Download as PDF, PPTX








![OK HOW ABOUT NOW?
(LAST TIME I PROMISE)
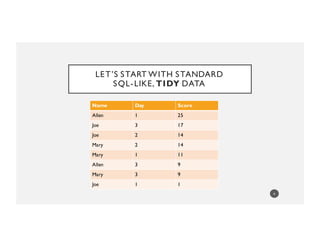
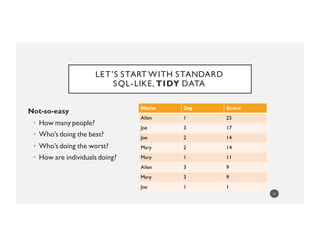
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
13](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-13-320.jpg)
![OK HOW ABOUT NOW?
(LAST TIME I PROMISE)
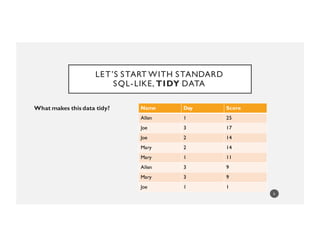
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
This data’s NOTTIDY but...
14](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-14-320.jpg)
![OK HOW ABOUT NOW?
(LAST TIME I PROMISE)
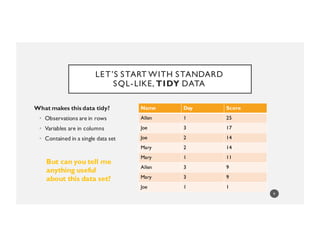
This data’s NOTTIDY but...
I can eyeball it easily
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
15](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-15-320.jpg)
![OK HOW ABOUT NOW?
(LAST TIME I PROMISE)
This data’s NOTTIDY but...
I can eyeball it easily
And new questions become
interesting and easier to
answer
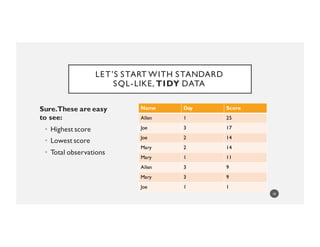
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
16](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-16-320.jpg)
![OK HOW ABOUT NOW?
(LAST TIME I PROMISE)
• How many students are there?
• Who improved?
• Who missed a test?
• Who was kind of meh?
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
17](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-17-320.jpg)
![DON’T GET MAD
I’m not saying to kill tidy Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
18](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-18-320.jpg)
![DON’T GET MAD
I’m not saying to kill tidy
But I worry we don’t use certain methods
more often because it’s not as easy as it
could be.
Name Ordered Scores
Joe [1, 14, 17]
Mary [11, 14, 9]
Allen [25, NA, 9]
19](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-19-320.jpg)






![Option 1:
>>> no_sql_df = df.groupby('Name').apply(lambda df: list(df.sort_values(by='Day')['Score']))
>>> no_sql_df
Name
Allen [25, 9]
Joe [1, 14, 17]
Mary [11, 14, 9]
26
IT’S TRUE.YOU CAN ANSWER THESE
QUESTIONS WITH THE TIDY DATA FRAMES I
JUST SHOWED YOU.
You can always ’reconstruct’ these trajectories of
what happened by making a data frame per user
>>> df
Name Day Score
0 Allen 1 25
1 Joe 3 17
2 Joe 2 14
3 Mary 2 14
4 Mary 1 11
5 Allen 3 9
6 Mary 3 9
7 Joe 1 1](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-26-320.jpg)
![IT’S TRUE.YOU CAN ANSWER THESE
QUESTIONS WITH THE TIDY DATA FRAMES I
JUST SHOWED YOU.
Option 2:
>>> new_list = []
>>> for tuple in df.groupby(['Name']):
... new_list.append({tuple[0]: zip(tuple[1]['Day'], tuple[1]['Score'])})
...
>>> new_list
[{'Allen': [(1, 25), (3, 9)]}, {'Joe': [(3, 17), (2, 14), (1, 1)]}, {'Mary': [(2, 14), (1,
11), (3, 9)]}]
You can always ’reconstruct’ these trajectories of
what happened by making a data frame per user
27
>>> df
Name Day Score
0 Allen 1 25
1 Joe 3 17
2 Joe 2 14
3 Mary 2 14
4 Mary 1 11
5 Allen 3 9
6 Mary 3 9
7 Joe 1 1](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-27-320.jpg)
![IT’S TRUE.YOU CAN ANSWER THESE
QUESTIONS WITH THE TIDY DATA FRAMES I
JUST SHOWED YOU.
Option 3:
>>> def process(new_df):
... return [new_df[new_df['Day']==i]['Score'].values[0] if i in list(new_df['Day'])
else None for i in range(1,4)]
...
>>> df.groupby(['Name']).apply(process)
Name
Allen [25, None, 9]
Joe [1, 14, 17]
Mary [11, 14, 9]
You can always ’reconstruct’ these trajectories of
what happened by making a data frame per user
28
>>> df
Name Day Score
0 Allen 1 25
1 Joe 3 17
2 Joe 2 14
3 Mary 2 14
4 Mary 1 11
5 Allen 3 9
6 Mary 3 9
7 Joe 1 1](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-28-320.jpg)









