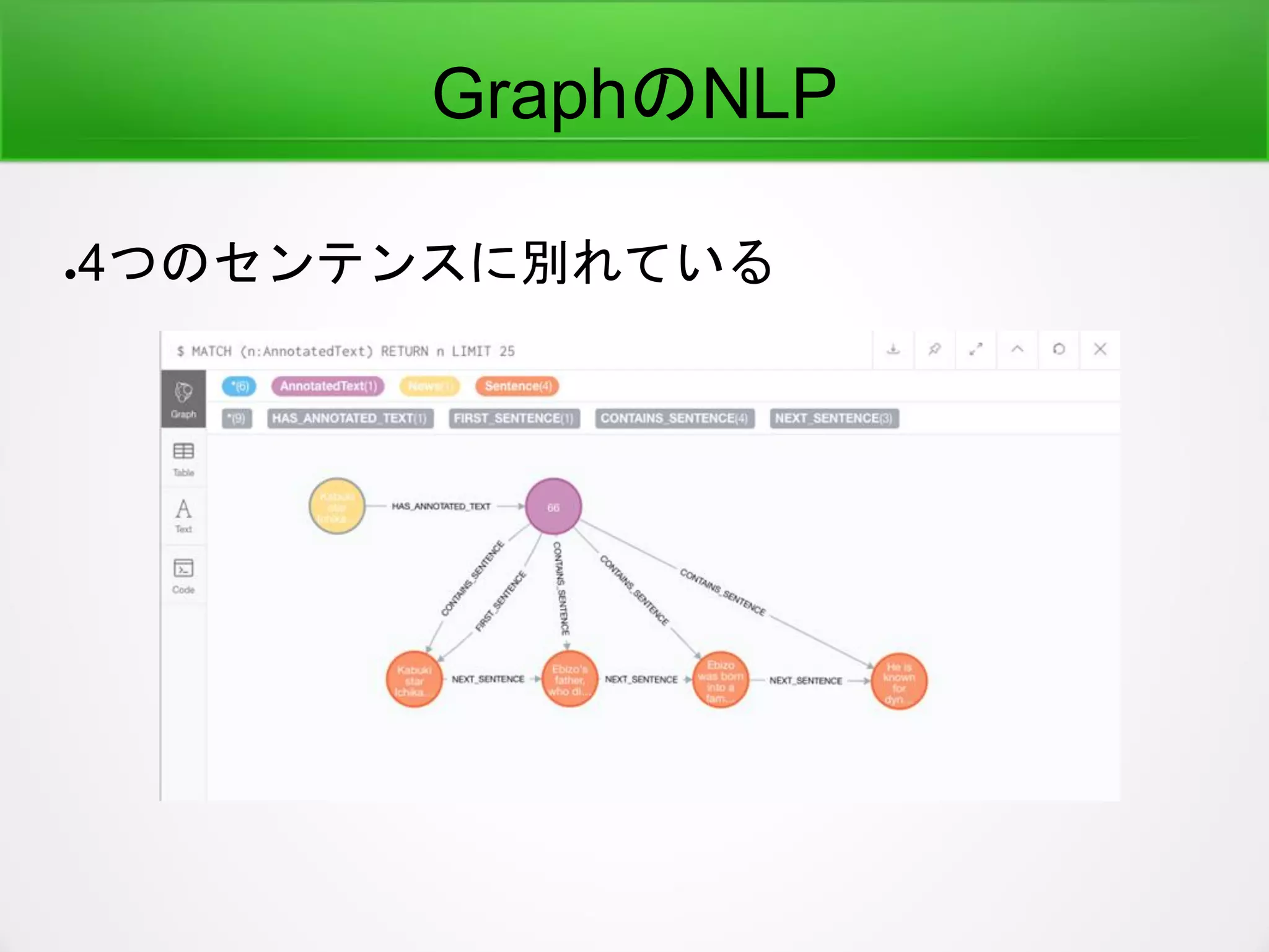
GraphのNLP
●GraphでNLP(自然言語処理)はどうするのか?
●テキストをノードに登録 (NHK WorldJapanのテ
キスト)
–CREATE (n:News)
SET n.text = "Kabuki star Ichikawa Ebizo says he
will assume his family's prestigious stage name of
Danjuro next year.Ebizo told reporters at the
Kabukiza theater in Tokyo on Monday that he will
become the 13th actor to use the name Ichikawa
Danjuro, beginning with a performance in May
next year.The stage name has been handed down
through generations since the 17th century.
