This document discusses the Lorenz curve and Gini coefficient, which are methods used to measure income inequality. The Lorenz curve graphs the cumulative percentages of total income received against the cumulative number of recipients. The more bowed out a Lorenz curve is, the more unequal the income distribution. The Gini coefficient is a number between 0 and 1 that measures the area between the perfect equality line and the Lorenz curve. Higher Gini coefficients indicate more unequal income distribution. Examples of Gini coefficients are provided for several developed economies.
Modified naive bayes model for improved web page classificationHammad Haleem
The document proposes a modified naive Bayes model for improved web page classification compared to the traditional naive Bayes model. It presents the objective to optimize the traditional model's performance in terms of cost and time. The document describes the traditional model and the proposed modifications. Experimental results on a 20 newsgroup dataset using random subset sampling and k-fold cross validation show the proposed model provides higher accuracy for various training sizes and number of folds compared to the traditional model. The conclusions state the proposed model has better performance due to replacing long multiplication with addition and avoiding problems with zero probabilities and floating point underflow.
MẠNG NƠRON VÀ QUÁ TRÌNH HỌC CỦA MẠNG NƠRON Bông Bông
Trong rất nhiều lĩnh vực như điều khiển, tự động hóa, công nghệ thông tin…, nhận dạng được đối tượng là vấn đề mấu chốt quyết định sự thành công của bài toán. Một nhược điểm khi dùng mạng nơron là chưa có phương pháp luận chung khi thiết kế cấu trúc mạng cho các bài toán nhận dạng và điều khiển mà phải cần tới kiến thức của chuyên gia. Mặt khác khi xấp xỉ mạng nơron với một hệ phi tuyến sẽ khó khăn khi luyện mạng vì có thể không tìm được điểm tối ưu toàn cục... Hiện nay, việc nghiên cứu các thuật toán tìm nghiệm tối ưu toàn cục khi luyện mạng nơron đã được một số tác giả nghiên cứu áp dụng. Tuy nhiên khi sử dụng mạng nơron để xấp xỉ một số đối tượng phi tuyến mà mặt lỗi sinh ra có dạng lòng khe, việc huấn luyện mạng gặp rất nhiều khó khăn. Nội dung đề tài sẽ đi nghiên cứu một thuật toán tìm điểm tối ưu toàn cục trong quá trình luyện mạng nơron bằng thuật toán vượt khe có sự kết hợp với giải thuật di truyền.
MỘT SỐ NGUY CƠ ĐỐI VỚI AN TOÀN, BẢO MẬT THÔNG TIN TRÊN MẠNG CNTT CƠ QUAN ĐẢNG...Vu Hung Nguyen
Hội thảo Hợp tác Phát triển CNTT-TT Việt Nam lần thứ 17 sẽ diễn ra tại khách sạn Xanh thành phố Huế từ ngày 29 đến 31/8/2013. Hội thảo do Bộ Thông tin và Truyền thông, UBND tỉnh Thừa Thiên Huế, Hội Tin học Việt Nam và Hội Tin học thành phố Hồ Chí Minh đồng tổ chức với chủ đề “Xây dựng hạ tầng CNTT-TT đồng bộ từ Trung ương đến địa phương tạo động lực phát triển kinh tế - xã hội”
http://ict2013.thuathienhue.gov.vn/
Riêng với những ai đang học và làm việc mảng điện tử thì cũng đã có các giáo trình cơ bản, nhưng như thế cũng chưa thỏa được sự mong muốn học hỏi và nâng cao chuyên môn, thì Trọn bộ Tài Liệu Chuyên Ngành Kỹ Thuật Điện Tử này sẽ giúp bạn chọn đúng tài liệu mình cần, có thể đọc mọi lúc mọi nơi, không phải ai cũng có nhiều thời gian rảnh để tự đọc sách ở nhà, bạn có thể copy Trọn bộ Tài Liệu Chuyên Ngành Kỹ Thuật Điện Tử vào điện thoại, máy tính bảng hoặc trên cloud và đọc khi cần.