![NORMALIZE_JSON WORKS PRETTY
WELL
38
{"samples": [
{ "name":"Jane Doe",
"age" : 42,
"profession": "architect",
"series": [
{
"day":0,
"measurement_value": 0.97
},
{
"day":1,
"measurement_value": 1.55
},
{
"day":2,
"measurement_value": 0.67
}
]},
{ name":"Bob Smith",
"hobbies":["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-38-320.jpg)
![NORMALIZE_JSON WORKS PRETTY
WELL
39
{"samples": [
{ "name":"Jane Doe",
"age" : 42,
"profession": "architect",
"series": [
{
"day":0,
"measurement_value": 0.97
},
{
"day":1,
"measurement_value": 1.55
},
{
"day":2,
"measurement_value": 0.67
}
]},
{ name":"Bob Smith",
"hobbies":["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-39-320.jpg)
![NORMALIZE_JSON WORKS PRETTY
WELL
40
{"samples": [
{ "name":"Jane Doe",
"age" : 42,
"profession": "architect",
"series": [
{
"day":0,
"measurement_value": 0.97
},
{
"day":1,
"measurement_value": 1.55
},
{
"day":2,
"measurement_value": 0.67
}
]},
{ name":"Bob Smith",
"hobbies":["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-40-320.jpg)
![NORMALIZE_JSON WORKS PRETTY
WELL
41
{"samples": [
{ "name": "Jane Doe",
"age" : 42,
"profession":"architect",
"series": [
{
"day": 0,
"measurement_value": 0.97
},
{
"day": 1,
"measurement_value": 1.55
},
{
"day": 2,
"measurement_value": 0.67
}
]},
{ name": "Bob Smith",
"hobbies": ["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}
>>with open(json_file) as data_file:
>> data = json.load(data_file)
>> normalized_data =
json_normalize(data['samples'])
Easy to process](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-41-320.jpg)
![NORMALIZE_JSON WORKS PRETTY
WELL
42
{"samples": [
{ "name": "Jane Doe",
"age" : 42,
"profession":"architect",
"series": [
{
"day": 0,
"measurement_value": 0.97
},
{
"day": 1,
"measurement_value": 1.55
},
{
"day": 2,
"measurement_value": 0.67
}
]},
{ name": "Bob Smith",
"hobbies": ["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}
>>with open(json_file) as data_file:
>> data = json.load(data_file)
>> normalized_data =
json_normalize(data['samples'])
Easy to process
>> print(normalized_data['series'][0])[1]
>> {u'measurement_value': 1.55, u'day': 1}
Basically,it just works](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-42-320.jpg)
![NORMALIZE_JSON WORKS PRETTY
WELL
43
{"samples": [
{ "name": "Jane Doe",
"age" : 42,
"profession":"architect",
"series": [
{
"day": 0,
"measurement_value": 0.97
},
{
"day": 1,
"measurement_value": 1.55
},
{
"day": 2,
"measurement_value": 0.67
}
]},
{ name": "Bob Smith",
"hobbies": ["tennis", "cooking"],
"age": 37,
"series":
{
"day": 0,
"measurement_value": 1.25
} }]}
>>with open(json_file) as data_file:
>> data = json.load(data_file)
>> normalized_data =
json_normalize(data['samples'])
Easy to process
Easy to add columns
>> normalized_data['length'] =
normalized_data['series'].apply(len)
>> print(normalized_data['series'][0])[1]
>> {u'measurement_value': 1.55, u'day': 1}
