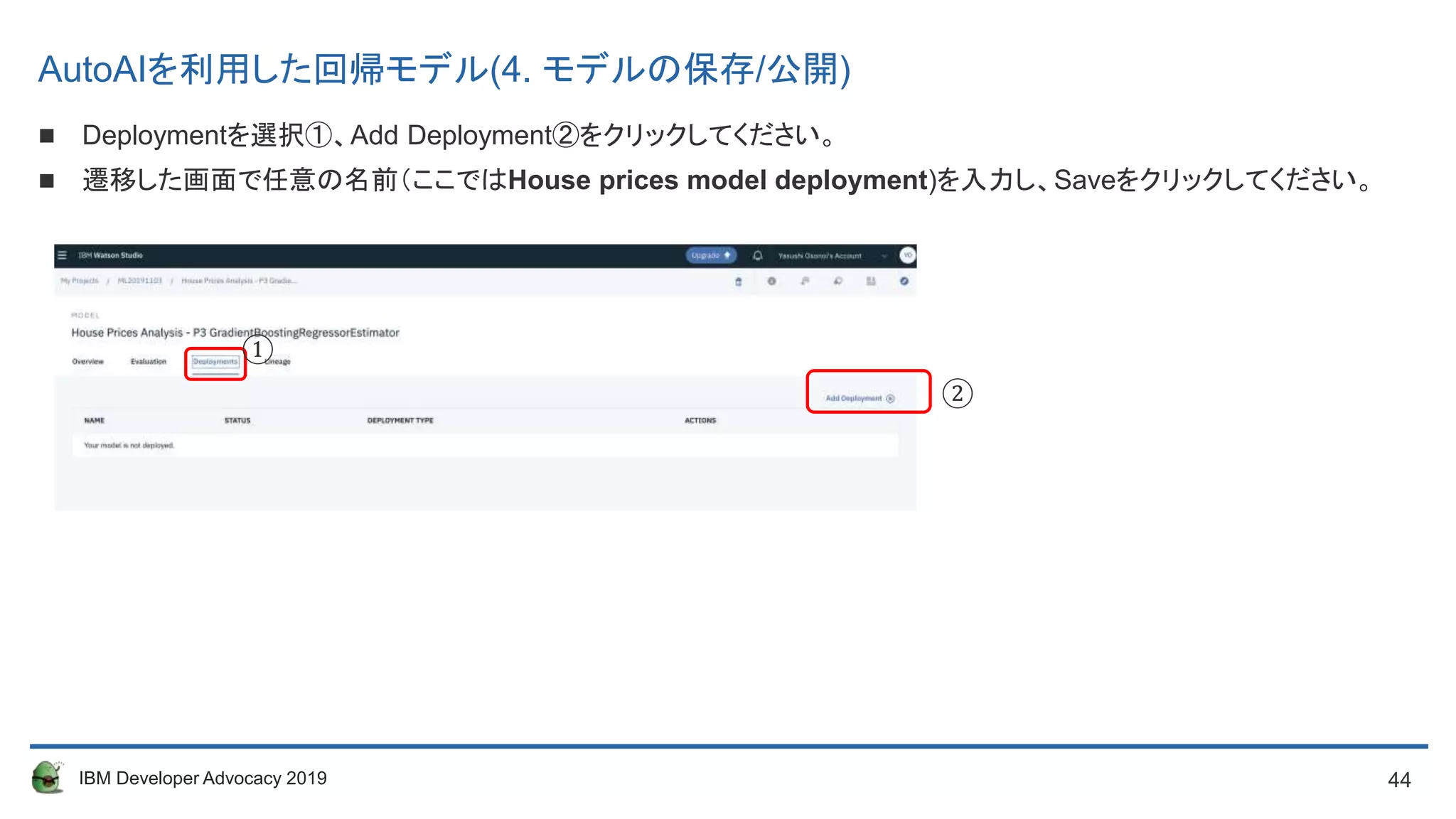
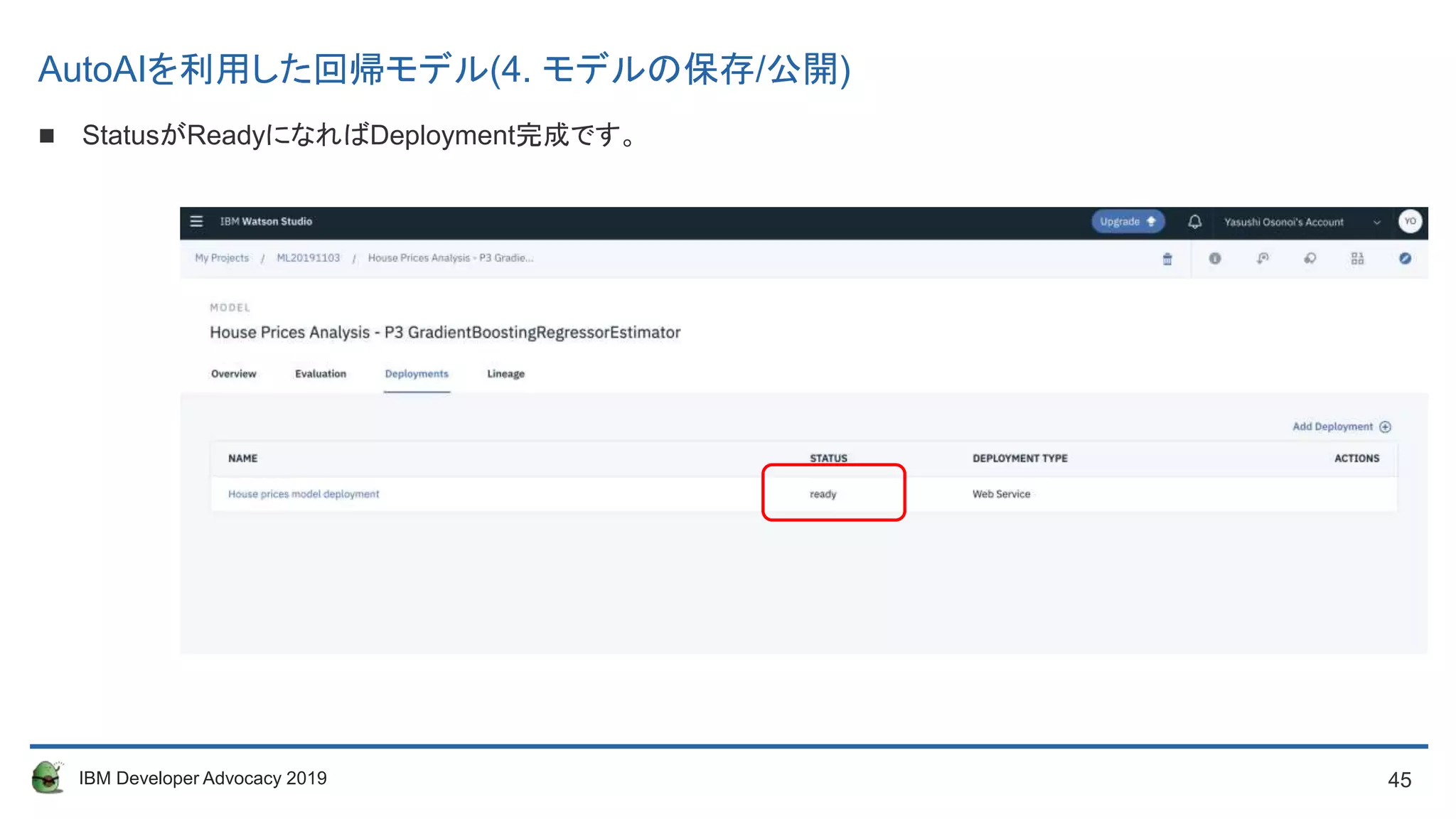
Deploymentを選択①、Add Deployment②をクリックしてください。
遷移した画面で任意の名前(ここではHouse prices model deployment)を入力し、Saveをクリックしてください。
①
②
AutoAIを利用した回帰モデル(4. モデルの保存/公開)
45. 46. 46IBM Developer Advocacy 2019
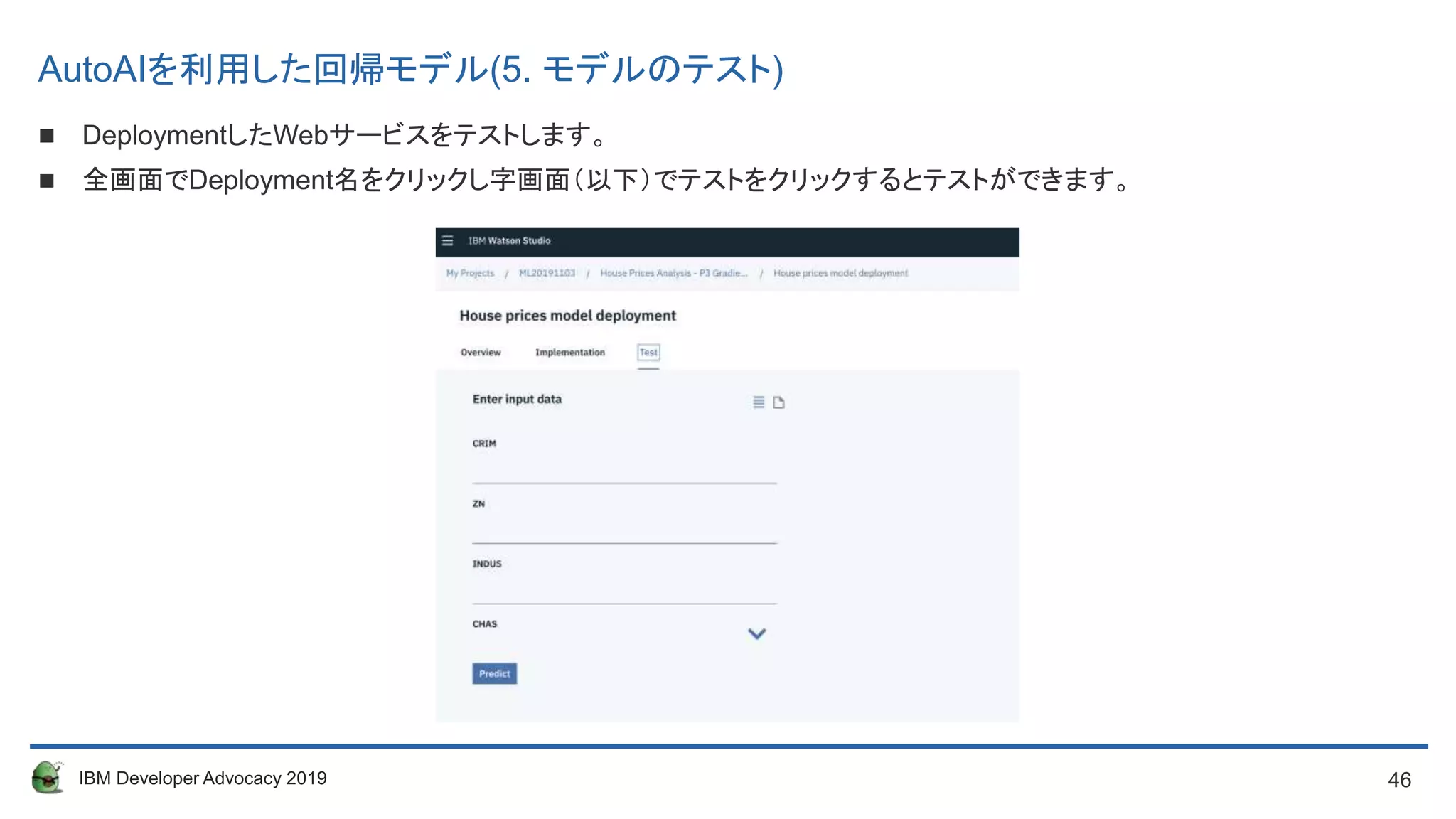
DeploymentしたWebサービスをテストします。
全画面でDeployment名をクリックし字画面(以下)でテストをクリックするとテストができます。
AutoAIを利用した回帰モデル(5. モデルのテスト)
47. 47IBM Developer Advocacy 2019
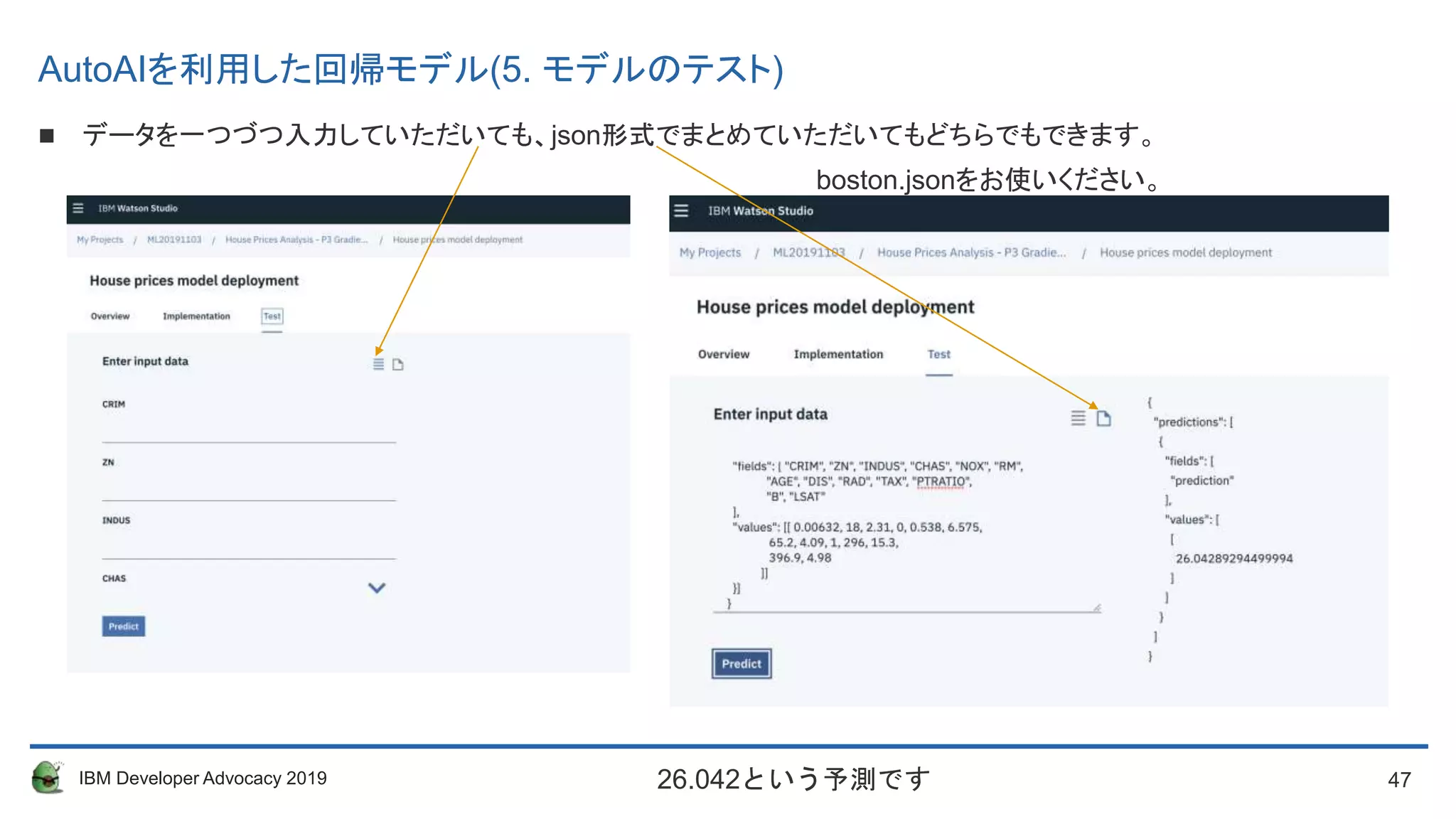
データを一つづつ入力していただいても、json形式でまとめていただいてもどちらでもできます。
boston.jsonをお使いください。
26.042という予測です
AutoAIを利用した回帰モデル(5. モデルのテスト)
Editor's Notes #9
