



















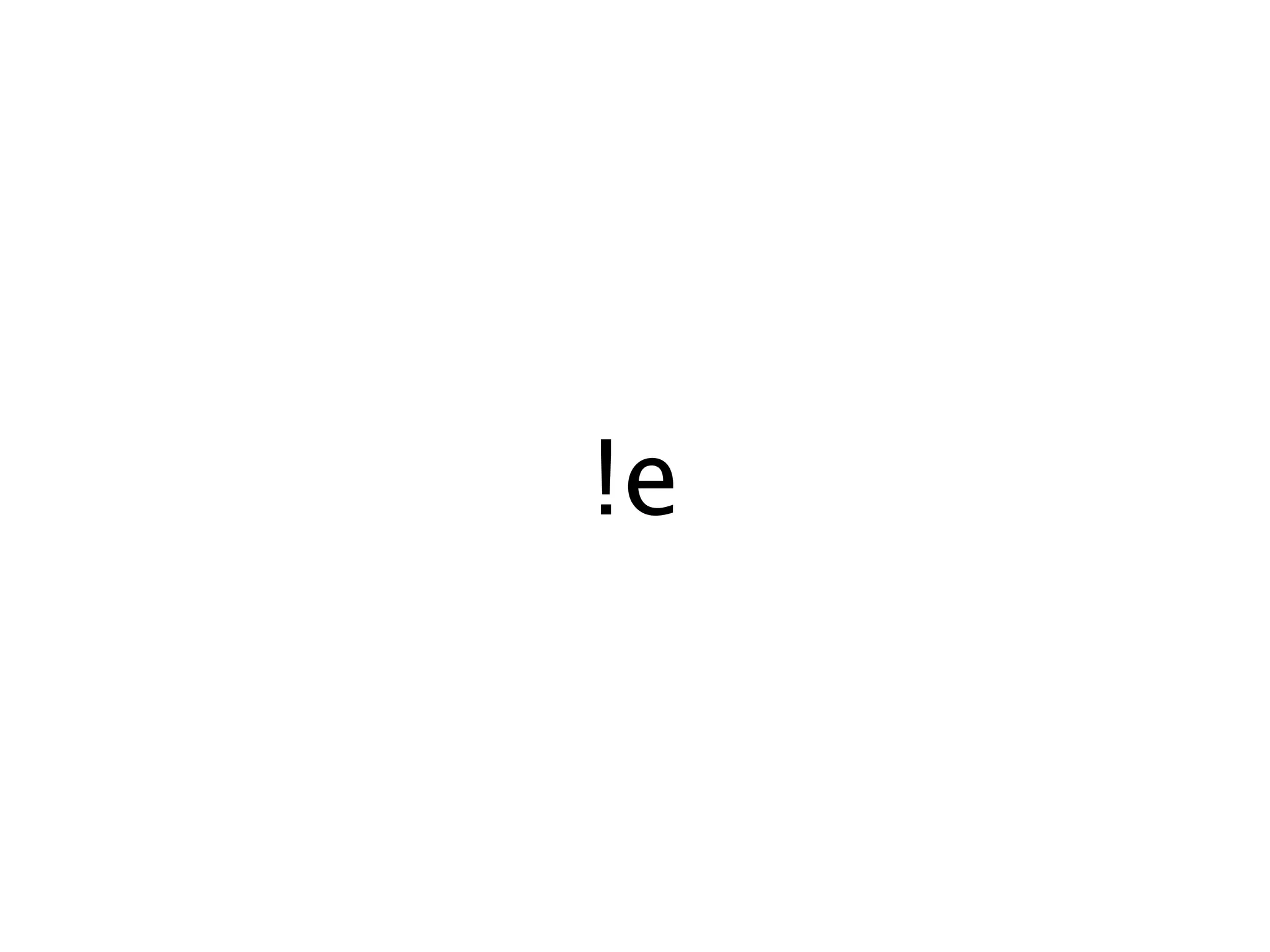
