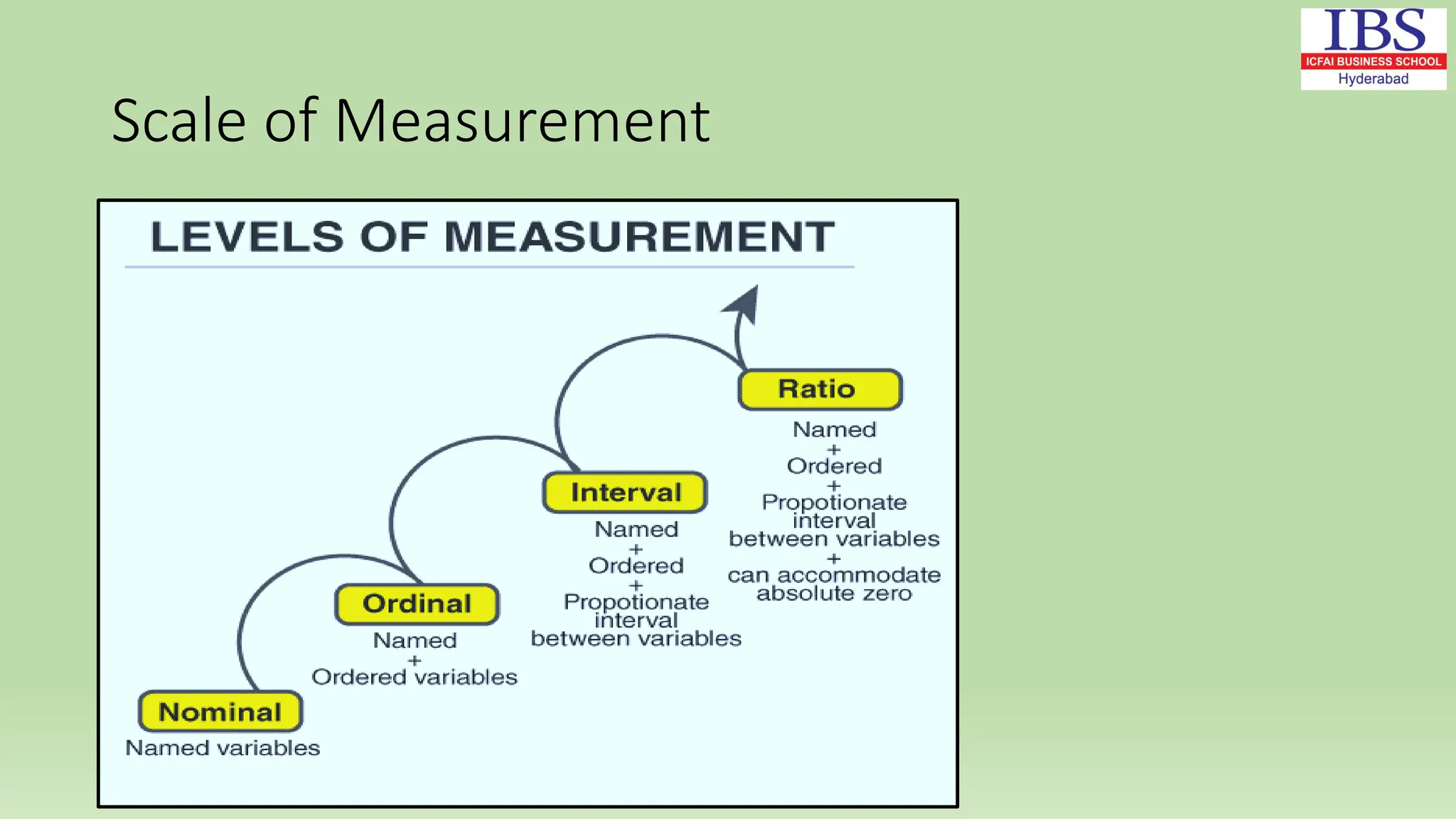
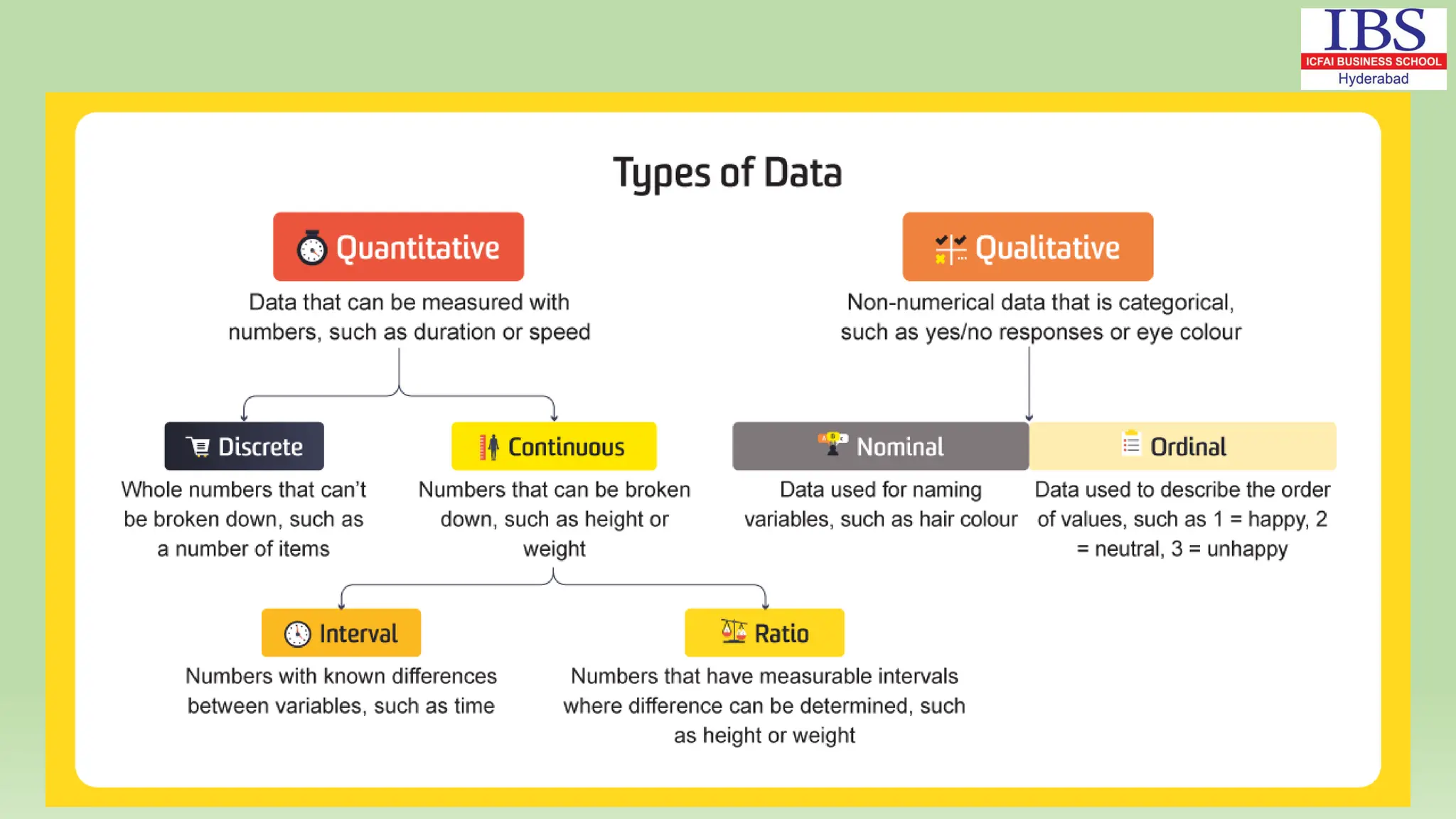
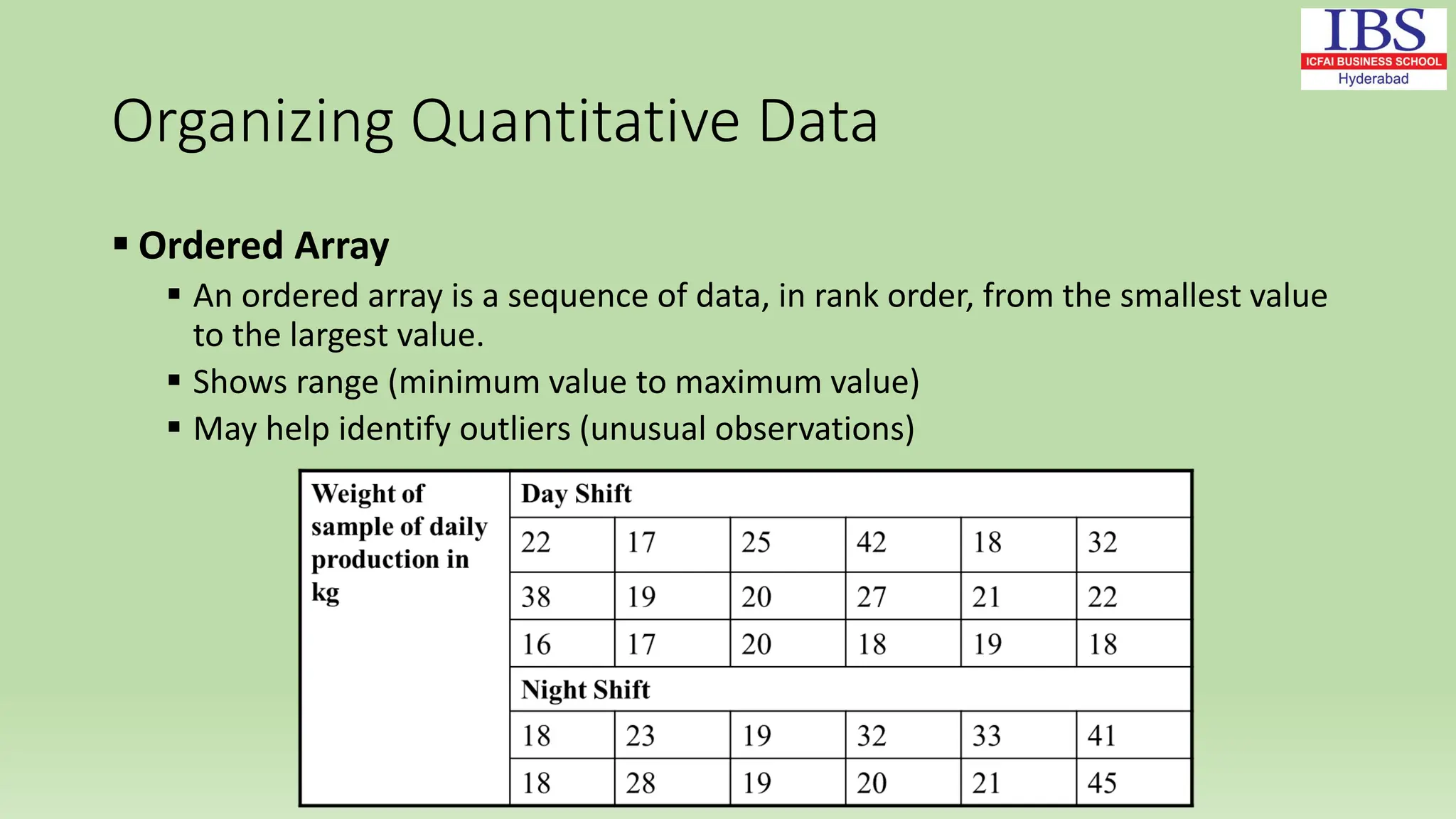
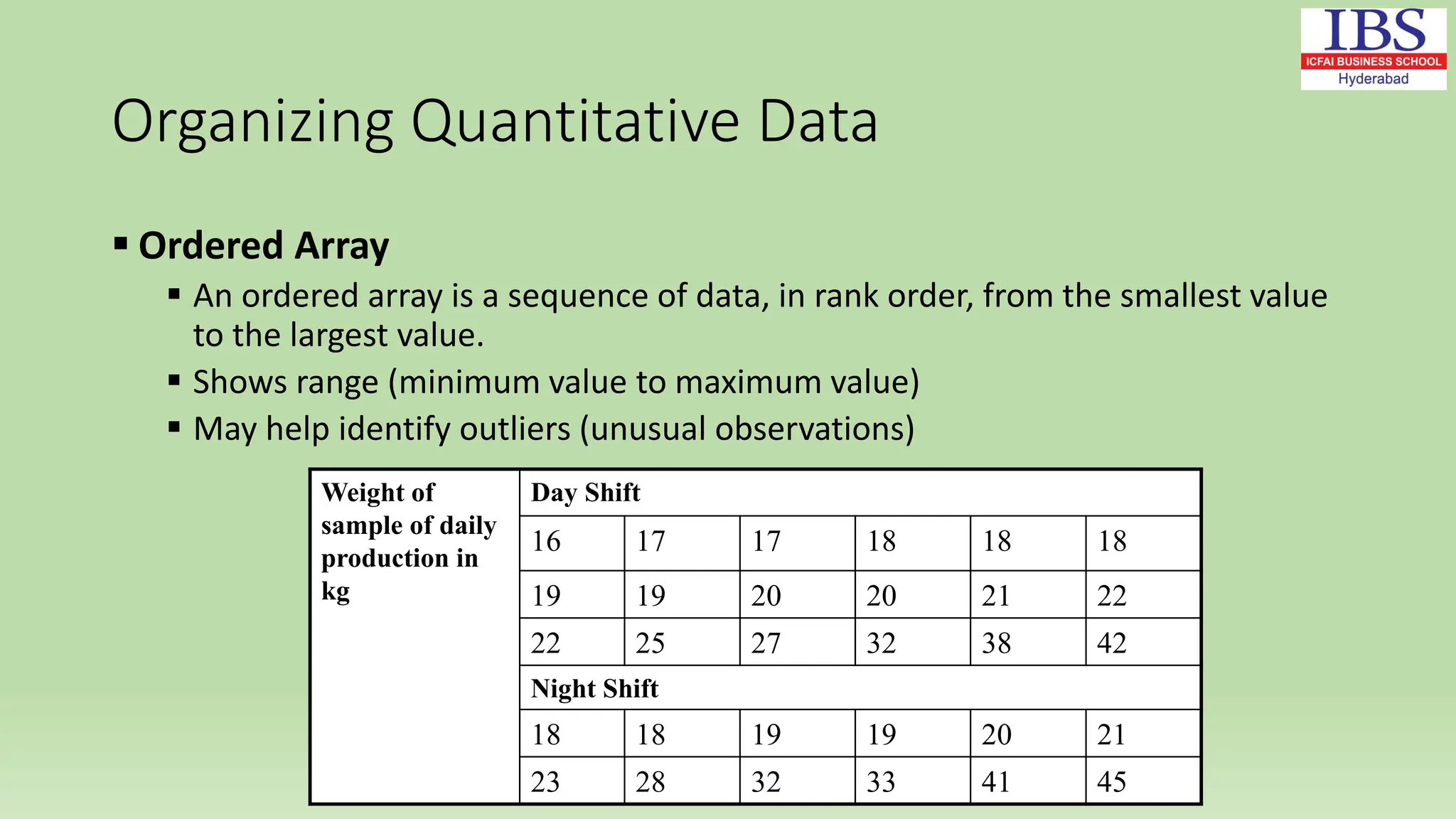
Chapter 2 of Dr. Rashmita Saran's document covers numerical descriptive measures, including classification of data (qualitative and quantitative), data representation methods, frequency distribution, and key descriptive statistics (mean, median, mode, standard deviation). It