This document outlines various vices that can occur in software testing and proposes strategies to address them. It discusses gluttony, greed, sloth, envy, pride, kenodoxia, and desire/anger in testing and provides examples of how each vice could manifest and techniques to prevent issues, such as not mocking more than necessary to avoid gluttony, writing tests that clean up after themselves to prevent sloth, and using a modest approach to testing rather than an overly assertive one to avoid envy and boasting.
The Experimenter's ToolKit: Finding Product-Market Fit ajay rajani
This document discusses product/market fit and how to find it through experimentation. It contains the following key points:
1. Experiments are valuable for gaining competitive advantages over others and improving your own products through comparative testing and data-driven insights.
2. Finding product/market fit requires light-weight tests like messaging to listen to users and study data through cohort analysis, then escalating experiments over time to establish causation and optimize.
3. Staying sane during the process of experimentation to find product/market fit is important and requires managing expectations and stress.
This document shows pictures of winter clothing items - a hat, scarf, coat, and gloves. The names of the items are listed out of order and the task is to match each picture with the correct clothing name and color the pictures as desired.
The Best Employee Communications Tool You Already Own But Aren't UsingJWTINSIDE
Presented by J. Walter Thompson INSIDE and Globant. Looking for an inexpensive way to boost your employment communications? Many companies are turning to SharePoint to create custom websites that promote their brands and opportunities both internally and externally, with minimal effort required from IT personnel. In our upcoming webinar, we’ll take an in-depth look at this often-untapped resource and explore the many capabilities and benefits it has to offer. You may be surprised by what you can do – and achieve.
This document outlines various vices that can occur in software testing and proposes strategies to address them. It discusses gluttony, greed, sloth, envy, pride, kenodoxia, and desire/anger in testing and provides examples of how each vice could manifest and techniques to prevent issues, such as not mocking more than necessary to avoid gluttony, writing tests that clean up after themselves to prevent sloth, and using a modest approach to testing rather than an overly assertive one to avoid envy and boasting.
The Experimenter's ToolKit: Finding Product-Market Fit ajay rajani
This document discusses product/market fit and how to find it through experimentation. It contains the following key points:
1. Experiments are valuable for gaining competitive advantages over others and improving your own products through comparative testing and data-driven insights.
2. Finding product/market fit requires light-weight tests like messaging to listen to users and study data through cohort analysis, then escalating experiments over time to establish causation and optimize.
3. Staying sane during the process of experimentation to find product/market fit is important and requires managing expectations and stress.
This document shows pictures of winter clothing items - a hat, scarf, coat, and gloves. The names of the items are listed out of order and the task is to match each picture with the correct clothing name and color the pictures as desired.
The Best Employee Communications Tool You Already Own But Aren't UsingJWTINSIDE
Presented by J. Walter Thompson INSIDE and Globant. Looking for an inexpensive way to boost your employment communications? Many companies are turning to SharePoint to create custom websites that promote their brands and opportunities both internally and externally, with minimal effort required from IT personnel. In our upcoming webinar, we’ll take an in-depth look at this often-untapped resource and explore the many capabilities and benefits it has to offer. You may be surprised by what you can do – and achieve.
lingual orthodontics courses in india /certified fixed orthodontic courses by...Indian dental academy
The Indian Dental Academy is the Leader in continuing dental education , training dentists in all aspects of dentistry and offering a wide range of dental certified courses in different formats.
Indian dental academy provides dental crown & Bridge,rotary endodontics,fixed orthodontics,
Dental implants courses.for details pls visit www.indiandentalacademy.com ,or call
0091-9248678078
AWS Enterprise Summit London | Shop Direct Leveraging the Cloud for Success i...Amazon Web Services
Shop Direct leveraged AWS cloud services to drive success in digital retail by allowing them to scale their business efficiently based on fluctuating customer demand while reducing costs. The transition to AWS provided Shop Direct with increased site availability, reliability, and cost-effectiveness. In the long term, Shop Direct aims to optimize storage, enable personalization through big data analytics, and experiment at scale using AWS flexible infrastructure.
The document discusses different assessment methods in social science, including rubrics, problem-based, and case-based methods. It focuses on problem-based assessment, where students learn by delving into real problems and reflecting on their learning progress. An example given is a medical problem presented to students over three meetings, where they discuss findings and share understandings to illustrate problem-based assessment. Commonly cited learning problems include an inability to transfer learning or advance beyond lower cognition levels.
Gastroesophageal Reflux With Relevance To Pediatric SurgeryRavi Kanojia
This document discusses gastroesophageal reflux (GER) in pediatric surgery patients, specifically those with tracheoesophageal fistula (TEF). It finds that GER is common in TEF patients, occurring in 30-70% and often requiring fundoplication. GER exacerbates complications like strictures. Factors like anastomotic tension, gastrostomy, and abnormal gastric motility may contribute. Treatment involves positioning, medications, and antireflux surgery if needed. GER is also common in other conditions like congenital diaphragmatic hernia and abdominal wall defects. Long term follow up is important to monitor for complications.
VCADS Elite is a Windows-based software tool used to test, calibrate, and program parameters on Volvo ECUs. It provides functions for Volvo vehicles equipped with Vehicle Electronics '98 or VERSION2 electronic control systems. The manual describes how to install VCADS Elite on a PC and connect it to a vehicle to test and adjust customer parameters on ECUs using the software's graphical interfaces. Proper PC and network setup is required before installation. A user ID is assigned to each user for access.
