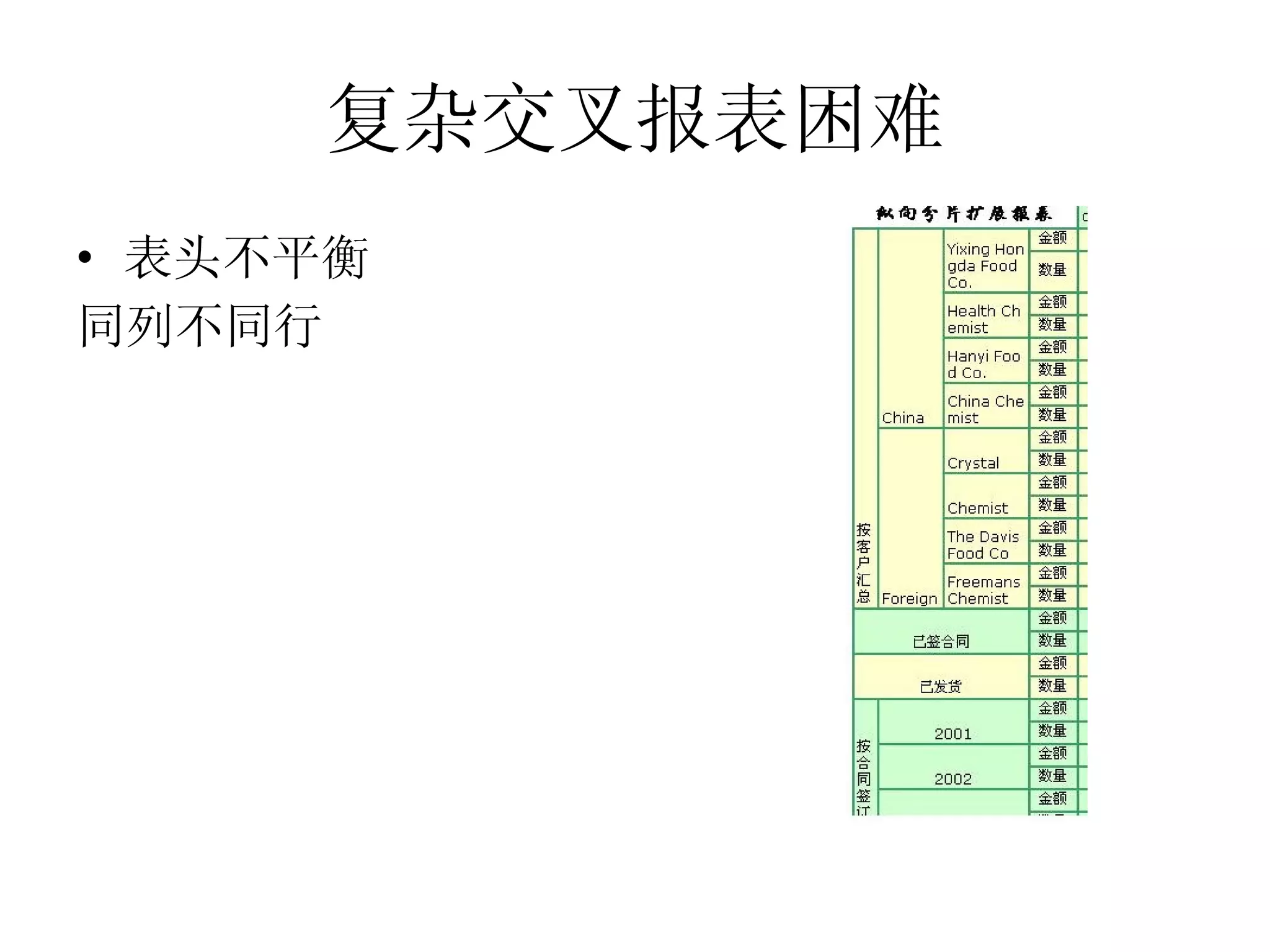
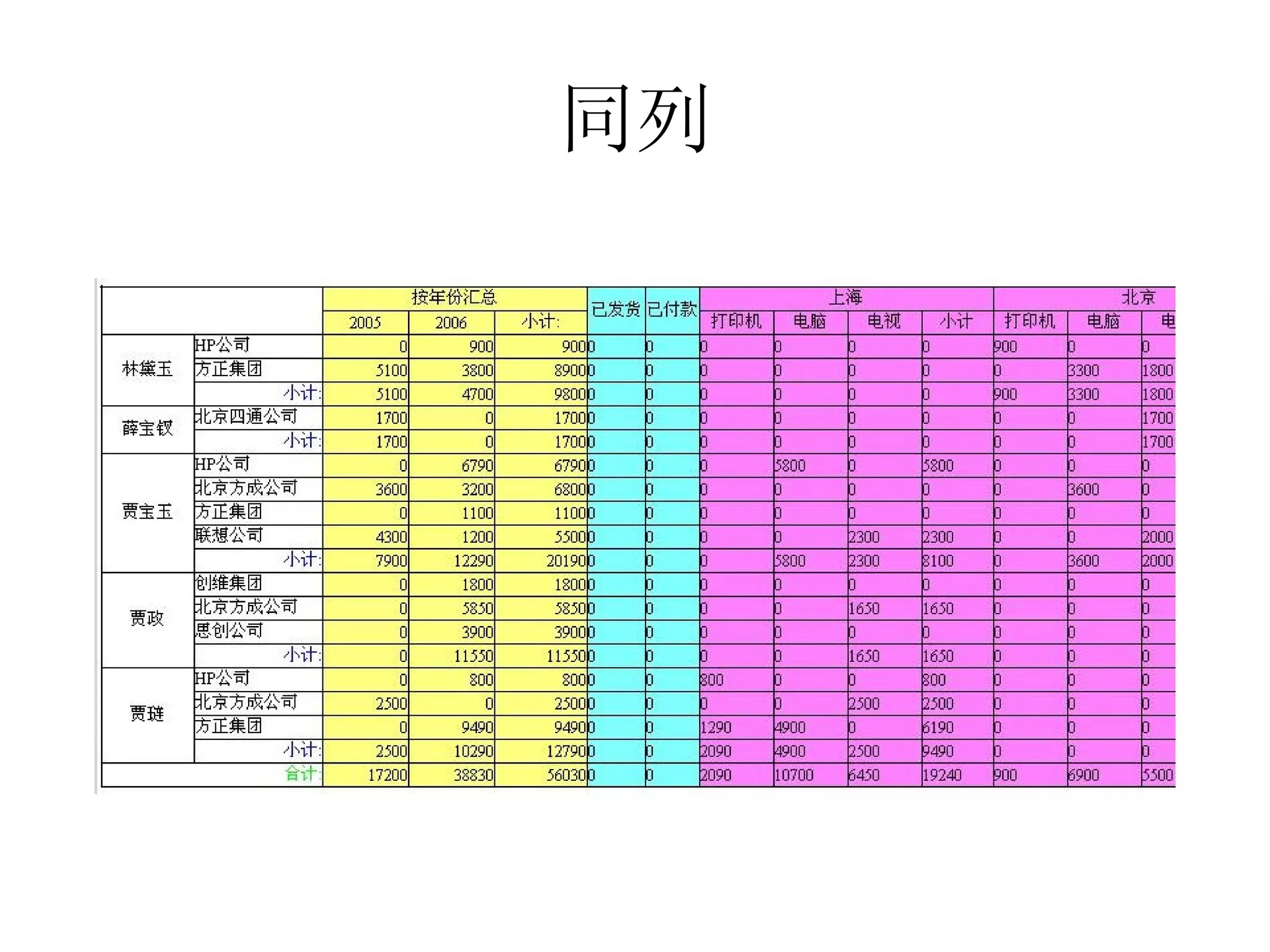
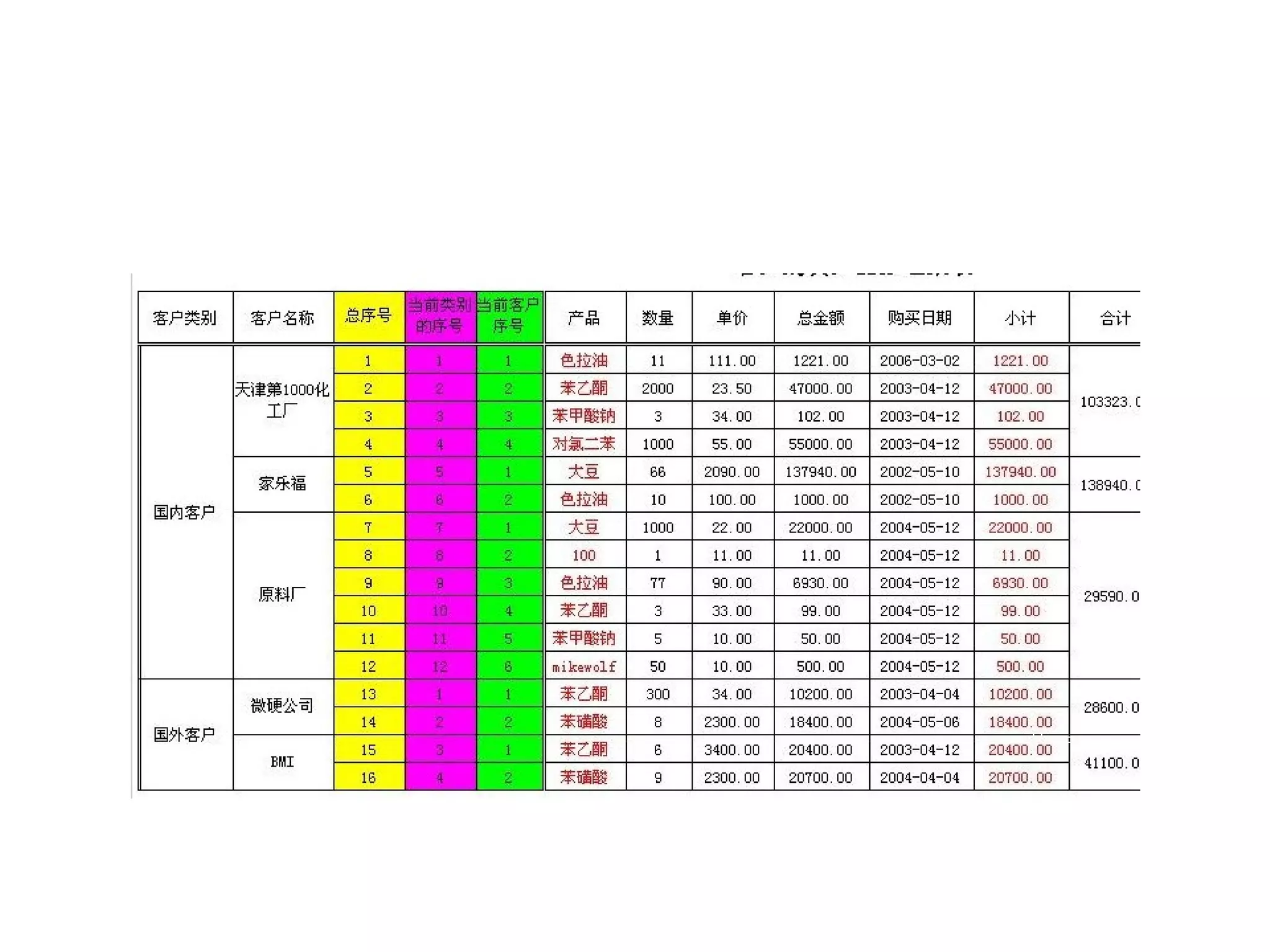
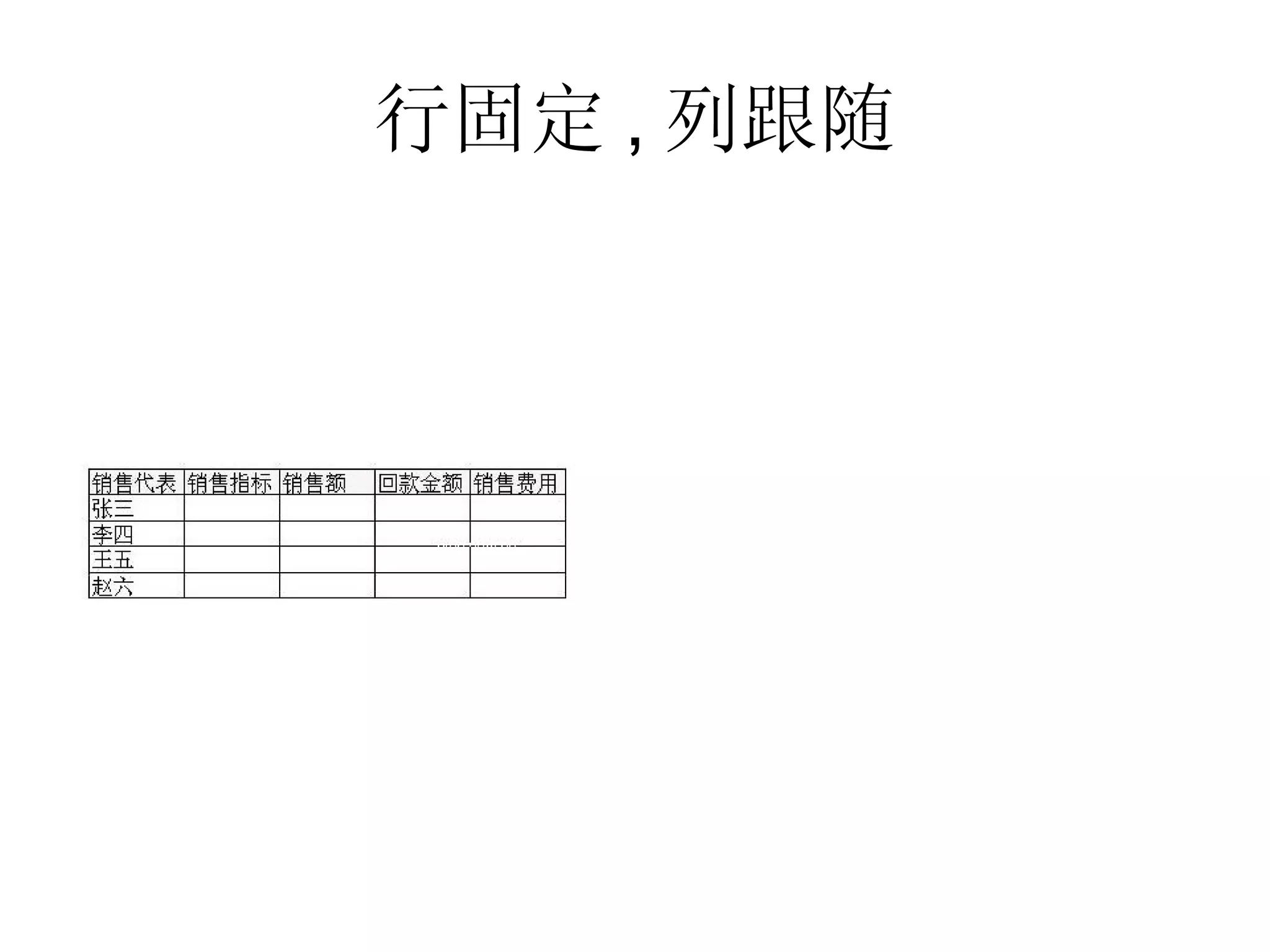
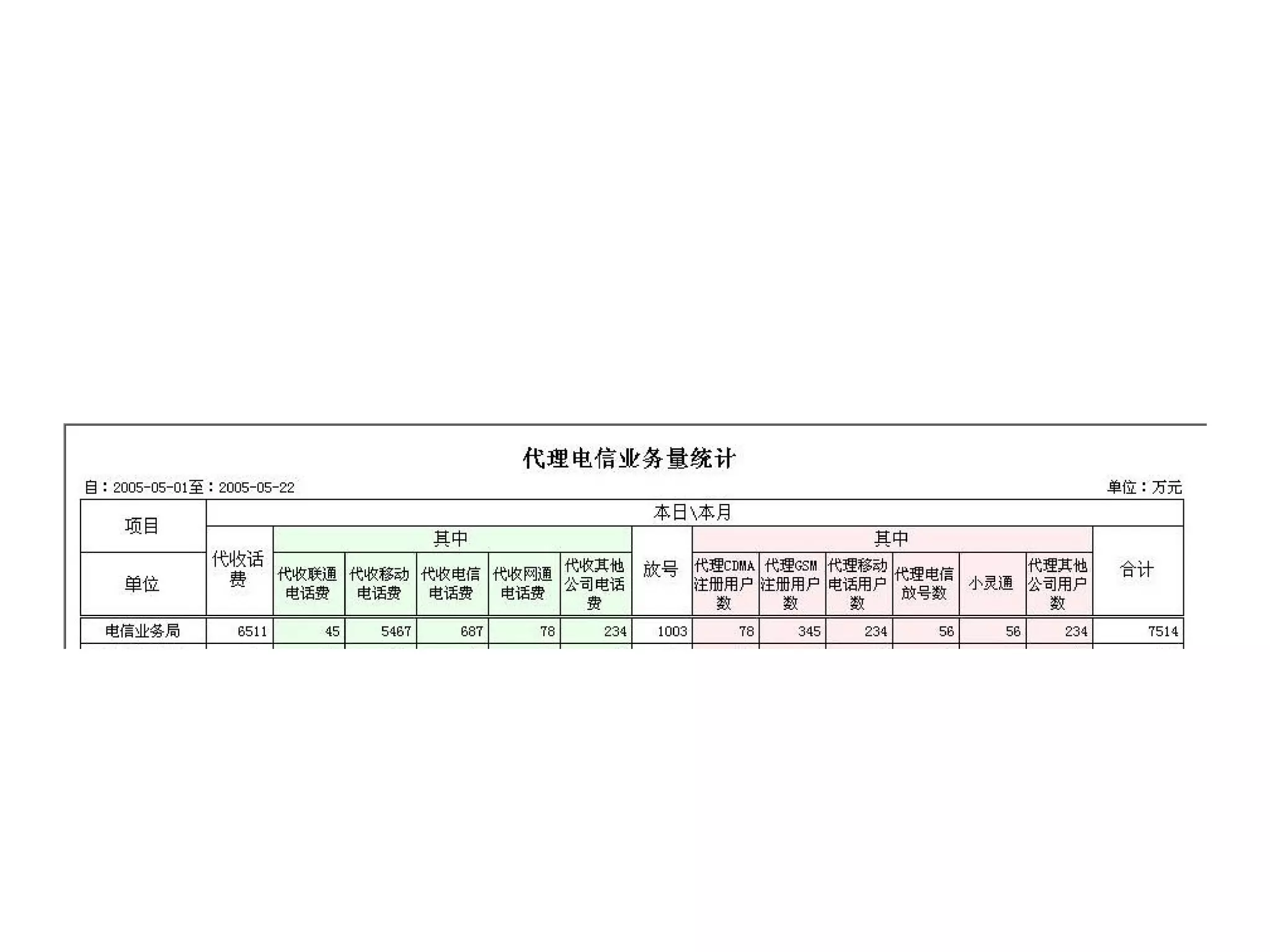
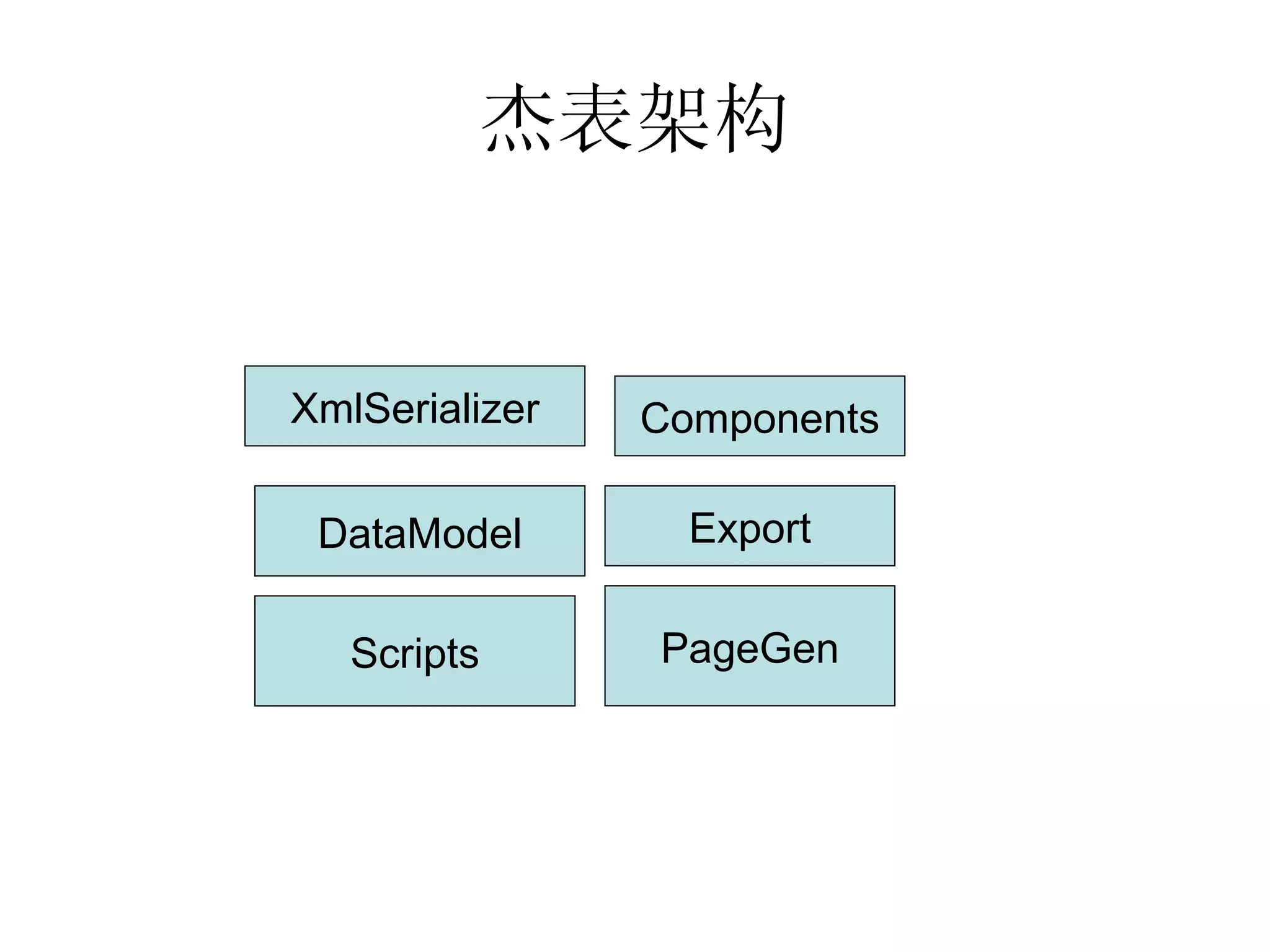
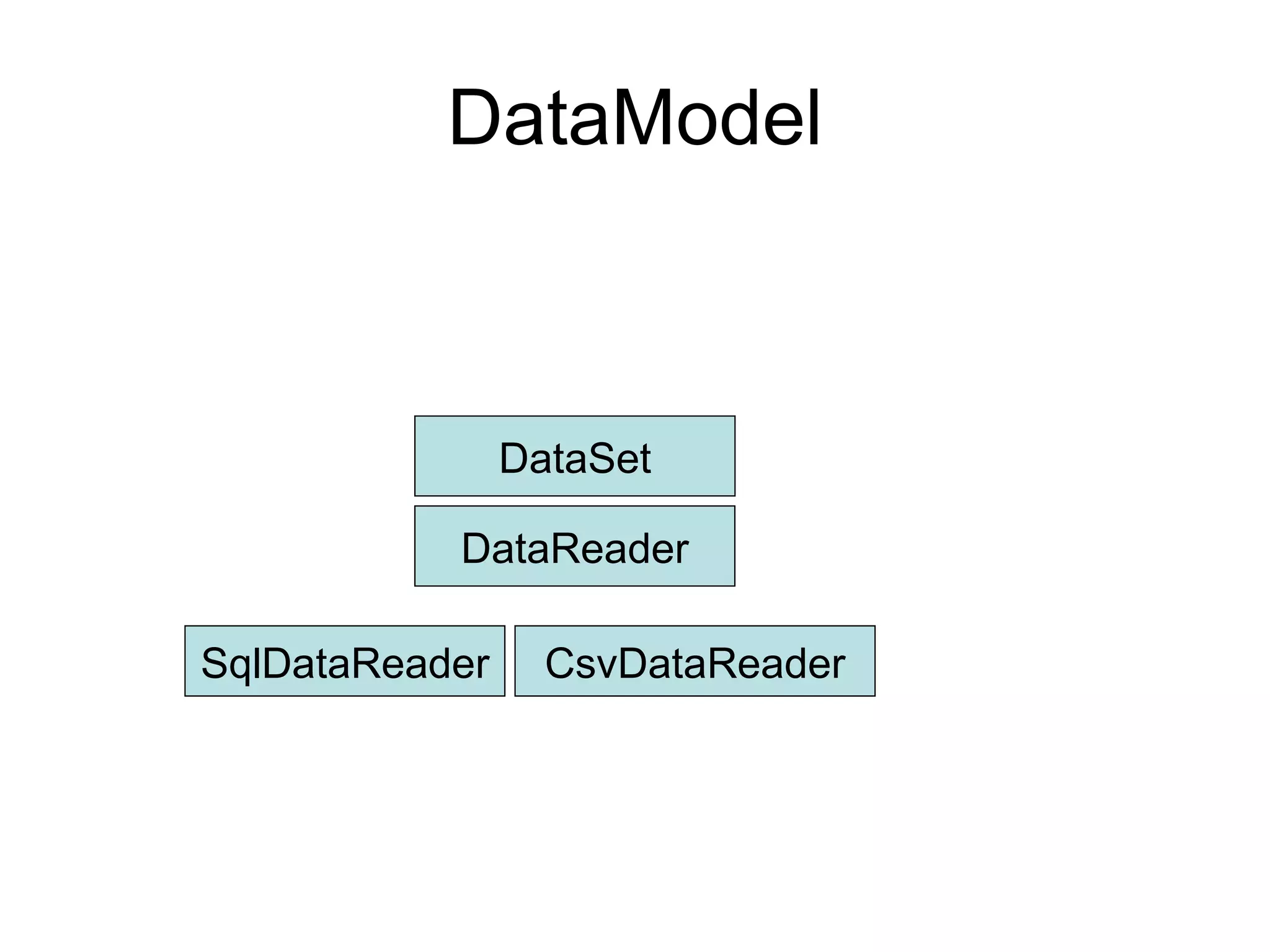
该文档详细描述了杭州杰创软件的交叉报表以及数据模型的生命周期,分析了无状态和有状态模型的优势与应用场景。文中提供了多种数据操作和节点运算的示例,包括求和、排名、过滤等,以帮助用户进行动态数据分析。还介绍了多阶段布局模型和组件类型,用于生成复杂报表。







![Model 语言 节点类型 单元 , 行 , 列 , 表格 表格 单元 // 数据源 / 班级 /@ 班长 列 // 数据源 / 班级 [0] 行](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-13-2048.jpg)
![单元节点引用 行节点 \@ 列名 dataset\ 年度销售表 [0]\@ 销售额 表 \@ 列 [i] dataset\ 年度销售表 \@ 销售额 [0] @ 列 @ 销售额](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-14-2048.jpg)
