Downloaded 22 times








![Split
[k1, v1]
sort
by k1
Merge
[k1, [v1,v2,v3,...]]](https://image.slidesharecdn.com/zerovmvirtualization2-140910183657-phpapp01/85/MapReduce-on-Zero-VM-9-320.jpg)







![Thanks
Get this ppt from: http://goo.gl/6fJpbn
Credits:
[1] Prosunjit Biswas, UTSA
[2] Carina C. Zona, Rackspace
[3] Ryan Mckinney, Rackspace
References:
[1] zeroVM: http://www.zerovm.org
[2] apache hadoop: http://apache.hadoop.org
[3] Amazon EMR: http://aws.amazon.com/elasticmapreduce
[4] Map Reduce: http://en.wikipedia.org/wiki/MapReduce
[5] Native Client: A Sandbox for Portable, Untrusted x86 Native Code : http://static.googleusercontent.
com/media/research.google.com/en/us/pubs/archive/34913.pdf
More about ZeroVM
Website: www.zerovm.org
Github: https://github.
com/zerovm/
User Mailing List:
zerovm@googlegroups.com
IRC: #zerovm on Freenode](https://image.slidesharecdn.com/zerovmvirtualization2-140910183657-phpapp01/85/MapReduce-on-Zero-VM-22-320.jpg)

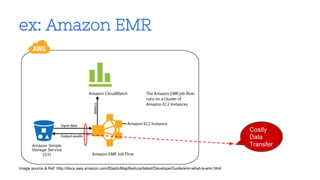
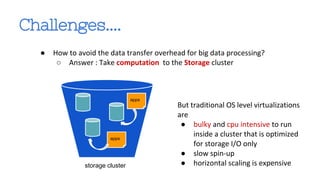
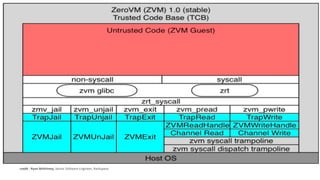
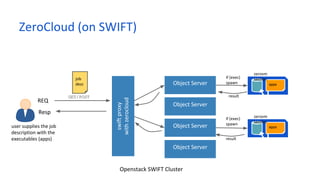
This document discusses MapReduce and Big Data processing using ZeroVM, a lightweight virtualization platform. It provides an overview of MapReduce and how it is commonly implemented using Apache Hadoop. It then describes some limitations of running MapReduce on the cloud, including costly data transfers between storage and computing clusters. The document introduces ZeroVM as a way to run applications directly on storage clusters, avoiding these transfers. It outlines how ZeroVM enables MapReduce jobs to be run on the storage layer through its ZeroCloud module. Ongoing research at UTSA is further developing ZeroVM and ZeroCloud to optimize MapReduce for data locality, load balancing, and skew handling.









































