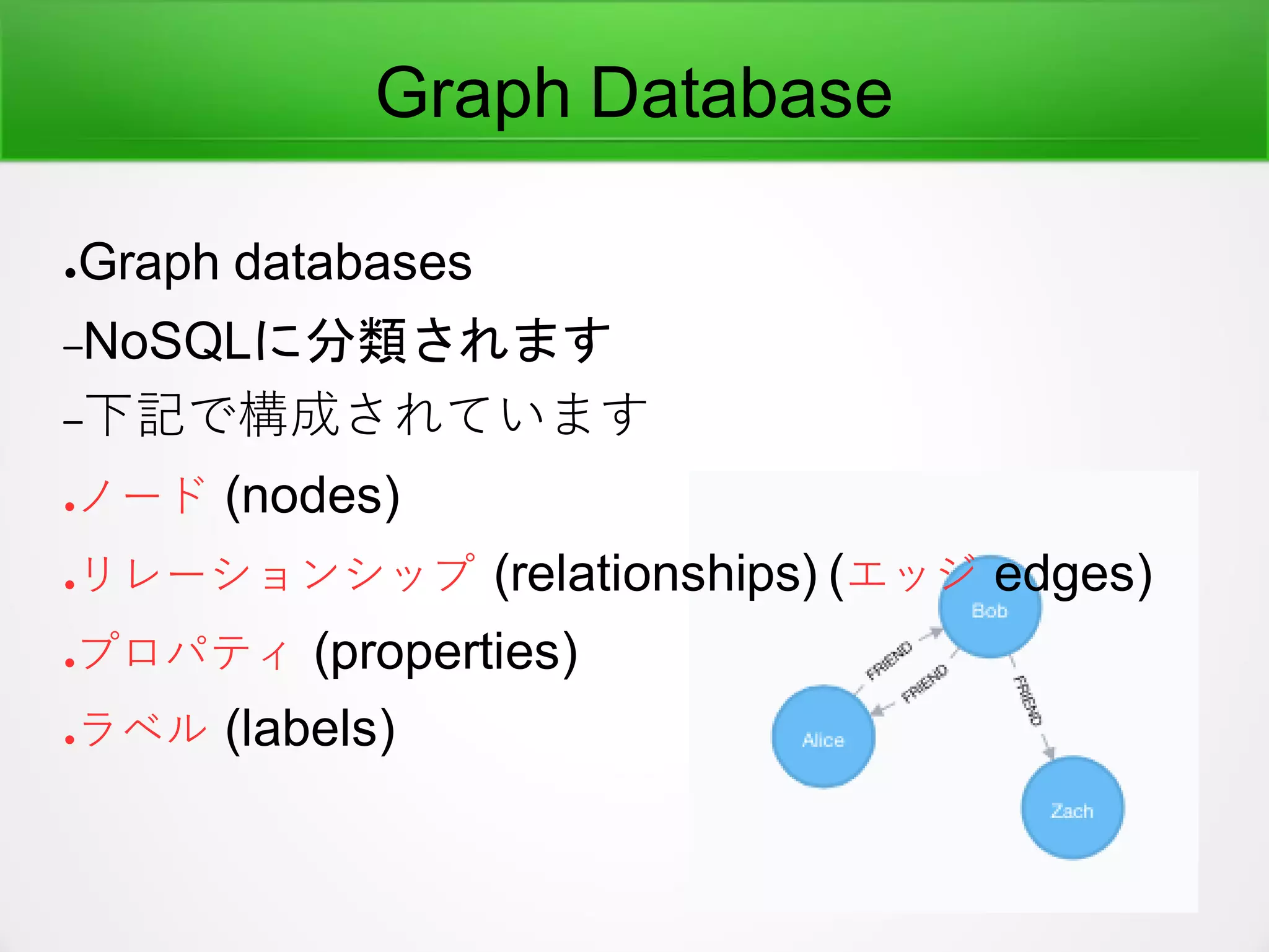
Graph Databaseにロード
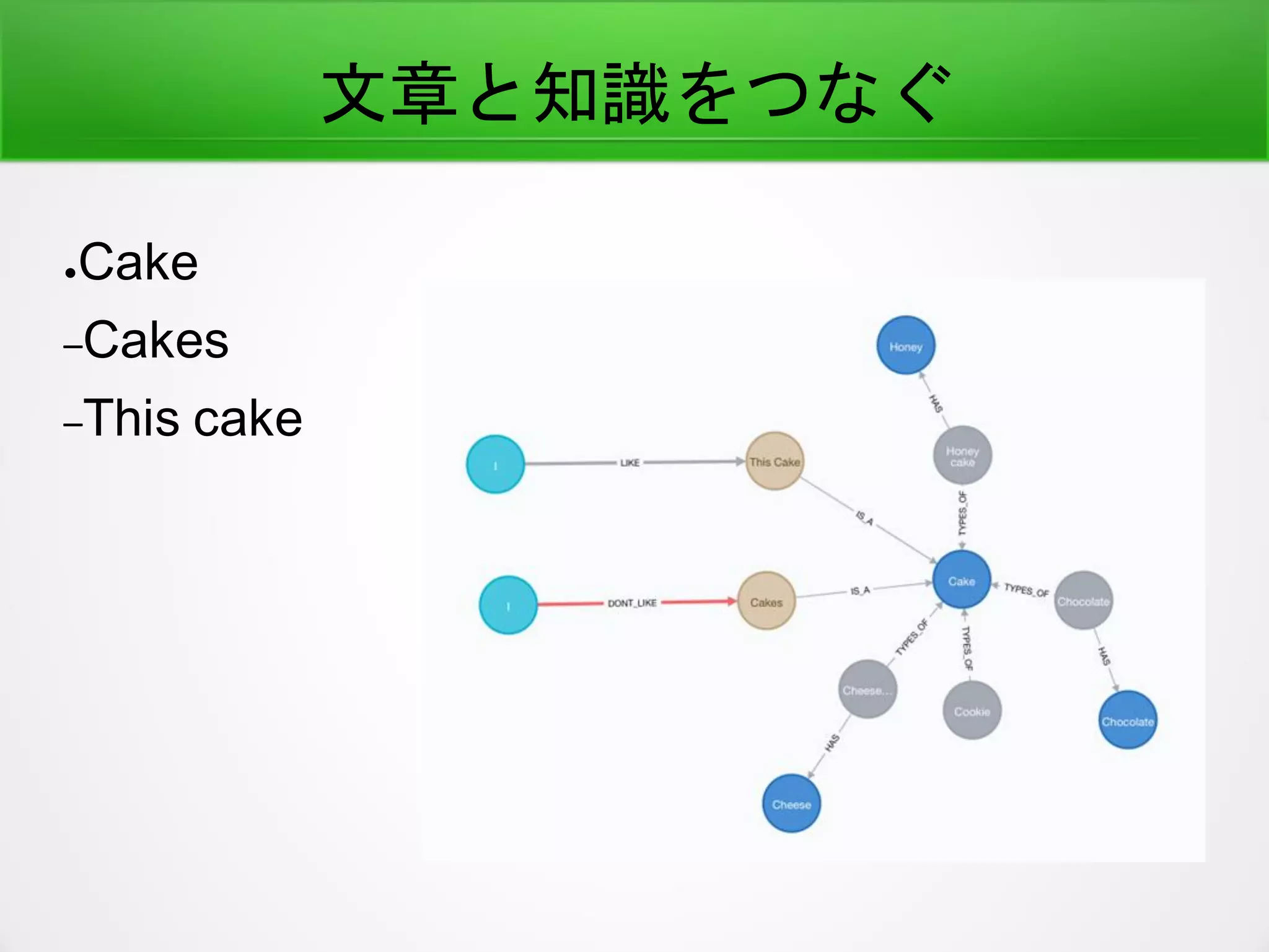
●こうつながっている
–English Word-- Japanese Word