![单元节点运算 取决于值类型的运算 单元节点 , 根据其数值类型 , 可以使用相应运算 , 比如代数运算 , 及方法 如 String 类型 \\ 系统变量 \$$user.indexOf(“admin”); 如 int 类型 \\ 数据源 \ 学生 [0]\@ 年龄 +100](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-15-2048.jpg)
![行节点运算 \, 取列值 班级表 [0]\@ 班长 // ” 班长”列值](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-16-2048.jpg)

![列节点运算 ( 二 ) [i] 求某一位置单元值 , 班级表 \ 学生表 \@ 分数 [2] // 第三位置的分数 last() ,first() 求首尾的值 班级表 \ 学生表 \@ 分数 .last() // 最后一个分数 seg(c1,c2,c3,... as v1,v2,v3...), 分段函数 @ 分数 ={50,55,80,90,99,30,70,65} // 60 分以下为差 ,85 以下 , 为良 ,85 分以上为优 x = 班级表 \ 学生表 \@ 分数 .seg(<60,<85,>85 to “ 及格” ,” 良” ,” 优” ) ; // 经过上述运算后 , 所得结果为 // x ={“ 差” ,” 差” ,” 良” ,” 优” ,” 优” ,” 差” ,” 良” ,” 良” } 注 : seg() 所得结果 , 也是列节点类型](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-18-2048.jpg)
![表节点运算 ( 一 ) 取某一行 ,[i], last() ,first() 班级表 \ 学生表 [2] // 第三行 班级表 \ 学生表 .last() // 取最后一行 选择 ,select 学生表 .select(@ 学生名 ,@ 年龄 as age, @ 助学金 * 0.09 as bonus); // 返回表节点 过滤 ,[] 学生表 [@ 学生名 .startWith(“ 王” )] // 取得所有姓”王”的记录 , 返回类型 , 表节点 增加列 ,addcol 学生表 .addcol(@ 分数 .rank_desc() as 排名 ); // 增加分数排名列 销售表 .addcol(@ 单价 * @ 数量 as 金额 ) // 增加金额列](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-19-2048.jpg)