Basically,it just works](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-43-320.jpg)
![USING SOME PROGRAMMER STUFF ALSO HELPS
44
class dfList(list):
def __init__(self, originalValue):
if originalValue.__class__ is list().__class__:
self = originalValue
else:
self = list(originalValue)
def __getitem__(self, item):
result = list.__getitem__(self, item)
try:
return result[ITEM_TO_GET]
except:
return result
def __iter__(self):
for i in range(len(self)):
yield self.__getitem__(i)
def __call__(self):
return sum(self)/list.__len__(self)
• Subclass an iterable to shorten your
apply() calls](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-44-320.jpg)
![USING SOME PROGRAMMER STUFF ALSO HELPS
45
class dfList(list):
def __init__(self, originalValue):
if originalValue.__class__ is list().__class__:
self = originalValue
else:
self = list(originalValue)
def __getitem__(self, item):
result = list.__getitem__(self, item)
try:
return result[ITEM_TO_GET]
except:
return result
def __iter__(self):
for i in range(len(self)):
yield self.__getitem__(i)
def __call__(self):
return sum(self)/list.__len__(self)
• Subclass an iterable to shorten your
apply() calls
• In particular,you need to subclass at
least __getitem__ and __iter__](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-45-320.jpg)
![USING SOME PROGRAMMER STUFF ALSO HELPS
46
class dfList(list):
def __init__(self, originalValue):
if originalValue.__class__ is list().__class__:
self = originalValue
else:
self = list(originalValue)
def __getitem__(self, item):
result = list.__getitem__(self, item)
try:
return result[ITEM_TO_GET]
except:
return result
def __iter__(self):
for i in range(len(self)):
yield self.__getitem__(i)
def __call__(self):
return sum(self)/list.__len__(self)
• Subclass an iterable to shorten your
apply() calls
• In particular,you need to subclass at
least __getitem__ and __iter__
• You should probably subclass __init__
as well for the case of inconsistent
format](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-46-320.jpg)
![USING SOME PROGRAMMER STUFF ALSO HELPS
47
class dfList(list):
def __init__(self, originalValue):
if originalValue.__class__ is list().__class__:
self = originalValue
else:
self = list(originalValue)
def __getitem__(self, item):
result = list.__getitem__(self, item)
try:
return result[ITEM_TO_GET]
except:
return result
def __iter__(self):
for i in range(len(self)):
yield self.__getitem__(i)
def __call__(self):
return sum(self)/list.__len__(self)
• Subclass an iterable to shorten your
apply() calls
• In particular,you need to subclass at
least __getitem__ and __iter__
• You should probably subclass __init__
as well for the case of inconsistent
format
• Then __call__ can be a catch-all
adjustable function...best to loadit up
with a call to a class function, which
you can adjust at-will anytime.](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-47-320.jpg)