–English Sentence -- Japanese Sentence
–English Sentence -- English Words
–Japanese Sentence -- Japanese Words
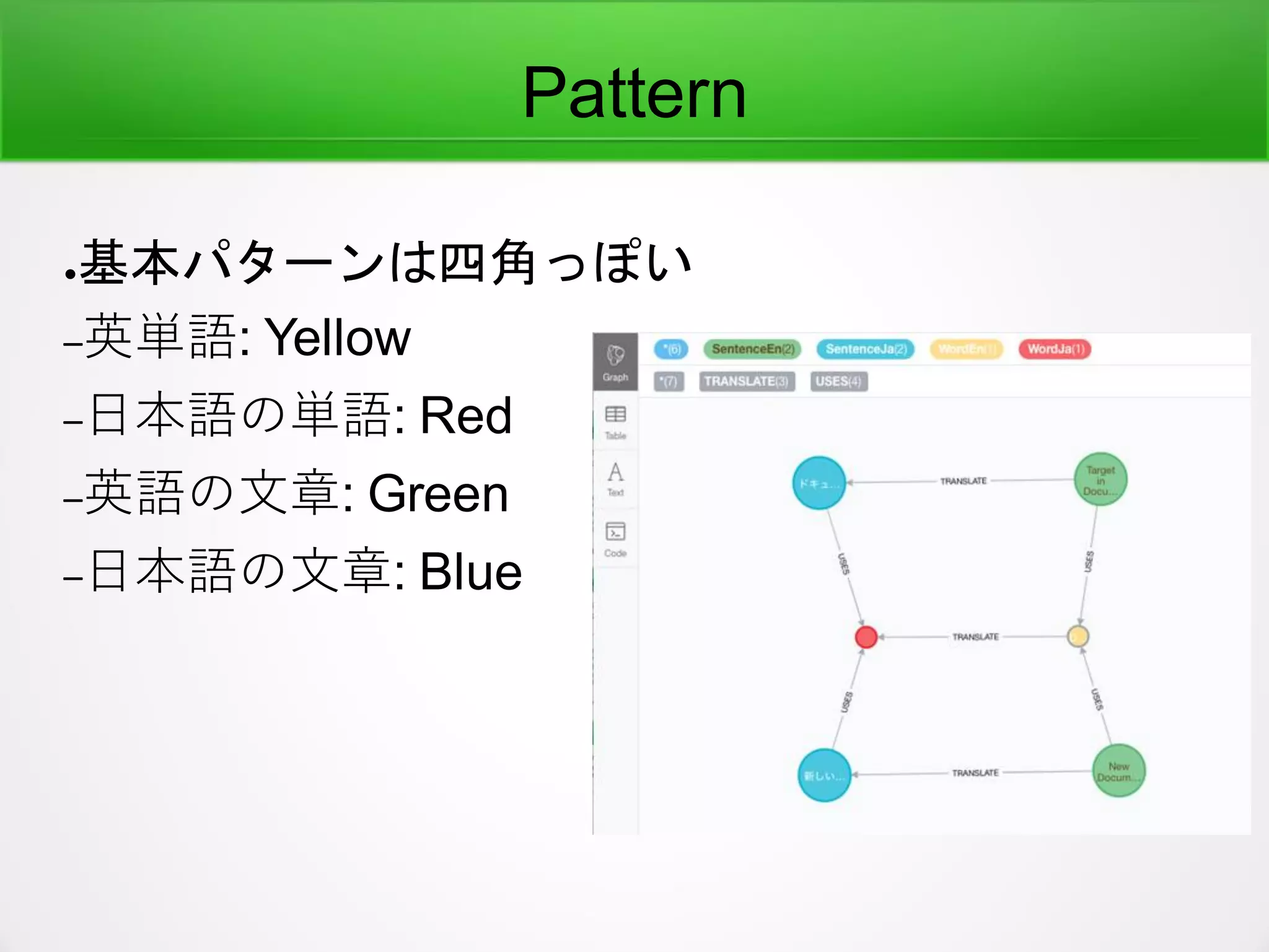