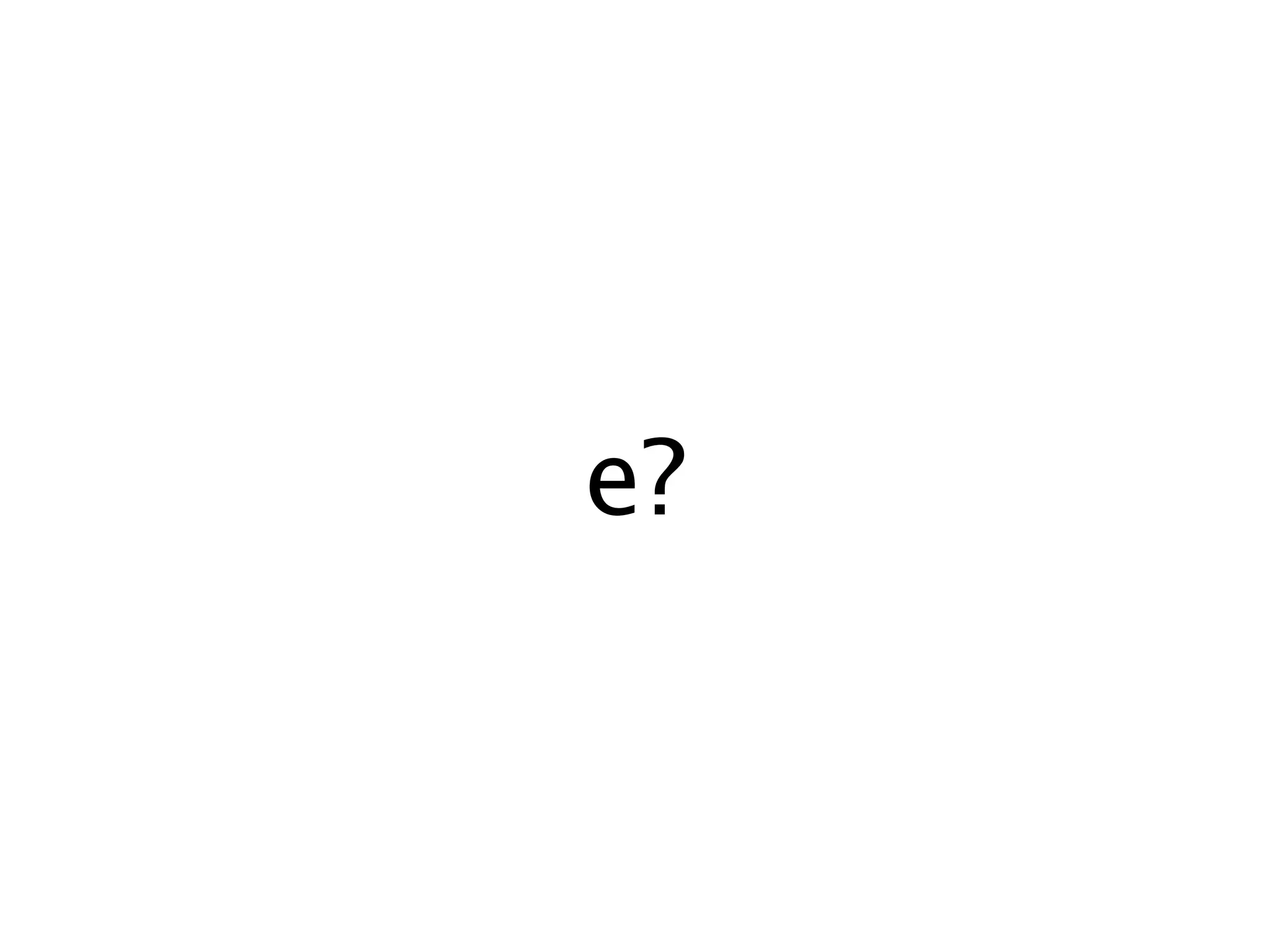
![“string”
[A-Z]
.](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