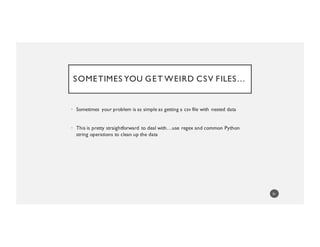


![SOMETIMES YOU GET WEIRD CSV FILES…
name,favorites,age
joe,"[madonna,elvis,u2]",28
mary,"[lady gaga, adele]",36
allen,"[beatles, u2, adele, rolling stones]"
This isn’t even that weird](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-54-320.jpg)
![SOMETIMES YOU GET WEIRD CSV FILES…
name,favorites,age
joe,"[madonna,elvis,u2]",28
mary,"[lady gaga, adele]",36
allen,"[beatles, u2, adele, rolling stones]"
This isn’t even that weird
>> df = pd.read_csv(file_name, sep =",")
Downright straightforward](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-55-320.jpg)
![SOMETIMES YOU GET WEIRD CSV FILES…
56
name,favorites,age
joe,"[madonna,elvis,u2]",28
mary,"[lady gaga, adele]",36
allen,"[beatles, u2, adele, rolling stones]"
This isn’t even that weird
>> df = pd.read_csv(file_name, sep =",")
Downright straightforward
Hmmm….
>> print(df['favorites'][0][1])
>> m](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-56-320.jpg)
![SOMETIMES YOU GET WEIRD CSV FILES…
57
name,favorites,age
joe,"[madonna,elvis,u2]",28
mary,"[lady gaga, adele]",36
allen,"[beatles, u2, adele, rolling stones]"
This isn’t even that weird
>> df = pd.read_csv(file_name, sep =",")
Downright straightforward
Hmmm….
>> print(df['favorites'][0][1])
>> m
Regex to the rescue…Python’s exceptionally easy string parsing a huge asset for No-SQL parsing
>> df['favorites'] = df['favorites'].apply(lambda s: s[1:-1].split())
>> print(df['favorites'][0][1])
>> adele](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-57-320.jpg)
![WHAT ABOUT THIS ONE?
58
name,favorites,age
joe,[madonna,elvis,u2],28
mary,[lady gaga, adele],36
allen,[beatles, u2, adele, rolling stones]
This isn’t even that weird
>> df = pd.read_csv(file_name, sep =",")
Downright straightforward?
Actually this fails miserably
>> print(df['favorites'])
>> joe [madonna elvis u2]
mary [lady gaga adele] 36
Name: name, dtype: object
We need more regex…this time before applying read_csv()....](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-58-320.jpg)
![59
name,favorites,age
joe,[madonna,elvis,u2],28
mary,[lady gaga, adele],36
allen,[beatles, u2, adele, rolling stones]
Missing quotes arouns arrays:
Basically,put in a the quotation marks to help out read_csv()](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-59-320.jpg)
![60
name,favorites,age
joe,[madonna,elvis,u2],28
mary,[lady gaga, adele],36
allen,[beatles, u2, adele, rolling stones]
Missing quotes arouns arrays:
pattern = "([.*])"
with open(file_name) as f:
for line in f:
new_line = line
match = re.finditer(pattern, line)
try:
m = match.next()
while m:
replacement = '"'+m.group(1)+'"'
new_line = new_line.replace(m.group(1), replacement)
m = match.next()
except:
pass
with open(write_file, 'a') as write_f:
write_f.write(new_line)
new_df = pd.read_csv(write_file)
Basically,put in a the quotation marks to help out read_csv()](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-60-320.jpg)
![61
name,favorites,age
joe,[madonna,elvis,u2],28
mary,[lady gaga, adele],36
allen,[beatles, u2, adele, rolling stones]
Missing quotes arouns arrays:
pattern = "([.*])"
with open(file_name) as f:
for line in f:
new_line = line
match = re.finditer(pattern, line)
try:
m = match.next()
while m:
replacement = '"'+m.group(1)+'"'
new_line = new_line.replace(m.group(1), replacement)
m = match.next()
except:
pass
with open(write_file, 'a') as write_f:
write_f.write(new_line)
new_df = pd.read_csv(write_file)
Basically,put in a the quotation marks to help out read_csv()
With multiple arrays per row,you’re gonna need to accommodate the greedy nature of regex
pattern = "([.*?])"](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-61-320.jpg)
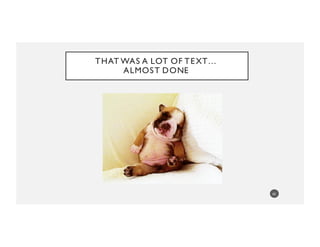
![SOMETIMES YOU GET JSON AND YOU KNOW
THE STRUCTURE,YOU JUST DON’T LIKE IT
• Use json_normalize()and then shed columns you don’t want.You’ve seen that
today already (slides 32-38).
• Use some magic: sh with jq module to simplify your life…you can pick out the
fields you want with jq either on the command line or with sh
• jq has a straightforward,easy to learn syntax:. = value,[] = array operation,etc… 63
cat = sh.cat
jq = sh.jq
rule = """[{name: .samples[].name, days: .samples[].series[].day}]""”
out = jq(rule, cat(_in=json_data)).stdout
json.loads(uni_out)](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-63-320.jpg)