This document discusses the Lorenz curve and Gini coefficient, which are methods used to measure income inequality. The Lorenz curve graphs the cumulative percentages of total income received against the cumulative number of recipients. The more bowed out a Lorenz curve is, the more unequal the income distribution. The Gini coefficient is a number between 0 and 1 that measures the area between the perfect equality line and the Lorenz curve. Higher Gini coefficients indicate more unequal income distribution. Examples of Gini coefficients are provided for several developed economies.
Modified naive bayes model for improved web page classificationHammad Haleem
The document proposes a modified naive Bayes model for improved web page classification compared to the traditional naive Bayes model. It presents the objective to optimize the traditional model's performance in terms of cost and time. The document describes the traditional model and the proposed modifications. Experimental results on a 20 newsgroup dataset using random subset sampling and k-fold cross validation show the proposed model provides higher accuracy for various training sizes and number of folds compared to the traditional model. The conclusions state the proposed model has better performance due to replacing long multiplication with addition and avoiding problems with zero probabilities and floating point underflow.
MẠNG NƠRON VÀ QUÁ TRÌNH HỌC CỦA MẠNG NƠRON Bông Bông
Trong rất nhiều lĩnh vực như điều khiển, tự động hóa, công nghệ thông tin…, nhận dạng được đối tượng là vấn đề mấu chốt quyết định sự thành công của bài toán. Một nhược điểm khi dùng mạng nơron là chưa có phương pháp luận chung khi thiết kế cấu trúc mạng cho các bài toán nhận dạng và điều khiển mà phải cần tới kiến thức của chuyên gia. Mặt khác khi xấp xỉ mạng nơron với một hệ phi tuyến sẽ khó khăn khi luyện mạng vì có thể không tìm được điểm tối ưu toàn cục... Hiện nay, việc nghiên cứu các thuật toán tìm nghiệm tối ưu toàn cục khi luyện mạng nơron đã được một số tác giả nghiên cứu áp dụng. Tuy nhiên khi sử dụng mạng nơron để xấp xỉ một số đối tượng phi tuyến mà mặt lỗi sinh ra có dạng lòng khe, việc huấn luyện mạng gặp rất nhiều khó khăn. Nội dung đề tài sẽ đi nghiên cứu một thuật toán tìm điểm tối ưu toàn cục trong quá trình luyện mạng nơron bằng thuật toán vượt khe có sự kết hợp với giải thuật di truyền.
MỘT SỐ NGUY CƠ ĐỐI VỚI AN TOÀN, BẢO MẬT THÔNG TIN TRÊN MẠNG CNTT CƠ QUAN ĐẢNG...Vu Hung Nguyen
Hội thảo Hợp tác Phát triển CNTT-TT Việt Nam lần thứ 17 sẽ diễn ra tại khách sạn Xanh thành phố Huế từ ngày 29 đến 31/8/2013. Hội thảo do Bộ Thông tin và Truyền thông, UBND tỉnh Thừa Thiên Huế, Hội Tin học Việt Nam và Hội Tin học thành phố Hồ Chí Minh đồng tổ chức với chủ đề “Xây dựng hạ tầng CNTT-TT đồng bộ từ Trung ương đến địa phương tạo động lực phát triển kinh tế - xã hội”
http://ict2013.thuathienhue.gov.vn/
Riêng với những ai đang học và làm việc mảng điện tử thì cũng đã có các giáo trình cơ bản, nhưng như thế cũng chưa thỏa được sự mong muốn học hỏi và nâng cao chuyên môn, thì Trọn bộ Tài Liệu Chuyên Ngành Kỹ Thuật Điện Tử này sẽ giúp bạn chọn đúng tài liệu mình cần, có thể đọc mọi lúc mọi nơi, không phải ai cũng có nhiều thời gian rảnh để tự đọc sách ở nhà, bạn có thể copy Trọn bộ Tài Liệu Chuyên Ngành Kỹ Thuật Điện Tử vào điện thoại, máy tính bảng hoặc trên cloud và đọc khi cần.
