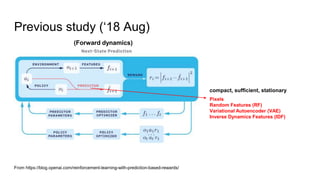
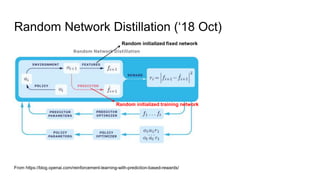
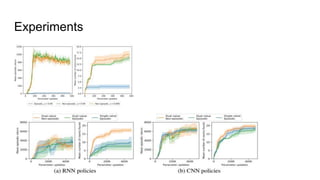
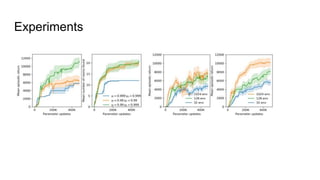
This document discusses using random network distillation to provide intrinsic rewards for reinforcement learning agents. It summarizes a previous study that used prediction error as an intrinsic reward across diverse environments. The document then proposes using random network distillation, where a randomly initialized fixed network predicts the outputs of a randomly initialized training network, to provide intrinsic rewards. This allows scaling to high-dimensional observations and solving problems with stochastic dynamics. Experiments are proposed to test combining intrinsic rewards from random network distillation with extrinsic rewards on diverse environments.