-23-2048.jpg)
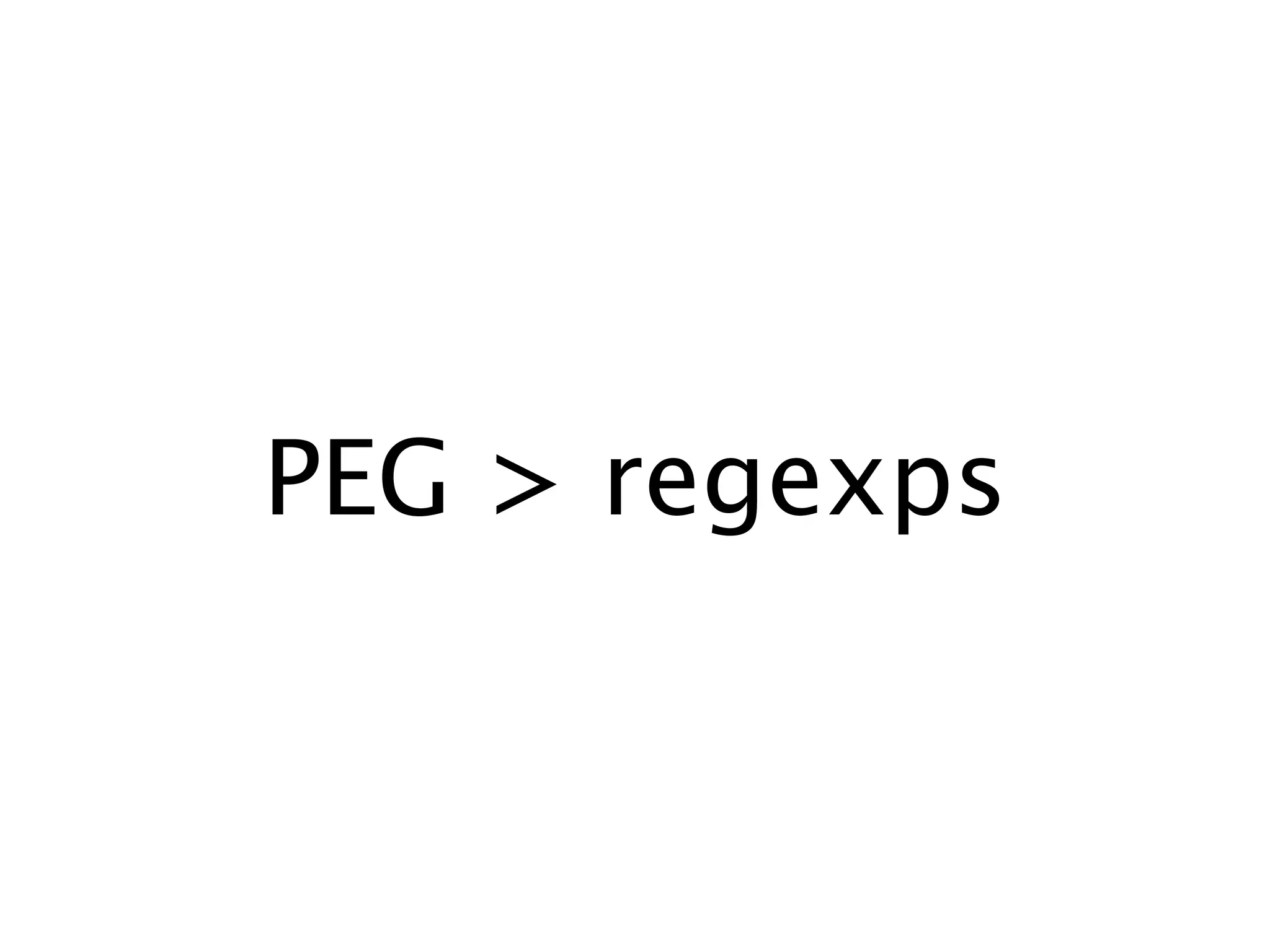