Magento technology has been adopted by over 100,000 stores worldwide, which makes it the fastest growing open-source e-commerce platform. A technical overview of Magento's system architecture will cover layers including libraries in PHP and JavaScript, configuration, controllers, event-driven models, blocks and templates, layout XML, customization and core APIs for integration.
The document categorizes and describes various types of construction equipment. It divides equipment into four main groups: (1) earthmoving equipment like excavators and loaders used for digging and material handling; (2) construction vehicles like dumpers and trailers used for transportation; (3) material handling equipment like cranes, conveyors, and forklifts used to move materials; and (4) other construction equipment like tunneling machines, concrete mixers, and pavers used for specific tasks. Within each group, the document provides examples and brief descriptions of common piece of equipment.
Inżynieria społeczna jako element testów bezpieczeństwa - tylko teoria, czy j...The Software House
Monika Sadlok - Inżynieria społeczna jako element testów bezpieczeństwa - tylko teoria, czy już niezbędna praktyka?
www.tsh.io
Dlaczego miły, uprzejmy i towarzyski pracownik stanowi jedno z największych zagrożeń bezpieczeństwa każdej firmy czy organizacji? Ponieważ to jego pozytywne cechy charakteru wykorzystywane są przez osoby próbujące uzyskać dostęp do chronionych informacji w sposób nieuprawniony. Czy zatem testy bezpieczeństwa powinny uwzględniać metodologię inżynierii społecznej? Z pewnością tak. O tym będzie moja prezentacja.
Krzysztof Moskwa - Podstawy metod zwinnych: jak to działa? Story points, czyl...PMI Szczecin
Krzysztof Moskwa. Krzysztof ma ponad dziesięć lat doświadczenia w prowadzeniu projektów produkcji oprogramowania. Obecnie pracuje w firmie Orad (część Avid Technology). Absolwent Politechniki Wrocławskiej oraz Studium MBA US. Posiadacz certyfikatu PMP Project Managment Institute. Wspiera lokalny oddział PMI Szczecin jako wolontariusz.
Temat wystąpienia to "Podstawy Metod Zwinnych: Jak to działa? Story Points, czyli Jednostki Wartości."
Czwarta cześć kursu zarządzania działaniem według metody Getting Things Done. W tej prezentacji poznacie algorytm analizy spraw zgromadzonych w skrzynce spraw przychodzących oraz dowiecie się, dlaczego ważne jest regularne przeglądanie systemu GTD.
E-kurs zorganizowany przez sekcję PR konferencji Giełda Prac Dyplomowych.
Apache JMeter™ to otwarte oprogramowanie, napisane w Javie i dedykowane do wykonywania testów obciążeniowych, wydajnościowych oraz funkcjonalnych. Oryginalnie było projektowane i rozwijane przez Stefano Mazzocchi z Apache Software Foundation, który napisał go do testowania wydajności Apache JServ (projektu, który został zastąpiony przez Apache Tomcat). Następnie JMeter został przeprojektowany i wyposażony w GUI celem rozszerzenia jego zastosowań do testów funkcjonalnych. W listopadzie 2011 roku JMeter stał się projektem Apache najwyższego poziomu (ang. top level), co oznacza, że zyskał społeczność odpowiedzialną za jego rozwój (ang. Project Management Commitee) oraz dedykowany serwis.
Apache JMeter jest używany do testowania wydajności statycznych oraz dynamicznych zasobów takich jak pliki, dynamiczne języki programowania serwisów internetowych, np. PHP, Java, ASP.NET, itp., obiekty Java, bazy danych i kwerendy, serwery FTP, itp. Z powodzeniem jest wykorzystywany do symulowania wzmożonego ruchu na serwerze, grupie serwerów, w sieci lub na „hartowanym” obiekcie. Służy również do analizowania całkowitej wydajności pod obciążeniem różnego typu, np. do graficznej analizy całkowitej wydajności lub do testowania zachowania się serwera / skryptu / obiektu przy wzmożonym i zrównoleglonym obciążeniu.
lingual orthodontics courses in india /certified fixed orthodontic courses by...Indian dental academy
The Indian Dental Academy is the Leader in continuing dental education , training dentists in all aspects of dentistry and offering a wide range of dental certified courses in different formats.
Indian dental academy provides dental crown & Bridge,rotary endodontics,fixed orthodontics,
Dental implants courses.for details pls visit www.indiandentalacademy.com ,or call
0091-9248678078
AWS Enterprise Summit London | Shop Direct Leveraging the Cloud for Success i...Amazon Web Services
Shop Direct leveraged AWS cloud services to drive success in digital retail by allowing them to scale their business efficiently based on fluctuating customer demand while reducing costs. The transition to AWS provided Shop Direct with increased site availability, reliability, and cost-effectiveness. In the long term, Shop Direct aims to optimize storage, enable personalization through big data analytics, and experiment at scale using AWS flexible infrastructure.
The document discusses different assessment methods in social science, including rubrics, problem-based, and case-based methods. It focuses on problem-based assessment, where students learn by delving into real problems and reflecting on their learning progress. An example given is a medical problem presented to students over three meetings, where they discuss findings and share understandings to illustrate problem-based assessment. Commonly cited learning problems include an inability to transfer learning or advance beyond lower cognition levels.
