ALBERT: A LITEBERT FOR SELF-
SUPERVISED LEARNING OF
LANGUAGE REPRESENTATIONS
장영록
2.
Preview – 핵심내용
• [Challenge] Pre-trained language representation 모델의 크기
를 증가시켜 성능 개선 시 다음의 문제점 발생
• Memory Limitation
• Training Time
• Model Degradation
• [Contribution] BERT에서 다음의 사항을 개선하여 모델 크기를
줄이고 성능 또한 개선
• Factorized Embedding Parameterization
• Cross-layer parameter sharing
• Sentence-order prediction
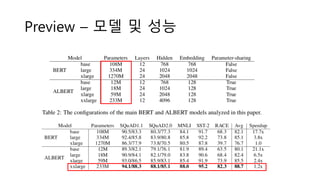
Challenge – ModelDegradation (1)
• 일반적으로 Language Representation, Machine Translation 등
의 Task에서는 모델이 클 수록 높은 성능을 보임
BERT Paper에서
의 실험 결과
7.
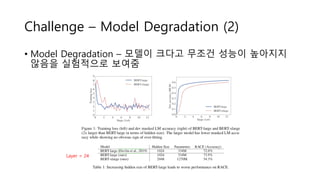
Challenge – ModelDegradation (2)
• Model Degradation – 모델이 크다고 무조건 성능이 높아지지
않음을 실험적으로 보여줌
Layer = 24
8.
Contribution – FactorizedEmbedding
Parameterization (1)
• Token Embedding Size(E)를 Hidden Layer Embedding Size(H)
보다 작게 설정하여 Parameter 수 줄임
• 기존 BERT, XLNet, RoBert 등 모두 E = H로 모델 구성
• [Intuition] H는 Contextualized Representation이지만 E는 Context
Independent Representation 이므로 E<H 이어도 모델의 성능이 떨어
지지 않을 것임
9.
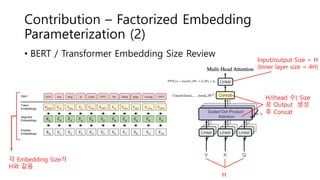
Contribution – FactorizedEmbedding
Parameterization (2)
• BERT / Transformer Embedding Size Review
H
H/(head 수) Size
로 Output 생성
후 Concat
Input/output Size = H
(Inner layer size = 4H)
각 Embedding Size가
H와 같음
10.
Contribution – FactorizedEmbedding
Parameterization (3)
• BERT에서는 Vocabulary Size(V) x H를 활용하여 Token
Embedding
• Factorized Embedding Parameterization – VxE Matrix로 Token
Embedding 후 ExH Matrix를 활용하여 최종 Input 생성
• O(VxH) -> O(VxE+ExH)
• 일반적으로 V(BERT에서 30,000)가 매우 크므로 Parameter Size를 줄일
수 있음
H = 768 / layer = 12
Cross layer parameter
sharing 여부 (뒤에서
설명)
11.
Contribution – Cross-layerParameter Sharing
(1)
• Layer 간 같은 Parameter를 사용 (Recursive Transformation)
• Attention, FFN 등의 모든 Parameter를 Layer 간 공유
• Layer 수가 늘어나더라도 Parameter 수가 늘어나지 않음
• 유사한 Idea
• Universal Transformer
• https://arxiv.org/abs/1807.03819
• Deep Equilibrium Models
• https://arxiv.org/abs/1909.01377
12.
Contribution – Cross-layerParameter Sharing
(2)
• Universal Transformer
• [Intuition] RNN이 Sequence Data를 활용하여 Hidden State를
Iterative Update 하는 것처럼 Recurrent Layer를 통해 Output을
Iterative Update(Recursive Transformation)
• RNNs’ inductive bias towards learning iterative
• Machine Translation , bAbI (NLU Task) 등에서 Transformer 보다 높은
성능
13.
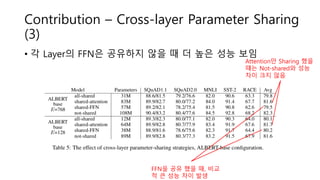
Contribution – Cross-layerParameter Sharing
(3)
Attention만 Sharing 했을
떄는 Not-shared와 성능
차이 크지 않음
FFN을 공유 했을 때, 비교
적 큰 성능 차이 발생
• 각 Layer의 FFN은 공유하지 않을 때 더 높은 성능 보임
14.
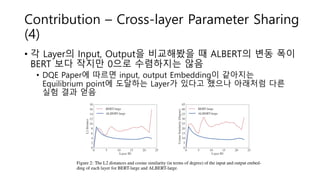
Contribution – Cross-layerParameter Sharing
(4)
• 각 Layer의 Input, Output을 비교해봤을 때 ALBERT의 변동 폭이
BERT 보다 작지만 0으로 수렴하지는 않음
• DQE Paper에 따르면 input, output Embedding이 같아지는
Equilibrium point에 도달하는 Layer가 있다고 했으나 아래처럼 다른
실험 결과 얻음
15.
Contribution – Inter-sentencecoherence loss
(1)
• Next Sentence Prediction(NSP) 대신 2개의 Sentence의 order
가 맞는지 여부를 예측하는 방식으로 학습
• Negative Example – 앞,뒤 문장의 순서를 바꾸어서 구성
• [Intuition] Sentence Order를 예측하는 것이 Inter-sentence
coherence를 학습하는데 더 적합
• NSP는 문장의 순서와 상관 없이 유사한 주제를 다루기만 한다면 Next
Sentence로 예측할 수 있음 -> Topic Prediction으로 볼 수 있음
• Sentence Order를 예측하는 경우 같은 Topic이라도 문장 간 순서를 고
려하므로 discourse level coherence를 반영한다고 볼 수 있음!
16.
Contribution – Inter-sentencecoherence loss
(2)
• ALBERT base에 Next Sentence Prediction(NSP), Sentence
Order Prediction(SOP) 각각 적용하여 실험
SOP로 학습해도 NSP 어
느 정도 가능
NSP로 학습시 SOP를 거
의 하지 못함
영화 Review -> Postive/negative
classification Task
17.
Experiment
• Book Corpus,Wikipedia – 16GB 사용 (BERT와 같음)
• Batch Size = 4096
• 125,000 Steps 학습
• TPU v3 사용
• Model의 크기에 따라 64 ~ 1024 chips 활용
• Dataset
• GLUE 9 tasks
• SQUAD 1.1, 2.0
• RACE
• 중국 영어 시험 – 100,000개의 Questions
• Candidate Answer 4개 -> Multiple Choice
• 중, 고등학교
18.
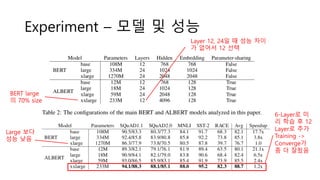
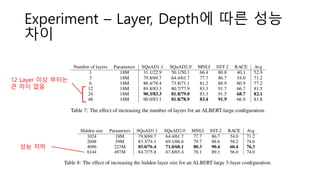
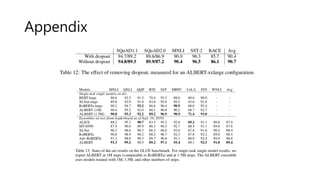
Experiment – 모델및 성능
BERT large
의 70% size
Layer 12, 24일 때 성능 차이
가 없어서 12 선택
Large 보다
성능 낮음
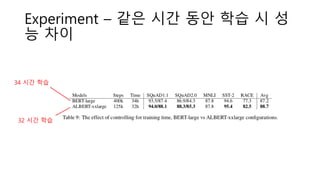
6-Layer로 미
리 학습 후 12
Layer로 추가
Training ->
Converge가
좀 더 잘됬음


