Download as PDF, PPTX














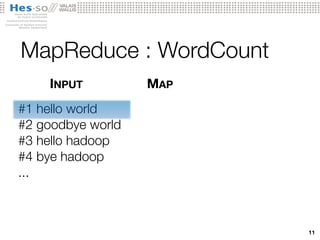

















































The document discusses the use of MapReduce for large-scale medical image analysis, highlighting the exponential growth of imaging data and the need for efficient processing solutions. It describes the implementation of Hadoop and demonstrates various applications including support vector machines and image indexing, showing significant improvements in computation speed and efficiency. The conclusions emphasize the effectiveness of MapReduce in diverse use cases and suggest future work involving cloud computing for enhanced scalability.





















































