![表节点运算 ( 二 ) rows/count,columns, 取行数 , 列数 班级表 .rows() // 取行数 , 也可使用 count() 方法 班级表 .columns() // 取列数 /, 取子节点 销售额 /@ 销售额 // 取销售额 班级表 / 学生表 // 取学生表子节点 cross_select(), 取得交叉数据表 学生表 .cross_select([@ 年度 ,@ 季度 ],[@ 地区 ],[@ 销售额 .sum()]); // 返回交叉表](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-20-2048.jpg)
![交叉表运算 交叉表由 cross_select 方法得到 x=cross_select([@ 年度 ,@ 季度 ],[@ 地区 ],[@ 销售额 .sum()]); // 返回交叉表 取得轴表 ,axis0,axis1 x.axis0() // 得到第一轴表 x.axis1() // 取第二轴表 measure(), 取得度量表 x.measure()\@ 总销售 ; // 取得总销售](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-21-2048.jpg)
![同期比示例 -50 1250 2004 100 1300 2003 200 1200 2002 - 1000 2001 比去年同期新增 ( 万元 ) 销售额 ( 万元 ) 年度 年度销售表 [prev()]/@ 销售额 -@ 销售额 @ 销售额 @ 年度 比去年同期新增 ( 万元 ) 销售额 ( 万元 ) 年度](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-22-2048.jpg)

![节点操作 ( 二 ) 兄弟节点定位 (LAST,NEXT,PREV,FIRST) //dataset/mydataset[NEXT] 当前行 , 下一行数据 //dataset/mydataset[2] 第三行数据 //dataset/ 年度销售表 [PREV]/@ 销售额 取得上一年度销售额 祖先及子孙节点 //dataset/mydataset[PARENT] 选取父节点 //dataset/mydataset[..] 同上 //dataset/mydataset/@total[0] 第一行 ,total 列数据](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-24-2048.jpg)

![节点操作 ( 四 ) 节点选择 选择同节点的列 , //dataset/mydataset.select(@id,@name,@ 工资 ) 选择下一节点的列 , 作为列 //dataset/mydataset.select(@id,@name,@ 工资 , 工资经历 [FIRST]/@ 单位 ) 列节点统计 (sum,min,max,avg,count) 合计工资 //dataset/mydataset/@ 工资 .sum ()](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-26-2048.jpg)