![Preview – 핵심 내용
• [Challenge] Pre-trained language representation 모델의 크기
를 증가시켜 성능 개선 시 다음의 문제점 발생
• Memory Limitation
• Training Time
• Model Degradation
• [Contribution] BERT에서 다음의 사항을 개선하여 모델 크기를
줄이고 성능 또한 개선
• Factorized Embedding Parameterization
• Cross-layer parameter sharing
• Sentence-order prediction](https://image.slidesharecdn.com/albert-191027031239/85/Albert-2-320.jpg)



![Contribution – Factorized Embedding
Parameterization (1)
• Token Embedding Size(E)를 Hidden Layer Embedding Size(H)
보다 작게 설정하여 Parameter 수 줄임
• 기존 BERT, XLNet, RoBert 등 모두 E = H로 모델 구성
• [Intuition] H는 Contextualized Representation이지만 E는 Context
Independent Representation 이므로 E<H 이어도 모델의 성능이 떨어
지지 않을 것임](https://image.slidesharecdn.com/albert-191027031239/85/Albert-8-320.jpg)


![Contribution – Cross-layer Parameter Sharing
(2)
• Universal Transformer
• [Intuition] RNN이 Sequence Data를 활용하여 Hidden State를
Iterative Update 하는 것처럼 Recurrent Layer를 통해 Output을
Iterative Update(Recursive Transformation)
• RNNs’ inductive bias towards learning iterative
• Machine Translation , bAbI (NLU Task) 등에서 Transformer 보다 높은
성능](https://image.slidesharecdn.com/albert-191027031239/85/Albert-12-320.jpg)
![Contribution – Inter-sentence coherence loss
(1)
• Next Sentence Prediction(NSP) 대신 2개의 Sentence의 order
가 맞는지 여부를 예측하는 방식으로 학습
• Negative Example – 앞,뒤 문장의 순서를 바꾸어서 구성
• [Intuition] Sentence Order를 예측하는 것이 Inter-sentence
coherence를 학습하는데 더 적합
• NSP는 문장의 순서와 상관 없이 유사한 주제를 다루기만 한다면 Next
Sentence로 예측할 수 있음 -> Topic Prediction으로 볼 수 있음
• Sentence Order를 예측하는 경우 같은 Topic이라도 문장 간 순서를 고
려하므로 discourse level coherence를 반영한다고 볼 수 있음!](https://image.slidesharecdn.com/albert-191027031239/85/Albert-15-320.jpg)







![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Wavenet a generative model for raw audio](https://cdn.slidesharecdn.com/ss_thumbnails/wavenetagenerativemodelforrawaudio-160920054055-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)