explains various types of data, the importance of accuracy in data collection, and the scales of measurement (nominal, ordinal, interval, and ratio). The chapter also discusses methods for organizing data and calculating measures of central tendency and dispersion.

![Outline
• Classification of Data
•Data Representation
• Frequency distribution
•Descriptive Statistics[Mean, Median, Mode, Standard
deviation]
• Outliers
• Skewness & Kurtosis](https://image.slidesharecdn.com/2-241121070922-5ee24598/75/2-Numerical-Descriptive-Measures-1-pdf-2-2048.jpg)






















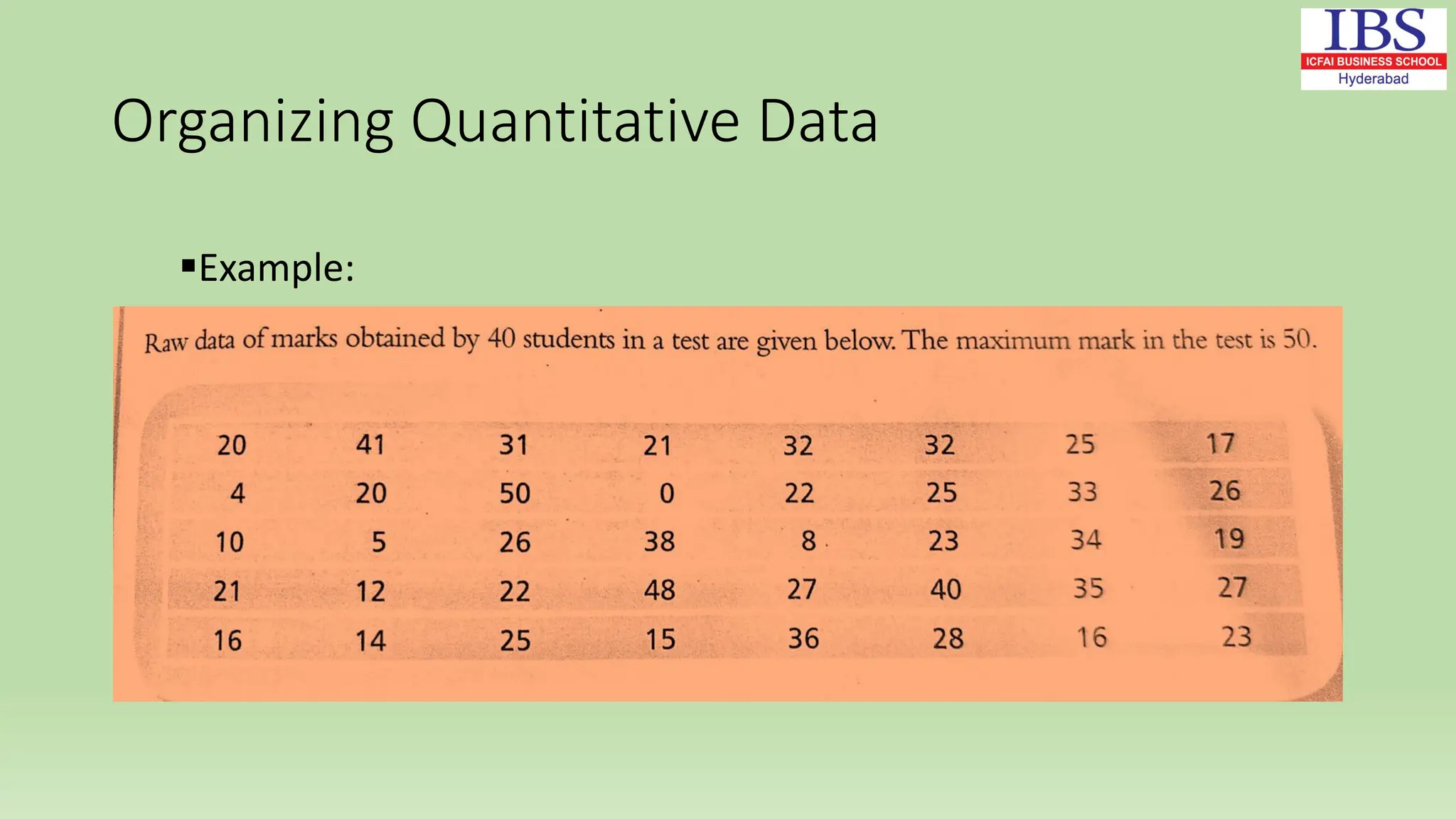

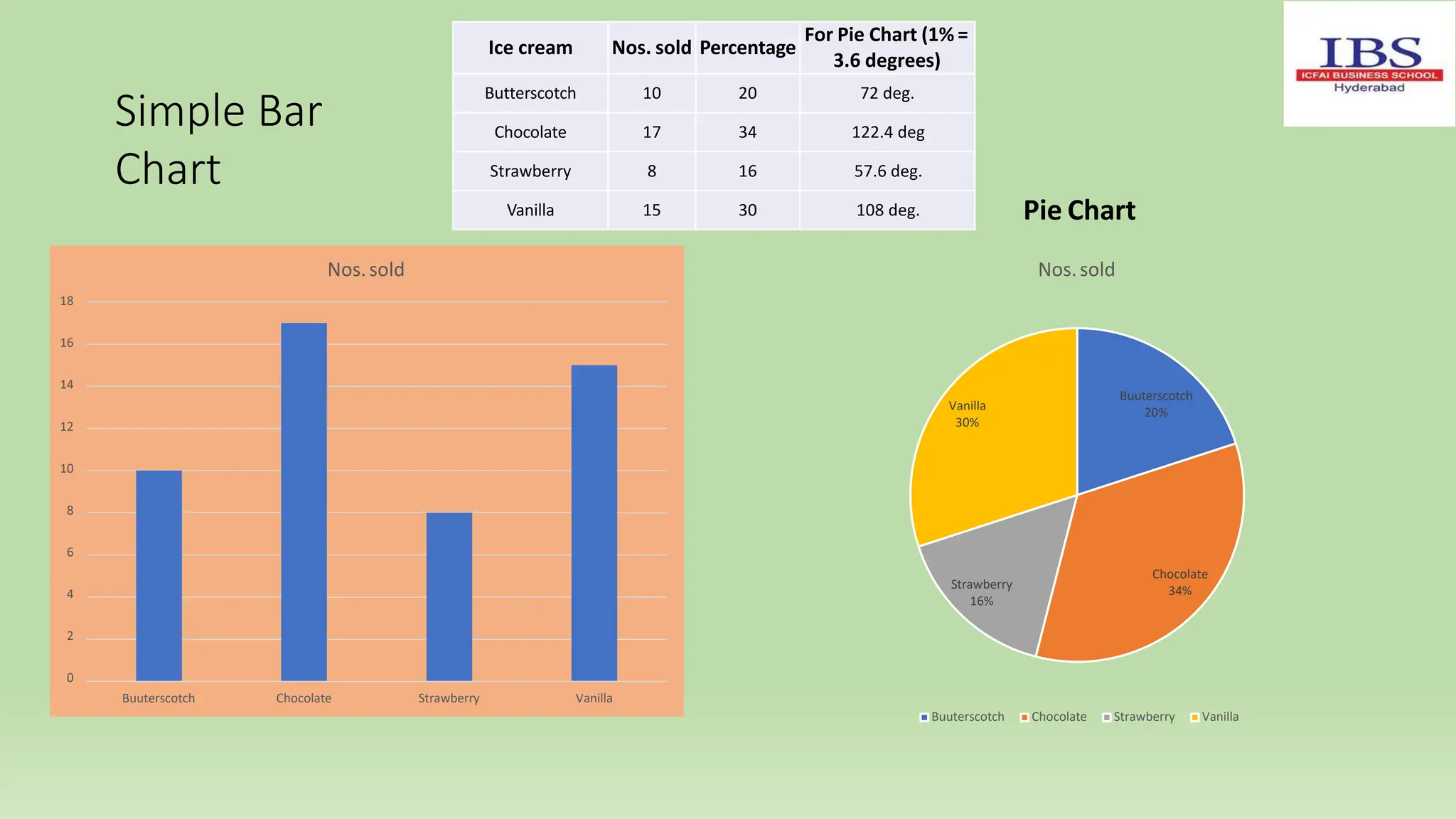
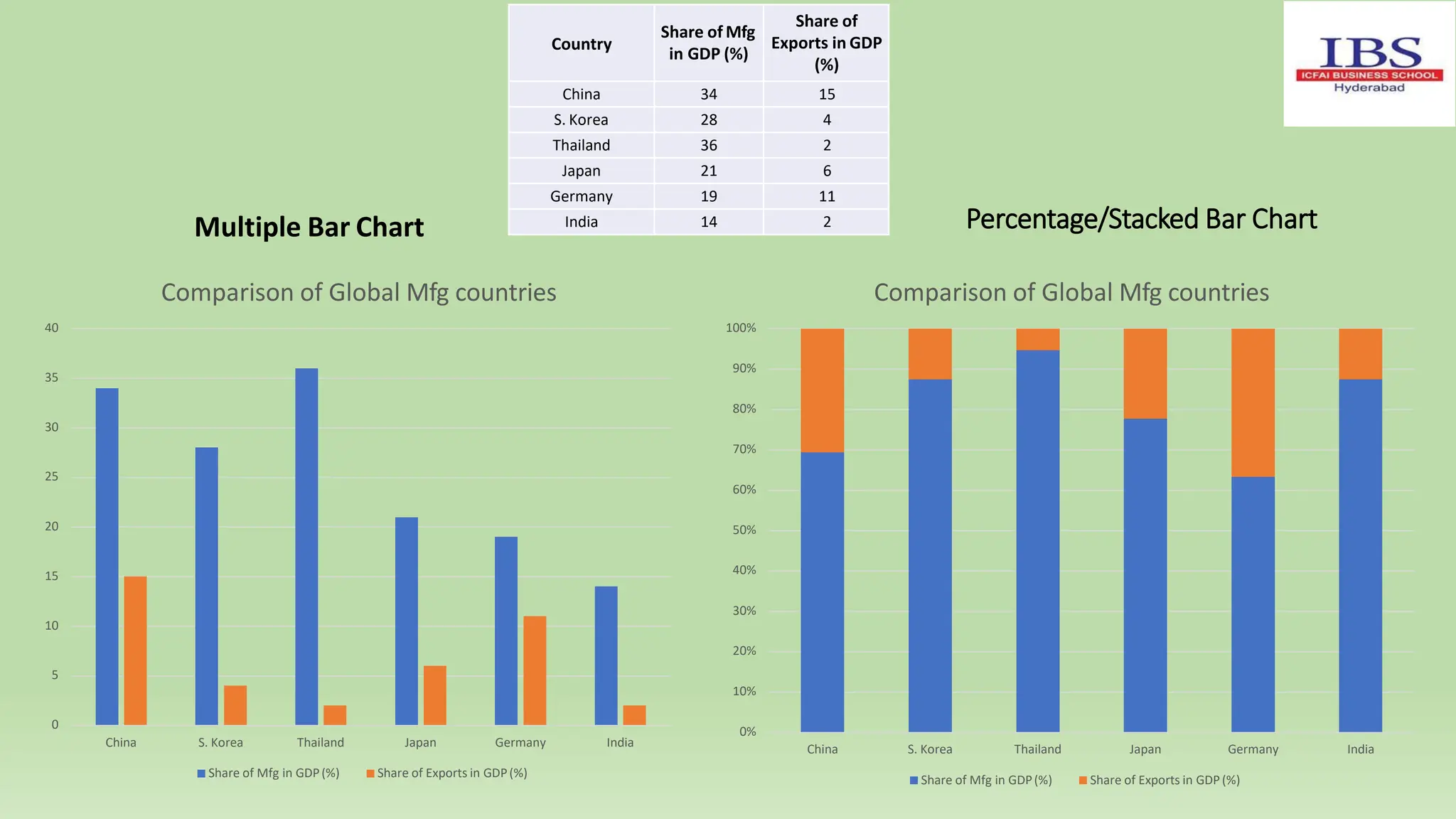
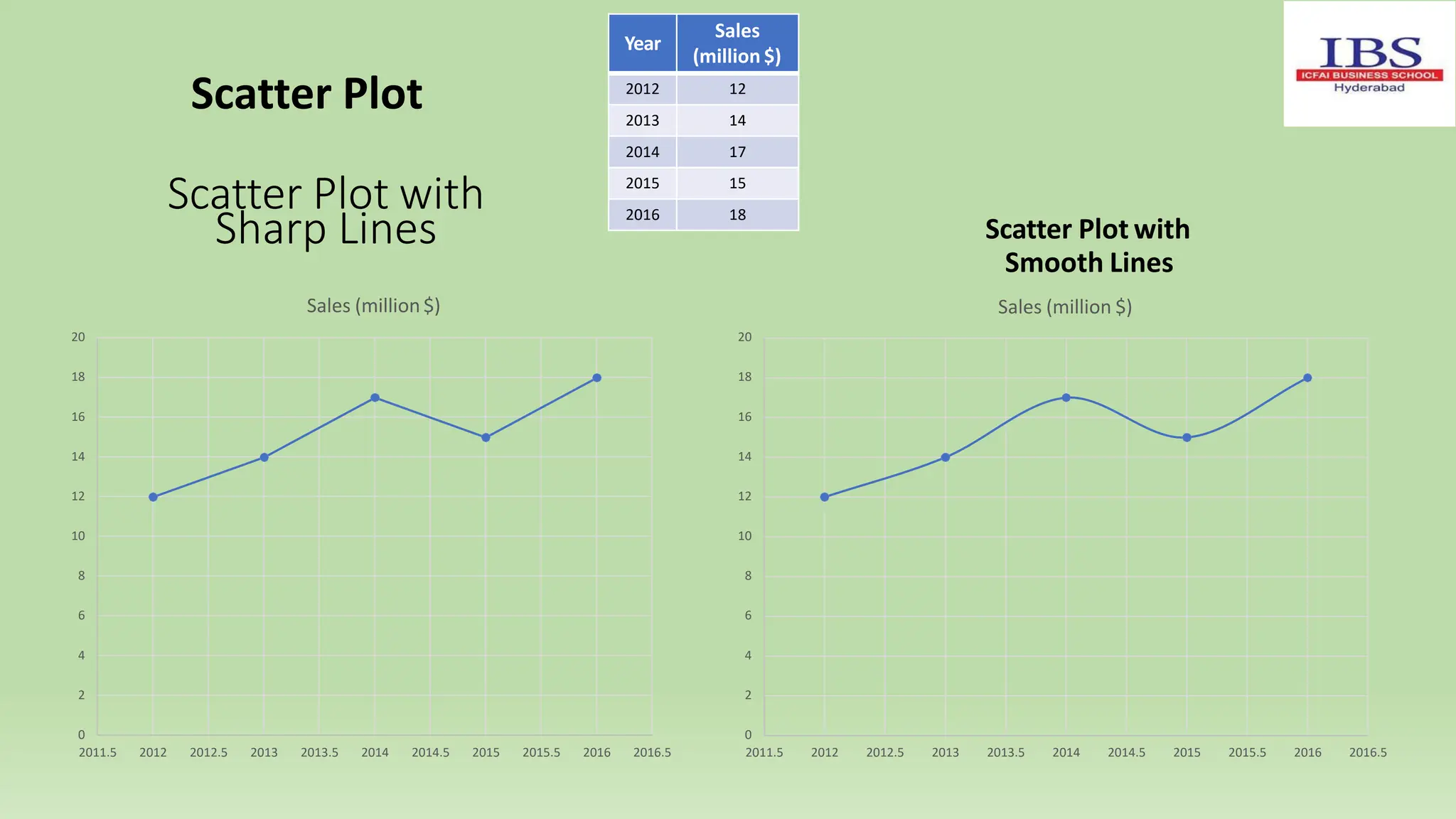











![Examples of Median (Ungrouped data):
1. The class size of five sections of first year students are 32, 56, 42, 46, 48 respectively. Find the median no.