Gastroesophageal Reflux With Relevance To Pediatric SurgeryRavi Kanojia
This document discusses gastroesophageal reflux (GER) in pediatric surgery patients, specifically those with tracheoesophageal fistula (TEF). It finds that GER is common in TEF patients, occurring in 30-70% and often requiring fundoplication. GER exacerbates complications like strictures. Factors like anastomotic tension, gastrostomy, and abnormal gastric motility may contribute. Treatment involves positioning, medications, and antireflux surgery if needed. GER is also common in other conditions like congenital diaphragmatic hernia and abdominal wall defects. Long term follow up is important to monitor for complications.
VCADS Elite is a Windows-based software tool used to test, calibrate, and program parameters on Volvo ECUs. It provides functions for Volvo vehicles equipped with Vehicle Electronics '98 or VERSION2 electronic control systems. The manual describes how to install VCADS Elite on a PC and connect it to a vehicle to test and adjust customer parameters on ECUs using the software's graphical interfaces. Proper PC and network setup is required before installation. A user ID is assigned to each user for access.
Magento technology has been adopted by over 100,000 stores worldwide, which makes it the fastest growing open-source e-commerce platform. A technical overview of Magento's system architecture will cover layers including libraries in PHP and JavaScript, configuration, controllers, event-driven models, blocks and templates, layout XML, customization and core APIs for integration.
The document categorizes and describes various types of construction equipment. It divides equipment into four main groups: (1) earthmoving equipment like excavators and loaders used for digging and material handling; (2) construction vehicles like dumpers and trailers used for transportation; (3) material handling equipment like cranes, conveyors, and forklifts used to move materials; and (4) other construction equipment like tunneling machines, concrete mixers, and pavers used for specific tasks. Within each group, the document provides examples and brief descriptions of common piece of equipment.
Inżynieria społeczna jako element testów bezpieczeństwa - tylko teoria, czy j...The Software House
Monika Sadlok - Inżynieria społeczna jako element testów bezpieczeństwa - tylko teoria, czy już niezbędna praktyka?
www.tsh.io
Dlaczego miły, uprzejmy i towarzyski pracownik stanowi jedno z największych zagrożeń bezpieczeństwa każdej firmy czy organizacji? Ponieważ to jego pozytywne cechy charakteru wykorzystywane są przez osoby próbujące uzyskać dostęp do chronionych informacji w sposób nieuprawniony. Czy zatem testy bezpieczeństwa powinny uwzględniać metodologię inżynierii społecznej? Z pewnością tak. O tym będzie moja prezentacja.
Krzysztof Moskwa - Podstawy metod zwinnych: jak to działa? Story points, czyl...PMI Szczecin
Krzysztof Moskwa. Krzysztof ma ponad dziesięć lat doświadczenia w prowadzeniu projektów produkcji oprogramowania. Obecnie pracuje w firmie Orad (część Avid Technology). Absolwent Politechniki Wrocławskiej oraz Studium MBA US. Posiadacz certyfikatu PMP Project Managment Institute. Wspiera lokalny oddział PMI Szczecin jako wolontariusz.
Temat wystąpienia to "Podstawy Metod Zwinnych: Jak to działa? Story Points, czyli Jednostki Wartości."
Czwarta cześć kursu zarządzania działaniem według metody Getting Things Done. W tej prezentacji poznacie algorytm analizy spraw zgromadzonych w skrzynce spraw przychodzących oraz dowiecie się, dlaczego ważne jest regularne przeglądanie systemu GTD.
E-kurs zorganizowany przez sekcję PR konferencji Giełda Prac Dyplomowych.
Apache JMeter™ to otwarte oprogramowanie, napisane w Javie i dedykowane do wykonywania testów obciążeniowych, wydajnościowych oraz funkcjonalnych. Oryginalnie było projektowane i rozwijane przez Stefano Mazzocchi z Apache Software Foundation, który napisał go do testowania wydajności Apache JServ (projektu, który został zastąpiony przez Apache Tomcat). Następnie JMeter został przeprojektowany i wyposażony w GUI celem rozszerzenia jego zastosowań do testów funkcjonalnych. W listopadzie 2011 roku JMeter stał się projektem Apache najwyższego poziomu (ang. top level), co oznacza, że zyskał społeczność odpowiedzialną za jego rozwój (ang. Project Management Commitee) oraz dedykowany serwis.
Apache JMeter jest używany do testowania wydajności statycznych oraz dynamicznych zasobów takich jak pliki, dynamiczne języki programowania serwisów internetowych, np. PHP, Java, ASP.NET, itp., obiekty Java, bazy danych i kwerendy, serwery FTP, itp. Z powodzeniem jest wykorzystywany do symulowania wzmożonego ruchu na serwerze, grupie serwerów, w sieci lub na „hartowanym” obiekcie. Służy również do analizowania całkowitej wydajności pod obciążeniem różnego typu, np. do graficznej analizy całkowitej wydajności lub do testowania zachowania się serwera / skryptu / obiektu przy wzmożonym i zrównoleglonym obciążeniu.
Ostatnia - szósta - prezentacja z kursu zarządzania działaniem według metody Getting Things Done. Prezentacja podsumowuje najważniejsze wiadomości z kursu oraz pokazuje, jakie zmiany można wprowadzić w życiu dzięki zastosowaniu metody GTD.
E-kurs zorganizowany przez sekcję PR konferencji Giełda Prac Dyplomowych.