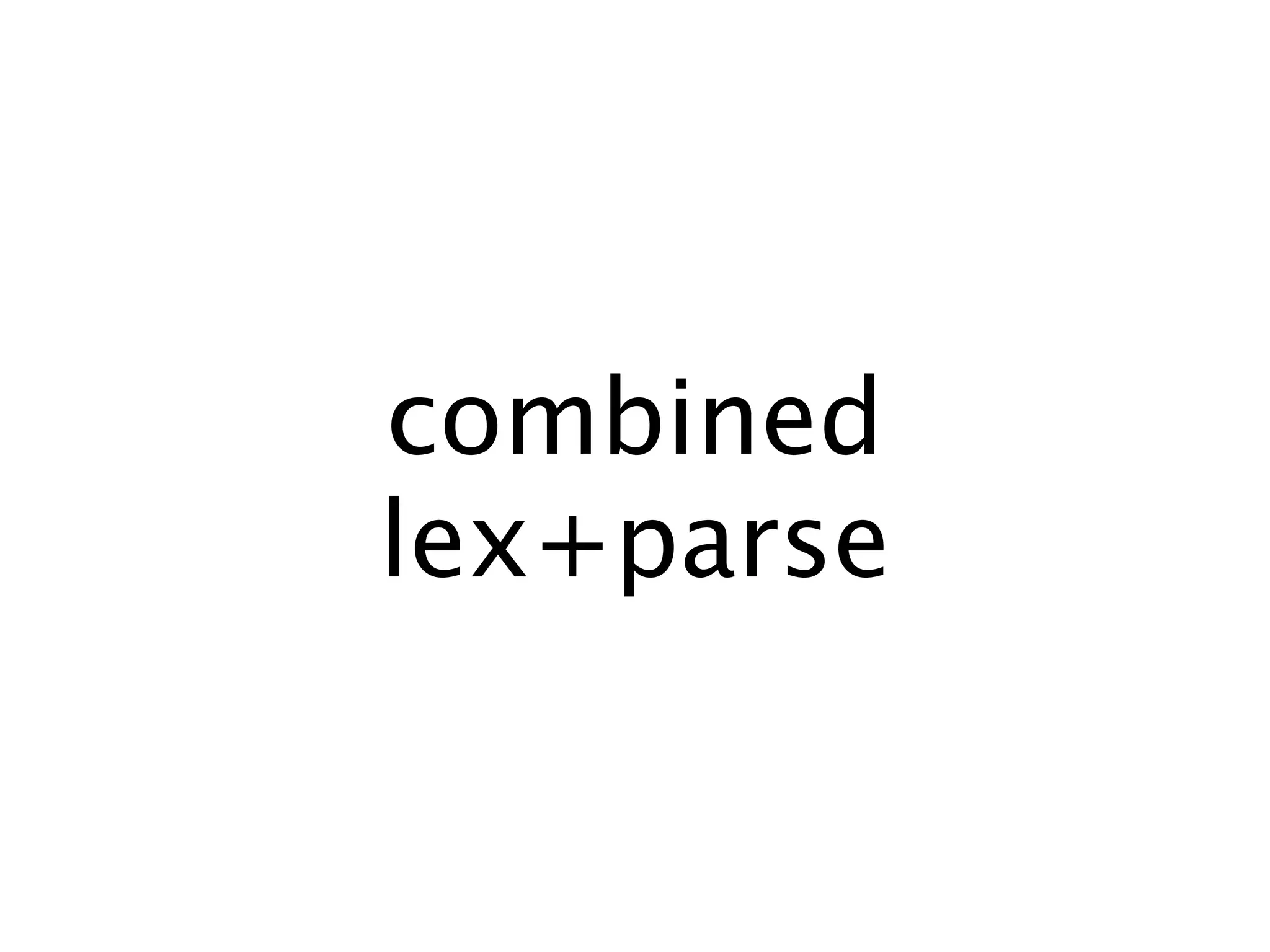
















![Definitions.