![YOU’RE A PROGRAMMER…USE ITERATORS
66
with open(file_name, 'rb') as file:
results = ijson.items(file, "samples.item")
for newRecord in results:
record = newRecord
for k in record.keys():
if isinstance(record[k], dict().__class__):
recursive_check(record[k])
if isinstance(record[k], list().__class__):
recursive_check(record[k])
process(record)](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-66-320.jpg)
![YOU’RE A PROGRAMMER…USE ITERATORS
67
total_dict = defaultdict(lambda: False)
def recursive_check(d):
if isinstance(d, dict().__class__):
if not total_dict[tuple(sorted(d.keys()))]:
class_name = raw_input("Input the new classname with a
space and then the file name defining the class ")
mod = import_module(class_name)
cls = getattr(mod, class_name)
total_dict[tuple(sorted(d.keys()))] = cls
for k in d.keys():
new_class = recursive_check(k)
if new_class:
d[k] = new_class(**d[k])
return total_dict[tuple(sorted(d.keys()))]
elif isinstance(d, list().__class__):
for i in range(len(d)):
new_class = recursive_check(d[i])
if new_class:
d[i] = new_class(**d[i])
else:
return False
• Basically,you can build custom classes
or generate appropriate named tuples
as you go.
• This lets you know what you have and
lets you build data structures to
accommodate what you have.
• Storing these objects in a class rather
than simple dictionary again gives you
the option to customize .__call__()
to your needs](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-67-320.jpg)
![YOU’RE A PROGRAMMER…USE ITERATORS
68
total_dict = defaultdict(lambda: False)
def recursive_check(d):
if isinstance(d, dict().__class__):
if not total_dict[tuple(sorted(d.keys()))]:
class_name = raw_input("Input the new classname with a space and then the file name defining the class ")
mod = import_module(class_name)
cls = getattr(mod, class_name)
total_dict[tuple(sorted(d.keys()))] = cls
for k in d.keys():
new_class = recursive_check(k)
if new_class:
d[k] = new_class(**d[k])
return total_dict[tuple(sorted(d.keys()))]
elif isinstance(d, list().__class__):
for i in range(len(d)):
new_class = recursive_check(d[i])
if new_class:
d[i] = new_class(**d[i])
else:
return False
• Basically, you can build custom classes or
generate appropriate Named tuples as you go.
This lets you know what you have and lets you
build data structures to accommodate what you
have.
• Again remember that class methods can easily
be adjusted dynamically,so it’s good to code
classes with instances that reference class
methods.](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-68-320.jpg)

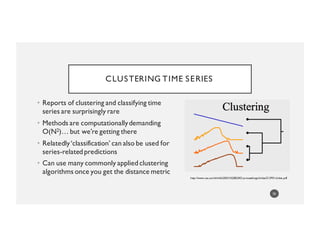


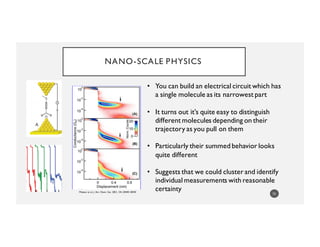






![WHY?
Time series classification and related metrics can be one more thing to
know…or even several more things to know
82
Name Ordered
Scores
Score
Trajectory Type
Number of
Tests
Predicted
Score For
Next Test
Joe [1, 14, 17] good 3 19
Mary [11, 14, 9] meh 3 11
Allen [25, NA, 9] underachiever 2 35
Info from classification
Info from prediction
Info from
easy apply()
calls](https://image.slidesharecdn.com/pydataamsterdam-160405151750/85/Aileen-Nielsen-NoSQL-Python-making-data-frames-work-for-you-in-a-non-rectangular-world-82-320.jpg)






This document discusses NoSQL data and Python. It begins by providing an example of tidy SQL-like data and shows how changing the organizing principle to group data by individual "actors" can enable new types of analysis questions to be easily answered. The document argues that as data becomes less structured, with arbitrarily nested and ragged elements, a NoSQL approach is better suited than a relational SQL database. It provides examples of where NoSQL data arises and discusses approaches to working with such data in Python, including using JSON normalization to import semi-structured data into Pandas DataFrames.














![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)








![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)











