Tdd - Czyli jak tworzyć dobre jakościowo aplikacje
7 cardinal sins of testing - Artykul
1. Wiele zostało już napisane na temat anty-wzorców jakie obserwujemy w świecie testów automatycznych. James Carr i jego „TDD Anti-Patterns” to lektura obowiązkową dla
każdego, kto chce uniknąć podstawowych błędów. W tym artykule chciałem się skupić na błędach mniej oczywistych, decyzjach, które w momencie podejmowania wydają się
rozsądne lub też zupełnie niegroźne, a które prowadzą do nieoczekiwanych rezultatów. Całość ujęta jest w ramy siedmiu grzechów głównych choć jak się przekonacie błędów
(podobnie jak grzechów) jest znacznie więcej.
1. Obżarstwo
Już papież Grzegorz I wyszczególnił 5 dróg, które wiodą do popełnienia grzechu obżarstwa... Ja podążę tym samym tropem.
a) Praepropare – testowanie zbyt wczesne. Wyobraźmy sobie system, którego rolą jest wysyłanie raportów w oparciu o wiadomości wejściowe. Raport zawiera w sobie identyfikator
wiadomości wejściowej, która jest jego katalizatorem. Operacja wysyłania raportów jest oczywiście asynchroniczna względem wykonania testu, toteż musimy poczekać na
odpowiedź. Test możemy skonstruować zatem na dwa sposoby:
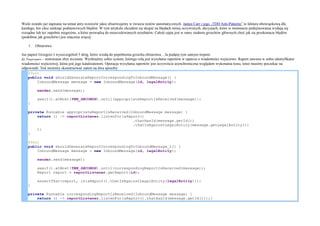
@Test
public void shouldGenerateReportCorrespondingToInboundMessage() {
InboundMessage message = new InboundMessage(id, legalEntity);
sender.send(message);
await().atMost(TEN_SECONDS).until(appropriateReportIsReceived(message));
}
private Runnable appropriateReportIsReceived(InboundMessage message) {
return () -> reportListener.listenFor(aReport()
.thatHasId(message.getId())
.thatIsAgainstLegalEntity(message.getLegalEntity())
);
}
@Test
public void shouldGenerateReportCorrespondingToInboundMessage_2() {
InboundMessage message = new InboundMessage(id, legalEntity);
sender.send(message);
await().atMost(TEN_SECONDS).until(correspondingReportIsReceived(message));
Report report = reportListener.getReport(id);
assertThat(report, is(aReport().thatIsAgainstLegalEntity(legalEntity)));
}
private Runnable correspondingReportIsReceived(InboundMessage message) {
return () -> reportListener.listenFor(aReport().thatHasId(message.getId()));}
2. Pierwsze podejście jest nieco bardziej czytelne aniżeli podejście drugie, zatem zadajmy sobie pytanie czy jest powód dla którego poświęcilibyśmy czytelność testu. Jednym z
głównych powodów dla których inwestujemy w automatyzację testów jest szybkość z jaką uzyskujemy informację zwrotną. Rozważmy raport wygenerowany dla danej wiadomości
wejściowej w sytuacji gdy posiada on złe legalEntity:
I) w podejściu pierwszym o tym fakcie dowiemy się dopiero po upływie zadeklarowanego czasu oczekiwania (w naszym przypadku 10s). Dodatkowo informacja o błędzie
będzie bardzo ogólna, dowiemy się jedynie iż raport o zadanym id oraz legalEntity nie pojawił się w oczekiwanym czasie – zwróćmy uwagę na to, iż jest to informacja nie
tylko zbyt ogólna ale co gorsze wprowadzająca w błąd naszą intuicję.
II) W podejściu drugim o błędzie dowiemy się zaraz po otrzymaniu raportu i będzie on bardzo dokładnie zidentyfikowany
Dodatkowo czytelność drugiego rozwiązania możemy nieco poprawić enkapsulując oczekiwanie na raport w klasie ReportListener.
b) Laute – testowanie zbyt drogie. Ogromna bolączka zwinnych testów, choroba którą zwykliśmy diagnozować dopiero, gdy jest już w bardzo zaawansowanym stadium. Dobrą
regułą, która pozwoli nam szybko poczuć iż choroba się właśnie zaczęła, lecz również pozwoli nam wyciągnąć maksimum korzyści z inwestycji w testy automatyczne, jest
uruchamianie kompletnego zbioru testów po każdej zmianie kodu źródłowego. Musimy sobie zdawać sprawę z tego iż często optymalizacja szybkości wykonania testu może
pociągać za sobą zmianę kodu produkcyjnego.
I) Pierwszą, najważniejszą regułą optymalizacji kosztów testowania to umiejscowienie testu na odpowiednim poziomie automatycznej piramidy testów, przy czym złota reguła
piramidy mówi: im niżej tym taniej. Oczywistością jest, że nie każdą funkcjonalność będziemy w stanie przetestować na poziomie testów jednostkowych.
II) Wyobraźmy sobie iż nasza aplikacja wykonuje jakąś czynność periodycznie. Zaimplementowaliśmy scheduler który odpala się zgodnie z cron'owym harmonogramem. Aby
sensownie integracyjnie przetestować taką funkcjonalność możemy zbudować część kontekstu dookoła klasy wyzwalanej przez scheduler (bez samej funkcjonalności
automatycznego odpalania) i uruchomić jej odpowiednią metodę publiczną. Co możemy jednak zrobić gdy chcemy przetestować integrację tej funkcjonalności z
pozostałymi modułami naszego systemu? Zmienić kod produkcyjny w dwojaki sposób:
1. dodać interfejs (jmx, rest, rmi, etc.) pozwalający na uruchomienie owej funkcjonalności w trybie „na żądanie”
2. dodać możliwość wyłączenia scheduler'ów.