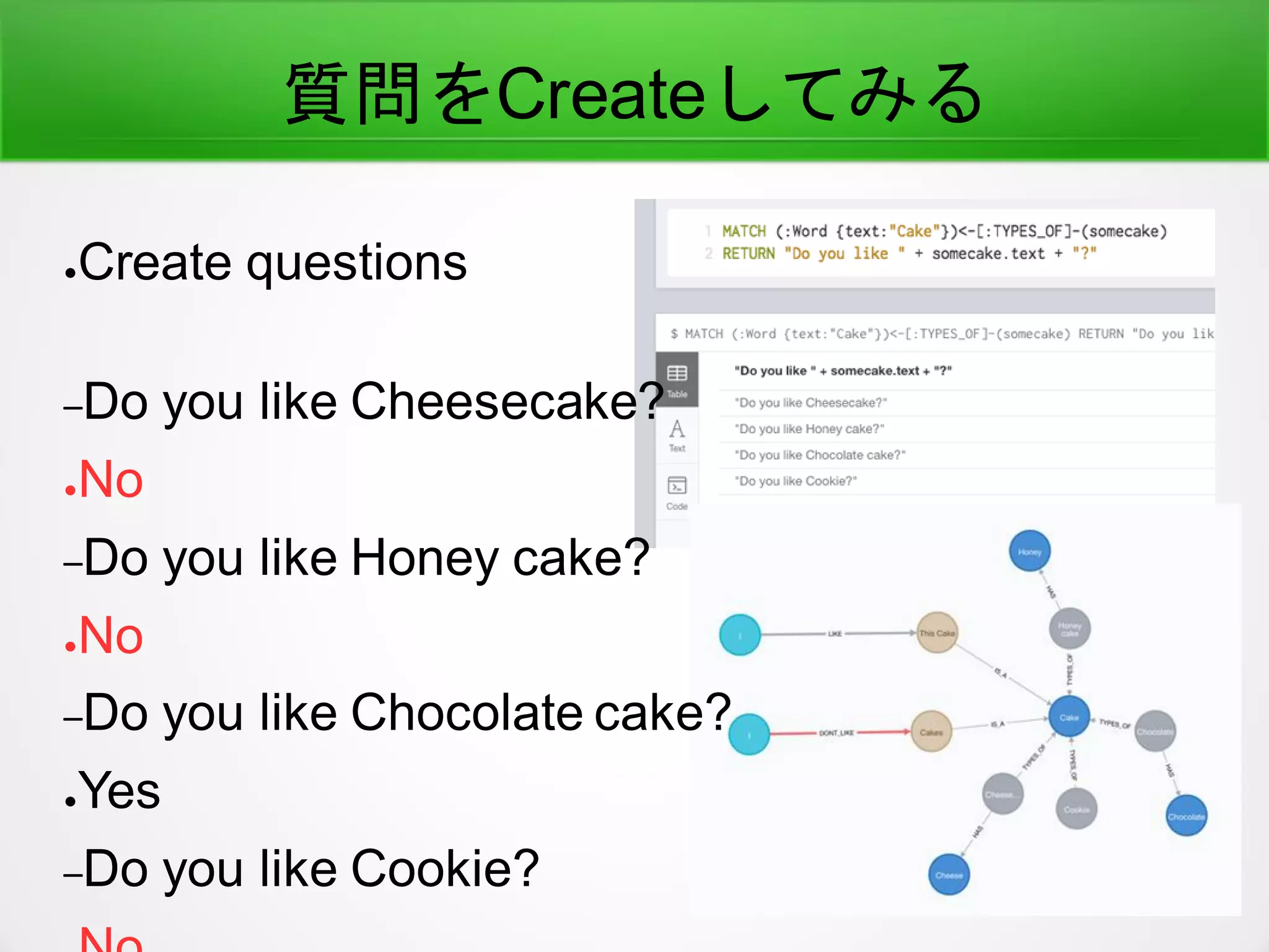
●Graphではどう実装されるか
–(Document)-[:TRANSLATE]->(ドキュメント)
–(Document background)-[:TRANSLATE]->(ドキュ