D = [0-9]
IDENT = [a-z|A-Z|0-9|_|-]
Rules.
_ : {token, {underscore, TokenLine, TokenChars}}.
- : {token, {dash, TokenLine, TokenChars}}.
% : {token, {tag_start, TokenLine, TokenChars}}.
. : {token, {class_start, TokenLine, TokenChars}}.
# : {token, {id_start, TokenLine, TokenChars}}.
{D}+ : {token, {number, TokenLine, list_to_integer(TokenChars)}}.
'(^.|.|[^'])*' :
S = lists:sublist(TokenChars, 2, TokenLen - 2),
{token, {string, TokenLine, S}}.
{IDENT}+ : {token, {chr, TokenLine, TokenChars}}.
{ : {token, {lcurly, TokenLine, TokenChars}}.
} : {token, {rcurly, TokenLine, TokenChars}}.
[ : {token, {lbrace, TokenLine, TokenChars}}.
] : {token, {rbrace, TokenLine, TokenChars}}.
@ : {token, {at, TokenLine, TokenChars}}.
, : {token, {comma, TokenLine, TokenChars}}.
' : {token, {quote, TokenLine, TokenChars}}.
: : {token, {colon, TokenLine, TokenChars}}.
/ : {token, {slash, TokenLine, TokenChars}}.
! : {token, {bang, TokenLine, TokenChars}}.
( : {token, {lparen, TokenLine, TokenChars}}.
) : {token, {rparen, TokenLine, TokenChars}}.
| : {token, {pipe, TokenLine, TokenChars}}.
< : {token, {lt, TokenLine, TokenChars}}.
> : {token, {gt, TokenLine, TokenChars}}.
s+ : {token, {space, TokenLine, TokenChars}}.
Erlang code.](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-44-2048.jpg)
![Rootsymbol template_stmt.
template_stmt -> doctype : '$1'.
template_stmt -> var_ref : '$1'.
template_stmt -> iter : '$1'.
template_stmt -> fun_call : '$1'.
template_stmt -> tag_decl : '$1'.
%% doctype selector
doctype -> bang bang bang : {doctype, "Transitional", []}.
doctype -> bang bang bang space : {doctype, "Transitional", []}.
doctype -> bang bang bang space doctype_name : {doctype, '$5', []}.
doctype -> bang bang bang space doctype_name space doctype_name : {doctype, '$5', '$7'}.
doctype_name -> doctype_name_elem doctype_name : '$1' ++ '$2'.
doctype_name -> doctype_name_elem : '$1'.
doctype_name_elem -> chr : unwrap('$1').
doctype_name_elem -> dash : "-".
doctype_name_elem -> class_start : ".".
doctype_name_elem -> number : number_to_list('$1').
%% Variable reference for emitting, iterating, and passing to funcalls
var_ref -> at name : {var_ref, unwrap('$2')}.
var_ref -> at name lbrace number rbrace : {var_ref, unwrap('$2'), unwrap('$4')}.
%% Iterator
iter -> dash space list_open iter_item list_close space lt dash space var_ref : {iter, '$4', '$10'}.
iter_list -> iter_item : ['$1'].
iter_list -> iter_item list_sep iter_list : ['$1'|'$3'].
iter_item -> underscore : ignore.
iter_item -> var_ref : '$1'.
iter_item -> tuple_open iter_list tuple_close: {tuple, '$2'}.
iter_item -> list_open iter_list list_close: {list, '$2'}.