III) Wyobraźmy sobie iż nasz system wysyła raporty dla określonych wiadomości wejściowych, acz są też takie wiadomości dla których nasz system nie wysyła żadnych
raportów... jak automatycznie przetestować fakt, iż raport nie został wysłany? Najprostszy, brutalny sposób to oczywiście zaimplementować timeout w naszym teście, przez
co domyślnie stwierdzamy „jeśli nie zdarzyło się do tej pory to znaczy, że się już nie zdarzy”. Taki test szkodzi całemu zbiorowi testów w dwojaki sposób:
1. znacząco wydłuża czas trwania testów (za każdym razem musimy czekać cały timeout)
2. potencjalnie wprowadza „migotanie testów” (test czasem przejdzie, czasem nie). Wyobraźmy sobie prostą sytuację gdy nasz serwer ciągłej integracji jest bardzo
obciążony i nagle nasz system zaczyna zwalniać, przez co dla zadanej wiadomości wejściowej system wyśle błędnie raport ale zazwyczaj dopiero po timeout'cie i tylko
czasem uda mu się wysłać go szybciej. W ten sposób ludzie przyzwyczają się, że jest jeden test który „migocze” więc.... trzeba go puścić jeszcze raz bo przecież
zmiany z czerwonym testem nikt nam nie pozwoli włączyć do master'a/trunk'a.
Odpowiedzią na przedstawiony problem jest kolejna złota reguła testowania automatycznego: nie można udowodnić/przetestować że coś się nie stało (musielibyśmy
czekać nieskończenie długo.... a to trochę za długo). Jedynym sensownym sposobem na wybrnięcie z tego impasu jest przetestować, że coś się stało ;-). To może wymagać
sporych zmian w samym systemie (celem jest poprawienie testowalności). Jakkolwiek skomplikowane technicznie by to nie było, koncepcyjnie sprowadza się do bardzo
prostej rzeczy, test musi wiedzieć iż procesowanie danej wiadomości się skończyło i jest jakiś marker na, który musi czekać.
3. c) Nimis /Ardenter – testowanie w zbyt dużej ilości , zbyt dokładne. Intuicyjnie może się nam wydawać, że im więcej przetestujemy tym lepiej... nic bardziej mylnego. Zrobimy sobie
potencjalnie krzywdę na trzy sposoby:
I) tracimy czytelność kontraktu jaki nasza klasa zawiera ze swoimi kolaboratorami
II) tracimy czas na utrzymywanie większej ilości kodu
III) wydłużamy sobie czas trwania naszego zbioru testów. Jeśli dopuścimy się takiej nierozwagi na poziomie jednostkowym to owe wydłużenie będzie zazwyczaj marginalne,
lecz wystarczy wejść po stopniach piramidy testów nieco wyżej by czas oczekiwania na testy znacząco się wydłużył.
Co to zatem znaczy „zbyt dużo” i jak się przed tym uchronić? Stare, dobre praktyki wypracowane w czasach intensywnych testów manualnych przychodzą nam z pomocą: klasy
równoważności, wartości brzegowe, pokrycie diagramu przepływów, tabele decyzyjne. Opis tych metod wykracza poza ramy tego artykułu ale też jest dużo dokumentacji na ten
temat w sieci. Chciałbym się skupić na czymś czego w sieci jeszcze nie znalazłem otóż na sposobie poradzenia sobie z testami automatycznymi skomplikowanych warunków
logicznych. Z jednej strony nic prostszego jak użyć testów parametrycznych i przetestować cały zbiór kombinacji... z drugiej strony będąc tak dokładni całkowicie zaciemniamy
obraz odpowiedzialności naszej klasy. Musimy znaleźć zatem jakiś sensowny kompromis. Rozważmy następującą w sumie dość prostą implementację która bazuje decyzję na
podstawie 4 parametrów:
public boolean isEligible(InboundMessage message) {
LegalEntity legalEntity = message.getLegalEntity();
Counterparty counterparty = message.getCounterparty();
PartiesRelation partiesRelation = relationService.determineRelation(legalEntity, counterparty);
Product product = message.getProduct();
return legalEntity.isEligible() &&
counterparty.isEligible() &&
partiesRelationship.isEligible() &&
product.isEligible(
}
By dokładnie przetestować powyższy kod musimy pokryć 16 (24
) przypadków:
public Object[] eligibleParameters() {
return $(
$(eligibleLegalEntity, eligibleCounterparty, eligibleProduct, eligibleRelationship, true),
$(eligibleLegalEntity, eligibleCounterparty, eligibleProduct, notEligibleRelationship, false),
$(eligibleLegalEntity, eligibleCounterparty, notEligibleProduct, eligibleRelationship, false),
$(eligibleLegalEntity, eligibleCounterparty, notEligibleProduct, notEligibleRelationship, false),
$(eligibleLegalEntity, notEligibleCounterparty, eligibleProduct, eligibleRelationship, false),
$(eligibleLegalEntity, notEligibleCounterparty, eligibleProduct, notEligibleRelationship, false),
$(eligibleLegalEntity, notEligibleCounterparty, notEligibleProduct, eligibleRelationship, false),
$(eligibleLegalEntity, notEligibleCounterparty, notEligibleProduct, notEligibleRelationship, false),