メントの背景)
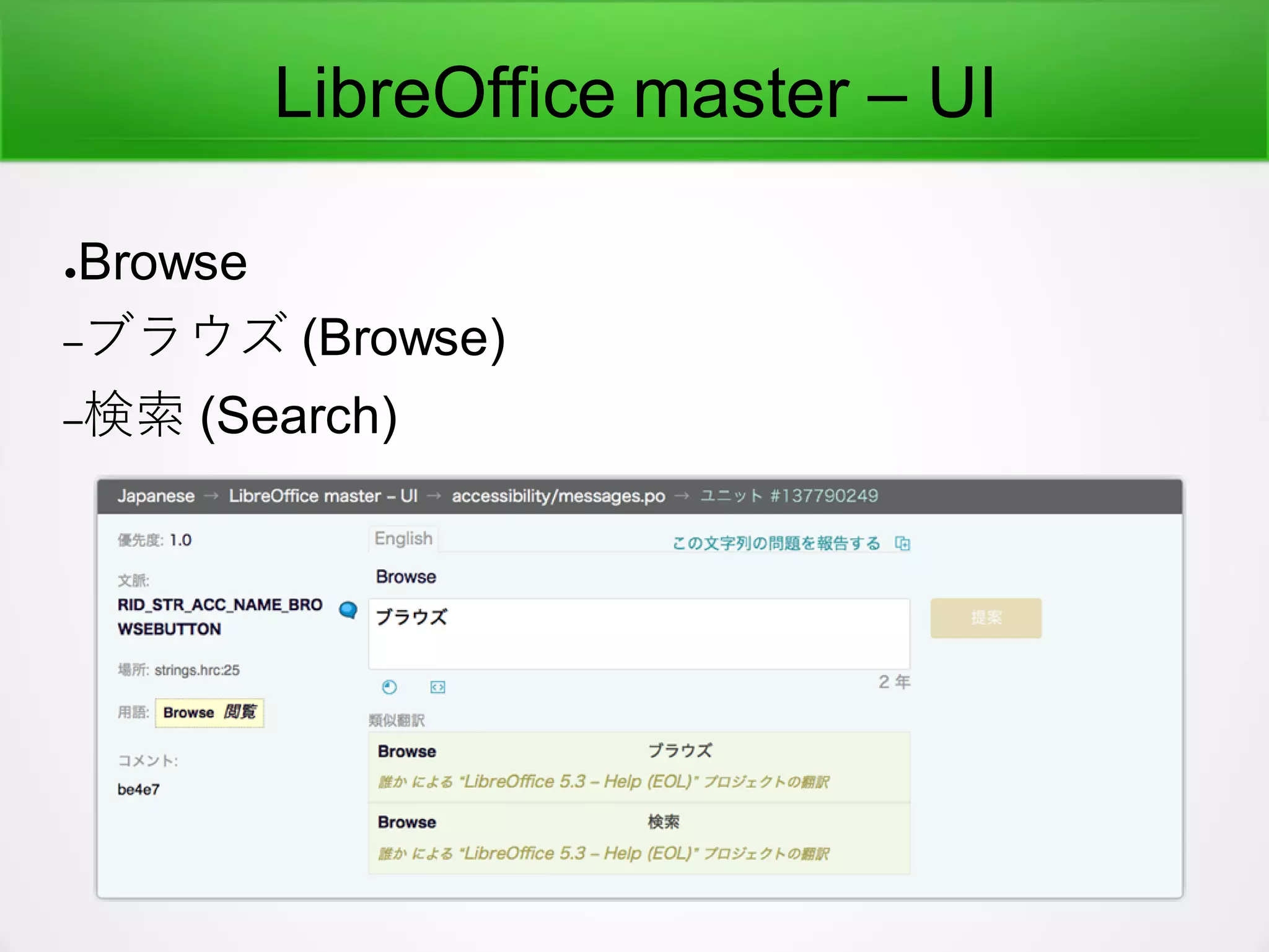
Document
●Japanese translation ofthe word (“Document”)
–3つの異なった翻訳が見つかった
●文書
–"Document copy has been created","文書のコピ
ーを作った時"
–"New Document","新規文書の開始時"
●ドキュメント
–"New Document","新しいドキュメント"
–"My Documents","マイドキュメント"
50.
make good translations.