![表格节点的管道操作 表格节点的操作 选择操作 select 过滤操作 […] 排序操作 order 分组统计操作 group 分段统计 select(*,seg(@key,[1,2,3,4],[1,2,3,4]) as xx )](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-27-2048.jpg)
![列定义 ( 一 ) 列定义使用在 select 中 Dataset.select([*],[, 列定义 ]+) *, 表示选取所有列 列定义可以使用 [ 列表达式 ] [as [ 列名 ]] 列定义表达式 @ 单价 * @ 数量 as 金额 @ 单价 as 新单价 @ 单价](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-28-2048.jpg)
![SEG,RANK 列函数 分段函数 Seg seg( 名次 <15 , 名次 >=15 && 名次 <35, 名次 >=35],[“ 优” ,” 良” ,” 差” ]) as 级别 把 15 名以下的称为优 ,15-35 称为良 ,35 以上的称为差 排名函数 rank // 按分数降序排 selecta(rank( 分数 desc) as 名次 ) // 按 gdp 升序排 selecta(rank(GDP asc) as 名次 )](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-29-2048.jpg)
![列函数综合举例 学生成绩表 学生名 , 班级 , 分数 -> 班级 级别 人数 x = 学生成绩表 .selecta(rank( 分数 ) as 名次 ); x= x.select( 班级 , seg(@ 名次 <15 ,@ 名次 >=15 && @ 名次 <35, @ 名次 >=35],[“ 优” ,” 良” ,” 差” ]) as 级别 ); x=x.group(*,count() as 人数 by 班级 , 级别 ); 5<aaa<10;](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-30-2048.jpg)



![固定布局 行表 , 列表 , 交叉表 打印列表 , 打印行表 , 打印出列表 列表自动折页处理 c rosslayout( 列表 , 行表 , 交叉表 ) crosslayout( 列表 , 行表 .select(0..*,10..20), 交叉表 (0..*,10,20)]; table.add( 列表 ,0,0); table.add()](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-34-2048.jpg)