$(notEligibleLegalEntity, eligibleCounterparty, eligibleProduct, eligibleRelationship, false),
$(notEligibleLegalEntity, eligibleCounterparty, eligibleProduct, notEligibleRelationship, false),
4. $(notEligibleLegalEntity, eligibleCounterparty, notEligibleProduct, eligibleRelationship, false),
$(notEligibleLegalEntity, eligibleCounterparty, notEligibleProduct, notEligibleRelationship, false),
$(notEligibleLegalEntity, notEligibleCounterparty, eligibleProduct, eligibleRelationship, false),
$(notEligibleLegalEntity, notEligibleCounterparty, eligibleProduct, notEligibleRelationship, false),
$(notEligibleLegalEntity, notEligibleCounterparty, notEligibleProduct, eligibleRelationship, false),
$(notEligibleLegalEntity, notEligibleCounterparty, notEligibleProduct, notEligibleRelationship, false)
);
}
@Test
@Parameters(method = "eligibleParameters")
public void eligibilityShouldBeAsExpected(LegalEntity entity, Counterparty counterparty,
Product product, PartiesRelationship partiesRelationship,
boolean expectedResult) {
(…)
}
Bardzo trudno z powyższego testu odczytać jaki „kontrakt” zawiera klasa testowana ze swoimi kolaboratorami, choć jednocześnie możemy się bronić tym iż jest to bardzo dokładny
kontrakt, w którym wszystko zostało zawarte. Tchnijmy nieco pragmatyzmu do powyższego podejścia:
@Test
public void shouldBeEligibleWhenAllCompoundsAreEligible() { (…) }
private Object[] atLestOneCompoundNotEligible() {
return $(
$(eligibleLegalEntity, eligibleCounterparty, eligibleProduct, notEligibleRelationship),
$(eligibleLegalEntity, eligibleCounterparty, notEligibleProduct, eligibleRelationship),
$(eligibleLegalEntity, notEligibleCounterparty, eligibleProduct, eligibleRelationship),
$(notEligibleLegalEntity, eligibleCounterparty, eligibleProduct, eligibleRelationship)
);
}
@Test
@Parameters(method = "atLestOneCompoundNotEligible")
public void shouldNotBeEligibleWhenAtLeastOneCompoundIsNotEligible(
LegalEntity legalEntity, Counterparty counterparty,
Product product, PartiesRelationship partiesRelationship) { (…) }
W ten sposób zamieniliśmy 16 testów na 5. Zwróćmy ponadto uwagę na to, iż przyrost przypadków testowych w funkcji ilości parametrów wejściowych w pierwszym podejściu jest
5. geometryczny (z każdym nowym parametrem podwajamy ilość przypadków testowych) natomiast w podejściu drugim jest liniowy (z każdym nowym parametrem dodajemy jeden
nowy test). Poniżej zestawienie liczby przypadków testowych odpowiednio w podejściu „dokładnym” oraz „pragmatycznym” dla określonej liczby parametrów wejściowych:
Liczba parametrów
wejściowych
Liczba przypadków testowych
(podejście dokładne)
Liczba przypadków testowych
(podejście pragmatyczne)
1 2 2
2 4 3
3 8 4
4 16 5
5 32 6
10 1024 11
Zmiana charakterystyki z geometrycznej na liniową wiąże się oczywiście z ceną – tracimy dokładność. Zadajmy sobie jednak pytanie czy jest to autentyczny problem. Poniżej trzy
najważniejsze rzeczy, jakich oczekujemy od testów automatycznych:
1. służą jako testy regresji, mają być naszą siatką bezpieczeństwa przy refaktoryzowaniu kodu
2. dają szybką informację zwrotną
3. powinny jasno oddawać odpowiedzialności klasy, przez co ułatwiać refaktoryzowanie kodu
Ważną rzeczą jest uświadomić sobie, iż w sytuacji gdy mamy dość wysokie pokrycie kodu/wymagań testami, często błędy, które wydają się błędami regresji tak naprawdę są
błędami związanymi ze złym zrozumieniem nowych wymagań. Inżynier implementując nowe wymaganie zmienia również test – co jest normalną praktyką. Przed tego typu błędem
nie uchroni nas ani podejście „dokładne” ani „pragmatyczne”. Pozostają zatem zmiany zrobione przypadkowo, zobaczmy zatem jaką zmianę trzeba wprowadzić aby rozwiązanie
„pragmatyczne” okazało się zbyt liberalne:
Warunek logiczny Rezultat testów
pragmatycznych
Rezultat testów
dokładnych
a && b && c && d && e Ok Ok
A & b && c && d && e Błąd niewykryty Błąd niewykryty
A && b && c && d && e && f Błąd niewykryty Błąd niewykryty
A && c && d && e Błąd wykryty Błąd wykryty
A | b && c && d && e Błąd wykryty Błąd wykryty
A && b && c && d && e || (a && !b) Bład niewykryty Błąd wykryty
Powyższą tabelkę podzieliłem na trzy grupy (pierwszy rząd służy tylko za punkt odniesienia, który pokazuje oryginalny warunek logiczny).
Pierwsza (żółta) część tyczy się błędów, które nie zostaną wykryte w żadnym z podejść:
1. zmiana operatora AND z logicznego na bitowy. W przypadku wartości bool'owskich wynik jest taki sam więc trudno tu mówić o autentycznym błędzie – jest to natomiast
6. na pewno mylące, narzędzia do statycznej analizy kodu powinny to wychwycić.