Here is a quick look into the process that AutoAI executes behind the scenes. There is a combination of data prep, model selection, Hyper parameter optimization, feature engineering, and Ensembling of models
Here is a quick look into the process that AutoAI executes behind the scenes. There is a combination of data prep, model selection, Hyper parameter optimization, feature engineering, and Ensembling of models
prep Finds best preprocessing imputation / encoding and scaling strategies
Model selection Finds top-K estimators
Hyperparameter optimization (HPO) HPO on selected estimator
Feature engineering Finds best data transformation sequence
Hyperparameter optimization (HPO) HPO on estimator after Feature Engineering
Ensembling - Computes ensemble predictions based on pipeline predictions






![14IBM Developer Advocacy 2019
プロジェクトの作成
Liteが選択されていることを確認して[Create]をクリックします。
Confirm Creationのダイアログはそのまま[Confirm]をクリックします。](https://image.slidesharecdn.com/autoai-workshop-200216114842/75/Auto-ai-workshop-14-2048.jpg)
![15IBM Developer Advocacy 2019
プロジェクトの作成
New Projectの画面になるので、 Define Storage の②Refreshをクリックします 。
Storageが表示された後、[Create]をクリックします。](https://image.slidesharecdn.com/autoai-workshop-200216114842/75/Auto-ai-workshop-15-2048.jpg)
![16IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[Settings]をクリックします。