%% Function calls
fun_call -> at name colon name params_open params_close : {fun_call, name_to_atom('$2'), name_to_atom('$4'), []}.
fun_call -> at name colon name params_open param_list params_close : {fun_call, name_to_atom('$2'), name_to_atom('$4'), '$6'}.
fun_call -> at name colon name : {fun_call, name_to_atom('$2'), name_to_atom('$4'), []}.
fun_call -> at at name colon name params_open params_close : {fun_call_env, name_to_atom('$3'), name_to_atom('$5'), []}.
fun_call -> at at name colon name params_open param_list params_close : {fun_call_env, name_to_atom('$3'), name_to_atom('$5'), '$7'}.
fun_call -> at at name colon name : {fun_call_env, name_to_atom('$3'), name_to_atom('$5'), []}.
param_list -> param : ['$1'].](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-45-2048.jpg)





![% Implements "?" PEG operator
p_optional(P) ->
fun(Input, Index) ->
case P(Input, Index) of
{fail, _} -> {[], Input, Index};
{_,_,_} = Success -> Success
% {Parsed, RemainingInput, NewIndex}
end
end.](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-51-2048.jpg)



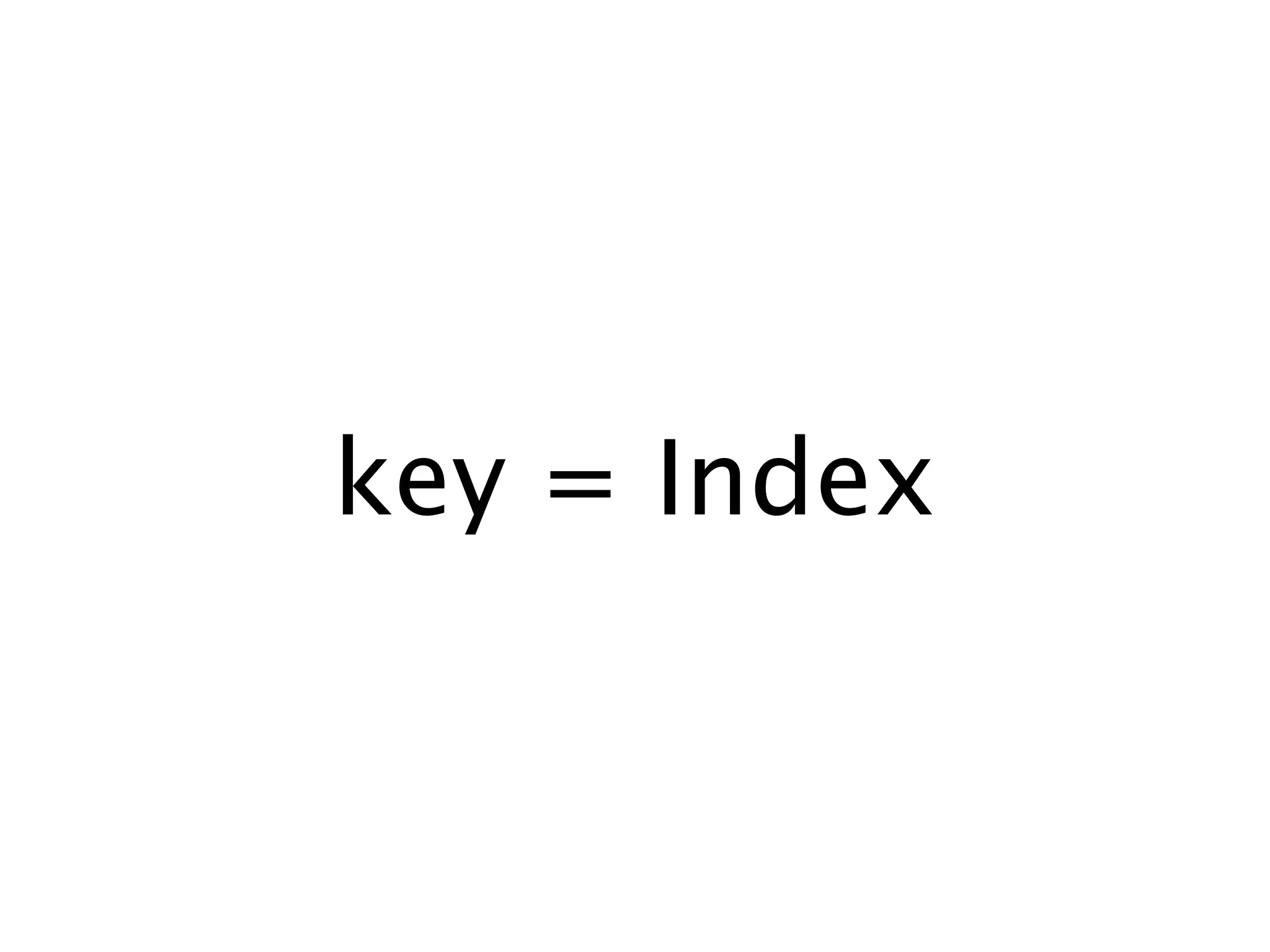
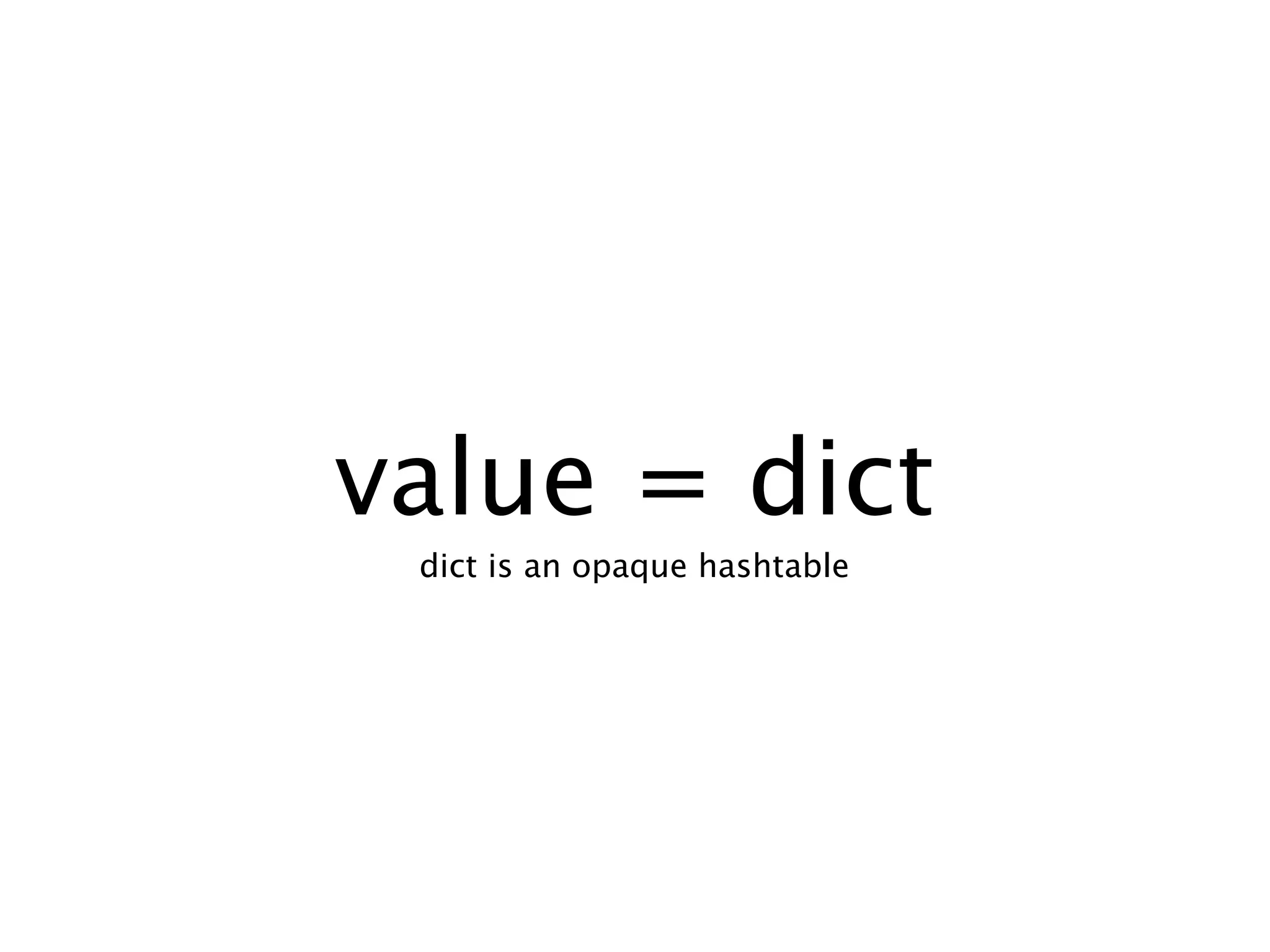


![rules <- space? declaration_sequence space?;
declaration_sequence <- head:declaration tail:(space declaration)*;