2. Dodanie nowego warunku (f) – z testowego punku widzenia jest to dodanie nowej funkcjonalności i powinno wiązać się z dodaniem/zmianą testu tak by tą nową
funkcjonalność pokrywał. Tak jak już wcześniej wspominałem testy automatyczne są testami regresji więc nie jest możliwe aby znalazły tego typu błąd, jeśli tylko zmiana
jest kompatybilna wstecz.
Druga część (zielona) to faktycznie przypadkowe błędy, które możemy zrobić szybko edytując kod (usunięcie jednego z parametrów, zmiana przypadkowa operatora AND na OR,
etc.) - tego typu błędy są wykrywane przez oba testy.
Trzecia część (czerwono-zielona) faktycznie obrazuje jak skomplikowana (wybrałem możliwie najprostszą) musi być (przypadkowa) zmiana w warunku logicznym aby test
pragmatyczny zawiódł. Teraz musimy sobie tylko odpowiedzieć na pytanie jakie jest prawdopodobieństwo wprowadzenia takiej zmiany przypadkowo... i czy chcemy ponosić cenę
całkowitego pokrycia aby się przed nią ustrzec.
d) Studiose – testowanie zbyt wystawne. Dzieje się to w sytuacji, gdy do przetestowania naszej klasy wymagamy szeregu mock'ów, stub'ów etc. Najprostsze rozwiązanie problemu
zbyt dużej liczby mock'ów jest nie stosować ich w ogóle. Podejście funktorowe przychodzi nam z odsieczą. Jego implementacja wszak będzie wymagać refaktoryzowania naszego
kodu. Wykorzystajmy ponownie nasz algorytm do wyznaczania eligibility, wygląda on tak:
Pozostaje pytanie czy potrafimy dokonać takich zmian aby mockowanie nie było potrzebne w powyższej sytuacji. W swojej aktualnej formie EligibilityService łamie zasadę
pojedynczej odpowiedzialności. Wie skąd dostać potrzebne mu informacje (RelationshipService) oraz wie jak wyznaczyć eligibility na podstawie posiadanych informacji. Proponuję
rozdzielić te dwie odpowiedzialności, na część serwisową oraz algorytmiczną. Serwis zbierze dane (bardzo prosta logika, w zasadzie to jej brak – nie bardzo jest co testować) oraz
Algorytm (tu tkwi serce, które musimy należycie przetestować) który te dane przetworzy i wyda odpowiedni werdykt, a serwis następnie zwróci ten werdykt na zewnątrz.
7. Kolejnym, bardzo prostym sposobem ustrzeżenia się mocków jest wprowadzenie tzw. biblioteki obiektów testowych – obiektów biznesowych będących w odpowiednich stanach.
Jest wiele różnych typów zamienników, które stosujemy w testach acz ich dokładny opis wykracza poza ramy tego artykułu (zainteresowanego czytelnika odsyłam do sieci: Mocks
aren't Stubs by Martin Fowler, Mocks, Fakes, Stubs and Dummies from xUnitPatterns).
Tomasz z akwinu dodał jeszcze jedną ścieżkę do zatracenia w kontekście grzechu obżarstwa.
e) Forente – testowanie niepochamowane, zdziczałe. Dwa punkty które chciałbym zaznaczyć na wstępie tego krótkiego punktu:
– Testy powinny opisywać biznesowe zachowanie klasy tak bardzo jak to tylko możliwe i sprawdzać z możliwie biznesowego punktu widzenia czy zachowanie klasy jest
poprawne
– Testy nie powinny być splątane z kodem (coupled) ponieważ dramatycznie utrudnia to refaktoryzowanie, które jest nieodłącznym aspektem utrzymywania kodu w
czystości.
Łamiemy obie powyższe reguły wykorzystując pewne funkcjonalności framework'ów do mockowania jak np. sprawdzanie kolejności wywołania poszczególnych metod,
sprawdzanie czy dana metoda została wywołana, sprawdzana czy parametry wywołania były odpowiednie. Zwróćmy uwagę, że ani taki test nie odpowiada na pytanie o
odpowiedzialności biznesowe klasy ani nie pomoże w przypadku refaktoringu bo i tak będzie musiał być zmieniony. Zatem po co?
2. Chciwość
Chciwość w świecie testów zazwyczaj manifestuje się w testach systemowych, które pożądają dostępu do zasobów, do których dostępu mieć nie powinny. Zgodnie z ideą BDD test
systemowy, poza tym, że sprawdza czy nasz system zachowuje się w pożądany sposób jest również swego rodzaju biznesową dokumentacją – aby to stwierdzenie było prawdziwe to
taki test musi wykorzystywać tylko interfejsy, które są rozumiane przez ludzi biznesu. Jeśli nagle, by sprawdzić czy system po wykonaniu testu jest w odpowiednim stanie, test sięga
do bazy danych – to jest dokładnie chciwość o której mówię. Jej przyczyną jest to, iż być może system jest nietestowalny i jest to jedyny sposób aby go przetestować ale z drugiej
strony trudno wymagać od użytkowników (którzy z definicji akceptują każdą historyjkę, którą dostarczamy) aby w pełni zrozumieli test akceptacyjny który w połowie wykonania
sięga do bazy danych lub też ów test kończy się stwierdzeniem: „wszystko działa poprawnie, w tabelach users oraz reports są odpowiednie wpisy”....
8. 3. Lenistwo
Testy potrafią być leniwe w dwojaki sposób.