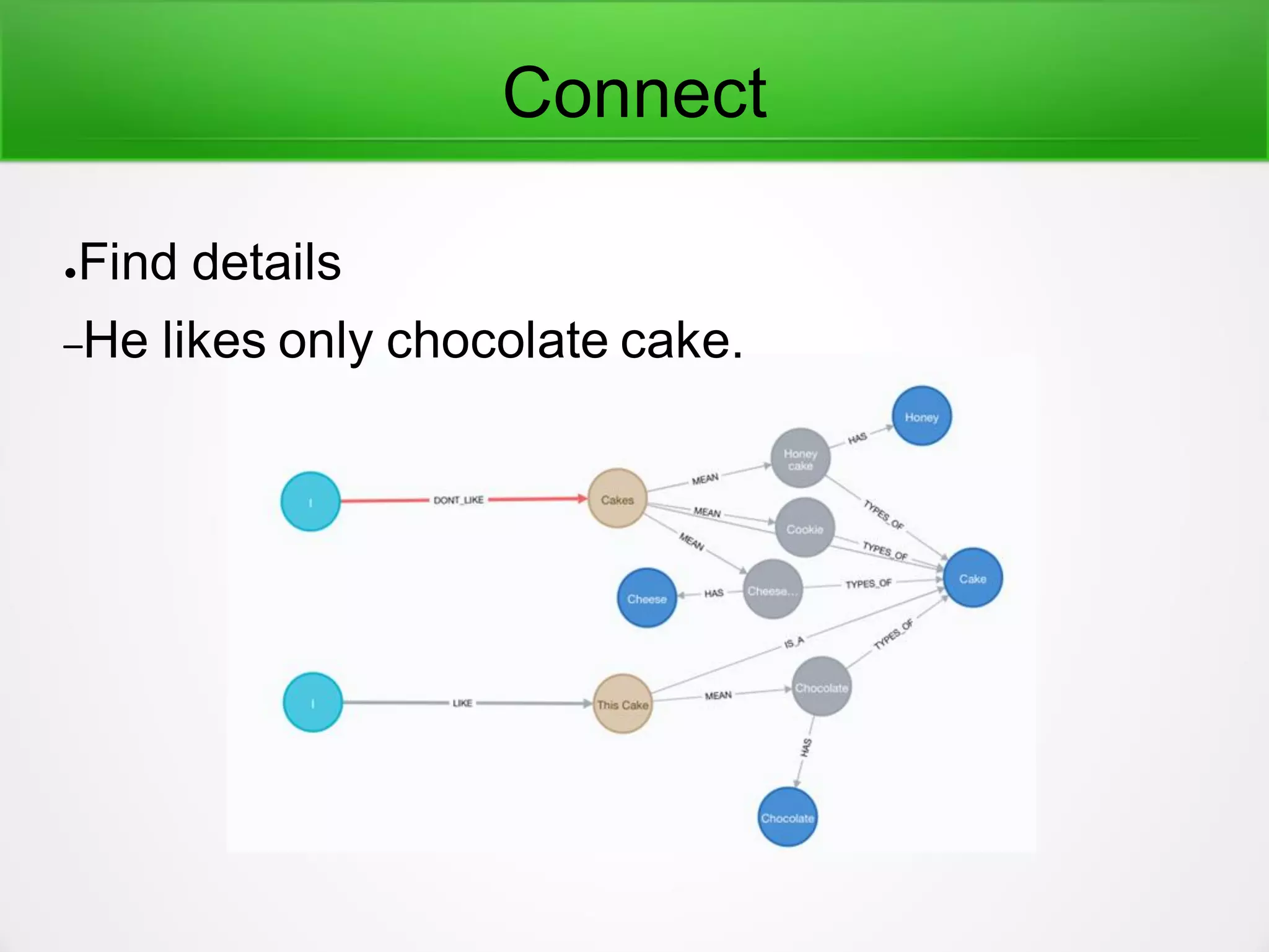
●Checksynonyms and make good translations.