![流式布局 行表 , 列表 , 交叉表 打印列表 , 打印行表 , 打印出列表 c rosslayout( 列表 , 行表 , 交叉表 ) crosslayout( 列表 , 行表 .select(0..*,10..20), 交叉表 (0..*,10,20)]; table.add( 列表 ,0,0); table.add()](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-35-2048.jpg)

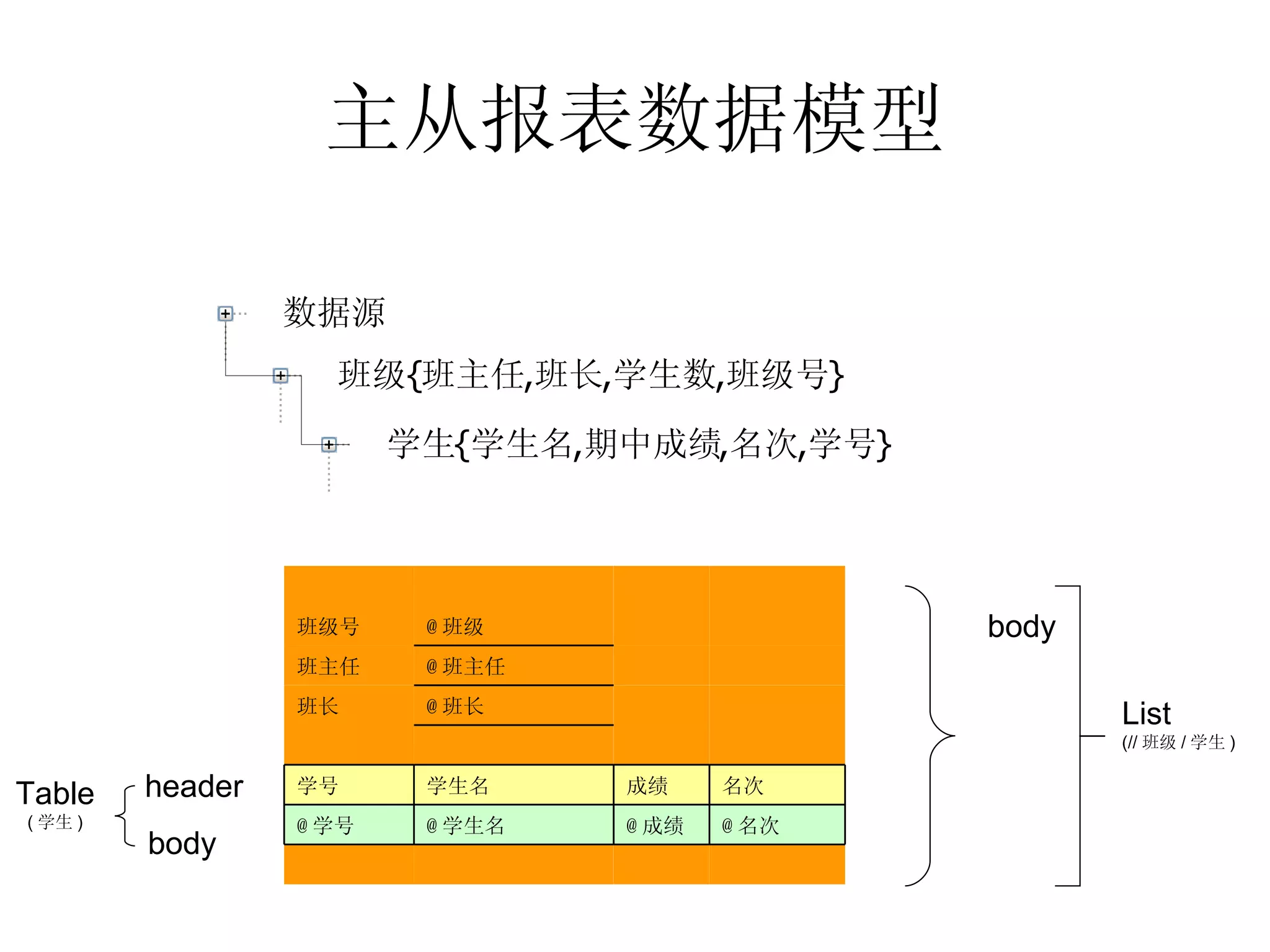
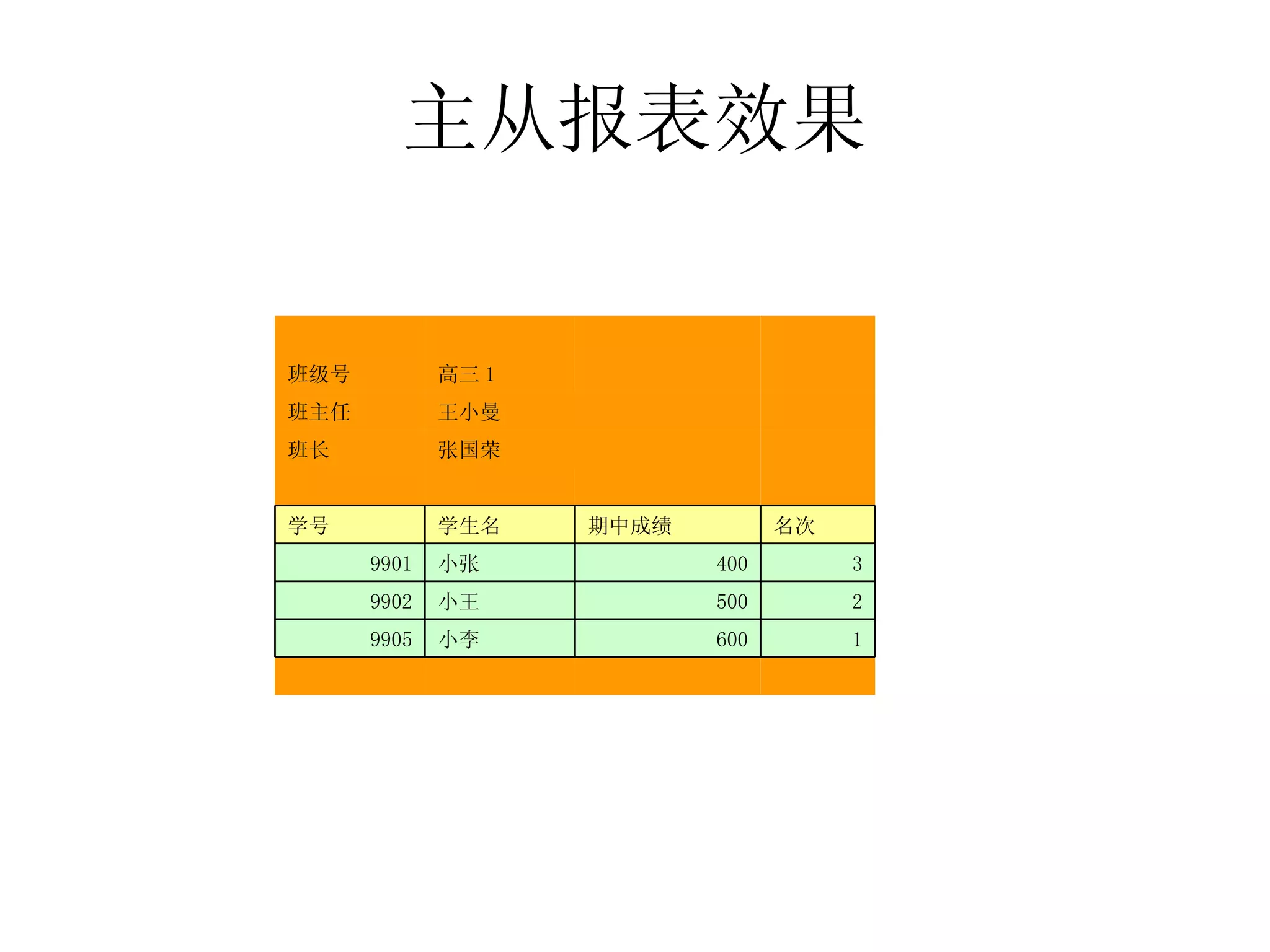
![主从报表数据模型 人员表 .y 轴 人员表 .x 轴 人员表 1[@ 部门 =: 部门 && 年龄段 =: 年龄段 ] 总计 body 41-55 31-40 20-30 年龄段 部门 18 22 17 总计 2 3 3 财务部 5 2 经理办公室 0 2 研发部 4 0 4 生产部 4 0 3 技术部 5 8 2 广告部 3 6 1 市场部 41-55 31-40 20-30 年龄段 部门](https://image.slidesharecdn.com/2008-090927033016-phpapp02/75/2008-41-2048.jpg)






