of students.
Key: Arrange the nos. in ascending order: 32, 42, 46, 48, 56
No. of observations n = 5 (odd)
Median value = [(n+1)/2]th observation
= [(5+1)/2]th observation
= 3rd observation = 46
The median no. of students is 46.
2. A batsman scored 1, 113, 148, 22, 24, 27, 15, 16, 16 & 28 runs in the last 10 innings. Using an appropriate
measure, find his average score.
Key: Since there are 2 extreme scores 113 & 148, hence mean would be affected by these values. Here,
median would be an appropriate measure.
Arrangement: 1, 15, 16, 16, 22, 24, 27, 28, 113, 148.
No. of observations, n = 10 (even)
Median = Mean of (n/2)th and (n/2+1)th observations
= Mean of 5th and 6th observations
= (22+24)/2 = 23
The median score of the batsman is 23 runs.](https://image.slidesharecdn.com/2-241121070922-5ee24598/75/2-Numerical-Descriptive-Measures-1-pdf-57-2048.jpg)






![• If the average of two distributions are almost same, then the distribution with
smaller range is said to have less dispersion.
• Lesser value of range indicates more consistency in the distribution.
• Coefficient of range = (L-S)/(L+S) [The relative measure of range]
• Range is widely used for statistical quality control. If the dimensions of products
are beyond a defined range, they are discarded.
• It facilitates the study of variations in the prices of shares, agricultural products
and other commodities.
• It also helps in weather forecasts by indicating minimum and maximum
temperature.
Range](https://image.slidesharecdn.com/2-241121070922-5ee24598/75/2-Numerical-Descriptive-Measures-1-pdf-66-2048.jpg)




![Example
• Q1 = [(n+1)/4]th observation, and Q3 = [3(n+1)/4]th observation
• Ex: 1, 15, 16, 16, 22, 24, 27, 28, 113, 148; Q1 = 2.75th obs. and Q3 =
8.25th obs.
• Q1 = 2nd term + 0.75 (3rd term – 2nd term) = 15 + 0.75 (16-15) =
15.75
• Q3 = 8th term + 0.25 (9th term – 8th term) = 28 + 0.25
(113-28) = 49.25 QD = (49.25 – 15.75)/2 = 16.75
and
• Coeff. of QD = (49.25 – 15.75)/(49.25 + 15.75) = 0.5154 or
51.54%](https://image.slidesharecdn.com/2-241121070922-5ee24598/75/2-Numerical-Descriptive-Measures-1-pdf-72-2048.jpg)