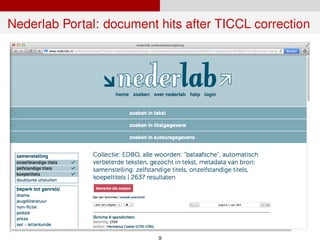
Nederlab is a consortium that aims to bring together digitized Dutch texts from 800 AD to the present into one online interface. This includes newspapers from 1618-1995 and early Dutch books. The texts are converted to a uniform XML format and processed with tools like TICCL to correct OCR errors. Volunteers are helping to transcribe newspapers. Future work includes incorporating other projects' corpus exploration tools to enhance the portal.