Associated servicesから[+Add services]をクリックして[Watson]を選択]を選択](https://image.slidesharecdn.com/autoai-workshop-200216114842/75/Auto-ai-workshop-16-2048.jpg)
![17IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[New]のタブが選択された画面が表示された場合
- 1. スクロールしてPLANでLiteが選択されていることを確認して一番下の[Create]をクリック 。
- 2. Confirmの画面でRegionがDallasになっていることを確認して[Confirm]をクリック](https://image.slidesharecdn.com/autoai-workshop-200216114842/75/Auto-ai-workshop-17-2048.jpg)
![18IBM Developer Advocacy 2019
Watson Machine Learning サービスの追加
[Settings] の画面に戻ります。
Associated servicesに追加したサービスのインスタンスが追加されていることを確認します。](https://image.slidesharecdn.com/autoai-workshop-200216114842/75/Auto-ai-workshop-18-2048.jpg)




![[Developers Summit 2017] MicrosoftのAI開発機能/サービス](https://cdn.slidesharecdn.com/ss_thumbnails/20170216devsumiai-170302021003-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Developers Festa Sapporo 2018] Azure AI ~Microsoft AzureでのAI開発のイマ~](https://cdn.slidesharecdn.com/ss_thumbnails/20181117devfestasapporoazureaipublic-181119035506-thumbnail.jpg?width=640&height=640&fit=bounds)














![[teratail Study ~機械学習編#2~] Microsoft AzureのAI関連サービス](https://cdn.slidesharecdn.com/ss_thumbnails/20161219teratail-161219114731-thumbnail.jpg?width=640&height=640&fit=bounds)




