Po pierwsze same zostawiają po sobie bałagan, system w zabrudzonym stanie. Z czasem może się okazać, iż nowo dodany test który przechodzi w izolacji zawsze gdy puszczony na
serwerze ciągłej integracji zaczyna nam migać (czasem przechodzi, czasem nie). Okazuje się że określona kombinacja brudów pozostawiona przez poprzednie testy interferuje z tym
nowo dodanym. Jest to jeden z najtrudniej identyfikowalnych błędów ponieważ może on pojawiać się tylko czasem, w zależności od kolejności wywołania testów poprzedzających
nasz test (kolejności, na którą nie mamy wpływu, zwłaszcza gdy uruchamiamy testy wielowątkowo).
Druga manifestacja lenistwa jest jeszcze gorsza niż poprzednia – celowe wykorzystanie zanieczyszczeń zostawionych przez poprzedni test. Jeśli zdecydujemy się iść tą drogą
musimy sobie zdawać sprawę z tego, że zakładamy sobie na nogi łańcuchy komplikacji. Od tego momentu nie będziemy już w stanie jasno wywnioskować startowego stanu systemu
czytając jeden test, a być może co gorsze tworzymy efekt domina, jeśli jeden test się nie powiedzie, pociągnie za sobą inne testy, które z kolei pociągną kolejne – takie domino
znacząco utrudnia analizę. Kajdany zaczynają również dźwięczeć gdy przyjdzie nam zmienić funkcjonalność (a zatem również test) który „przygotowywał” stan dla jakiegoś innego
testu...
4. Zazdrość
Zazdrość manifestuje się zazwyczaj w testach wyższego poziomu. Generalnie sprowadza się to do zazdroszczenia innym testom, że one mogą coś sprawdzać. Wyobraźmy sobie test
systemowy którego celem jest sprawdzenie czy dla określonej wiadomości wejściowej został wygenerowany raport. W takim teście poza sprawdzeniem czy faktycznie raport został
wygenerowany sprawdzamy jeszcze dokładnie jego zawartość.... czy to dobrze? Dlaczego miałoby to być złe? Pierwszym powodem jest to, że zaciemniamy obraz
odpowiedzialności tego konkretnego testu (problem możemy obejść ukrywając to co faktycznie jest sprawdzane na którymś z niższych poziomów abstrakcji naszego framework'u
testowego). Tego rodzaju sprawdzenia zachęcają do testowania wariacji prowadzących do wygenerowania raportu z innymi wartościami na poziomie testów systemowych – co już
jest poważnym naruszeniem, ponieważ znacząco wydłuży czas trwania testów systemowych.
5. Kenodoxia
W czwartym wieku naszej ery grecki mnich Evagrius Ponticus zdefiniował listę „8 złych myśli”, które to następnie niespełna dwa wieki później papierz Grzegorz I przekuł w „7
śmiertelnych grzechów”. Na liście „siedmiu” Kenodoxia (czy też pycha) nie widnieje (widnieje jedynie duma, choć co ciekawe w katolickim katechiźmie mamy odwortnie, jest
pycha nie ma dumy). Niemniej jednak ze względu na to, iż objawiła się ona ostatnio w testach napisanych przez mój zespół postanowiłem nie pomijać jej w tym artykule. Jedyne
miejsce gdzie test może chwalić się swoimi poczynaniami to logi testowe. Zarówno logi testowe jaki raport z wykonania testów powinny być łatwe do odczytu i analizy. W sytuacji
gdy tak nie jest musimy popracować nad poziomem logowania.
Dwa ostatnie punkty nie tyczą się testów lecz raczej inżyniera, który te testy pisze.
6. Pride
Dobrze jest znać różne języki programowania ale to nie znaczy, że należy ich wszystkich używać w swoich testach czy też generalnie w projekcie. W moim projekcie używamy
trzech języków (java, groovy, xquery, brakuje tylko scali i clojure – acz i takie zapędy były ;-)) i bardzo staramy się aby były jasne granice używania każdego z nich. W testach udało
nam się tą liczbę sprowadzić do dwóch (java, groovy). Każdy język to nowe praktyki kodowania, nowa definicja statycznej analizy kodu, nowe rodzaje błędów do popełnienia.
Bardzo się zastanówcie zanim zrobicie sobie krzywdę wprowadzając drugi język do waszego projektu – wypiszcie sobie konkretne zyski jakie planujecie uzyskać, bo cena jest
wysoka.
7. Wrath/Desire
Zdarzają się chwile, w których już po prostu chcemy żeby ktoś wreszcie z'merge'ował nasze zmiany bo przebyliśmy już dwukrotnie przez „re-basing hell”, a ktoś się czepia.... a to
pokrycia (że tylko 80%), a to nazewnictwa (że niejasne), a to długości metod (że za długie i nadające się do zmiany)......... I to „coś” zaczyna w nas rosnąć rozsadzając zdrowy
rozsądek pozwalając kiełkować sarkazmowi i ironii. W naszym środowisku bardzo dobrze działa parowanie się w takich wypadkach. Po prostu prosisz osobę która robi review, żeby
siadła i napisała ten kawałek z Tobą, robiąc re-review jednocześnie. Wymaga wyjścia spomiędzy krzewów sarkazmu i ironii ale popłaca, ostatecznie wszyscy siedzimy na tym
samym wózku i chcemy żeby ten wózek prowadził się jak najłatwiej i był przynajmniej niebrzydki ;-).