declaration <- nonterminal space '<-' space parsing_expression space? ';';
parsing_expression <- choice / sequence / primary;
choice <- head:alternative tail:(space '/' space alternative)+;
alternative <- sequence / primary;
primary <- prefix atomic / atomic suffix / atomic;
sequence <- head:labeled_sequence_primary tail:(space labeled_sequence_primary)+;
labeled_sequence_primary <- label? primary;
label <- alpha_char alphanumeric_char* ':';
suffix <- repetition_suffix / optional_suffix;
optional_suffix <- '?';
repetition_suffix <- '+' / '*';
prefix <- '&' / '!';
atomic <- terminal / nonterminal / parenthesized_expression;
parenthesized_expression <- '(' space? parsing_expression space? ')';
nonterminal <- alpha_char alphanumeric_char*;
terminal <- quoted_string / character_class / anything_symbol;
quoted_string <- single_quoted_string / double_quoted_string;
double_quoted_string <- '"' string:(!'"' ("" / '"' / .))* '"';
single_quoted_string <- "'" string:(!"'" ("" / "'" / .))* "'";
character_class <- '[' characters:(!']' ('' . / !'' .))+ ']
anything_symbol <- '.';
alpha_char <- [a-z_];
alphanumeric_char <- alpha_char / [0-9];
space <- (white / comment_to_eol)+;
comment_to_eol <- '%' (!"n" .)*;