–if you unify to ”文書”
●"新しいドキュメント"、"新しい文書"
●"マイドキュメント"、"マイ文書" (これは微妙)
–if you unify to ”ドキュメント”
●"文書のコピーを作った時"、"ドキュメントのコピーを作った時"
●"新規文書の開始時"、"新規ドキュメントの開始時"
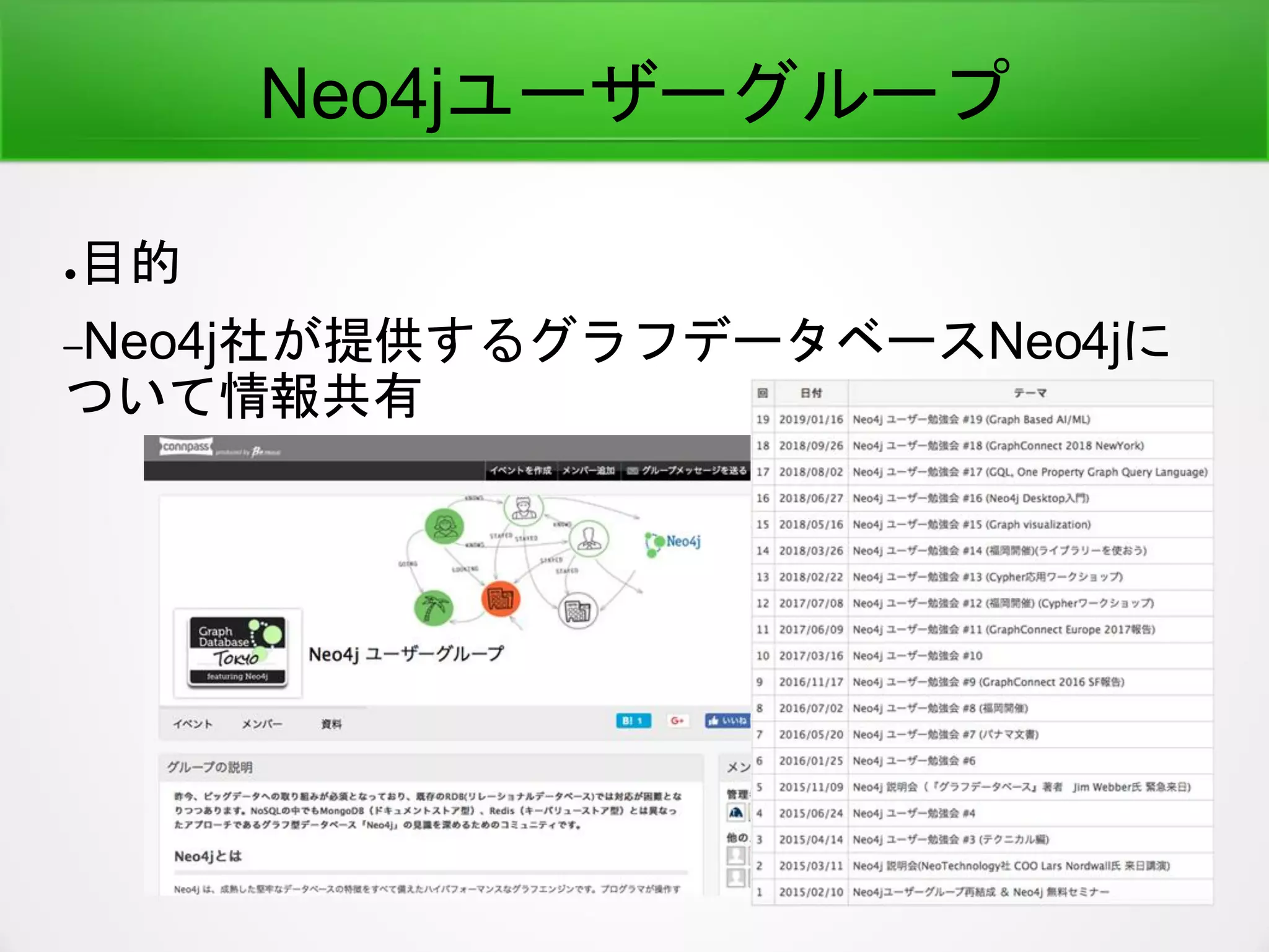
知識ベースとは
●ConceptNet (One ofknowledge base)
–ConceptNet is a freely-available semantic
network, designed to help computers understand
the meanings of words that people use.
–Relationships
●is a
●Is used for
●made of
●has a
●Similar to



































![Graph Databaseにロード
●こうつながっている
–English Word -- Japanese Word
–English Sentence -- Japanese Sentence
–English Sentence -- English Words
–Japanese Sentence -- Japanese Words
●Graphではどう実装されるか
–(Document)-[:TRANSLATE]->(ドキュメント)
–(Document background)-[:TRANSLATE]->(ドキュ
メントの背景)](https://image.slidesharecdn.com/20191019upday1d1dbts-191018225410/75/slide-43-2048.jpg)
























































![レガシーに埋もれたデータをリアルタイムでクラウドへ [ATTUNITY & インサイトテクノロジー IoT / Big Data フォーラム 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/attunityseminar20181206msnakagawa-181211014925-thumbnail.jpg?width=640&height=640&fit=bounds)