white <- [ tnr];](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-60-2048.jpg)




!['atomic'(Input, Index) ->
p(Input, Index, 'atomic',
fun(I,D) ->
(p_choose([
fun 'terminal'/2,
fun 'nonterminal'/2,
fun 'parenthesized_expression'/2]))(I,D) end,
fun(Node, Idx) ->
case Node of
{'nonterminal', Symbol} ->
add_nt(Symbol, Idx),
"fun '" ++ Symbol ++ "'/2";
Any -> Any
end
end).](https://image.slidesharecdn.com/achievingparsingsanityinerlang-091110213937-phpapp02/75/Achieving-Parsing-Sanity-In-Erlang-66-2048.jpg)




The document discusses the Neotoma parsing library in Erlang, focusing on parsing expression grammars (PEGs) as a method for resolving ambiguities in context-free grammars. It covers various parsing techniques, including recursive descent and memoization, along with practical examples of code implementation. The text also touches upon advanced topics such as inline code generation and the use of higher-order functions in parser construction.
























































![codin9cafe[2015.02.25]Open course(programming languages) - 장철호(Ch Jang)](https://cdn.slidesharecdn.com/ss_thumbnails/opencourseprogramminglanguages20150225-160712053441-thumbnail.jpg?width=640&height=640&fit=bounds)















