An Toàn và bảo mật HTTT-Cơ bản về mã hoá (cryptography)
09 hc -_bai_tap_nop_so_4
1. Khai thác dữ liệu và ứng dụng
BÀI TẬP NỘP SỐ 4
Phân lớp
Sinh viên đại diện nhóm upload một tập tin <tên nhóm>.zip hoặc <tên nhóm>.rar nén bên trong
là các tập tin cần thiết cho bài nộp
Những dòng đầu của tập tin báo cáo là:
- Tên nhóm
- Danh sách các thành viên trong nhóm có tham gia vào bài tập
- Tỉ lệ đóng góp của mỗi thành viên.
Lưu ý:
- Bài nộp không theo đúng quy định này sẽ bị trừ điểm
- Mỗi nhóm phải tự làm bài. Các bài làm giống nhau sẽ bị điểm 0.
A. Lý thuyết
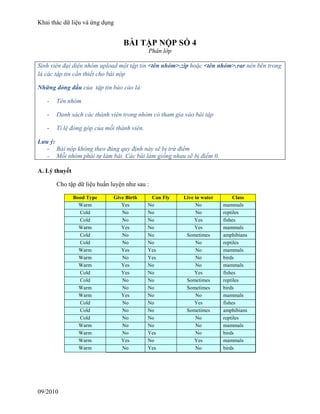
Cho tập dữ liệu huấn luyện như sau :
Bood Type Give Birth Can Fly Live in water Class
Warm Yes No No mammals
Cold No No No reptiles
Cold No No Yes fishes
Warm Yes No Yes mammals
Cold No No Sometimes amphibians
Cold No No No reptiles
Warm Yes Yes No mammals
Warm No Yes No birds
Warm Yes No No mammals
Cold Yes No Yes fishes
Cold No No Sometimes reptiles
Warm No No Sometimes birds
Warm Yes No No mammals
Cold No No Yes fishes
Cold No No Sometimes amphibians
Cold No No No reptiles
Warm No No No mammals
Warm No Yes No birds
Warm Yes No Yes mammals
Warm No Yes No birds
09/2010
2. Khai thác dữ liệu và ứng dụng
1. Sử dụng lần lượt độ đo Gain và chỉ mục Gini để xây dựng cây quyết định. Trình bày
chi tiết từng bước. So sánh kết quả.
2. Áp dụng thuật toán ILA cho tập DL này để tìm tập luật phân lớp. So sánh kết quả với
tập luật rút ra từ cây quyết định (sử dụng chỉ mục Gini của câu 1)
3. Sử dụng phương pháp Naïve Bayes để tính các xác suất P(Ci) và P(xk|Ci) (Cột Class là
cột thuộc tính lớp).
4. Chuẩn hóa các xác suất bằng phương pháp làm trơn Laplace.
5. Xác định lớp cho các mẫu sau bằng các phương pháp:
a) Sử dụng cây quyết định ở câu 1) (theo độ đo Gain)
b) Sử dụng tập luật từ câu 2) (dùng ILA)
c) Sử dụng phương pháp Naïve Bayes (đã làm trơn theo Laplace)
d) So sánh kết quả của 3 phương pháp trên.
Bood Type Give Birth Can Fly Live in water Class
Cold No No Sometimes ?
Cold No Yes No ?
Cold No Yes Yes ?
Cold Yes No Yes ?
Cold Yes Yes Sometimes ?
Warm No No Yes ?
Warm No Yes Yes ?
Warm No Yes No ?
Warm Yes No Yes ?
Warm Yes No No ?
Warm Yes No Sometimes ?
Warm Yes Yes Sometimes ?
6. Cho bộ DL test dưới đây. Xác định lớp cho các mẫu trong bộ DL test bằng các phương
pháp:
a) Sử dụng cây quyết định ở câu 1) (theo độ đo Gain)
b) Sử dụng tập luật từ câu 2) (dùng ILA)
c) Sử dụng phương pháp Naïve Bayes (đã làm trơn theo Laplace)
d) Tính độ chính xác của từng phương pháp trên với các độ đo acc(M), error(M)
và độ đo Precision, Recall, F-measure cho từng lớp. Cột cuối cùng là Actual
class – lớp thực sự của các mẫu test.
09/2010
3. Khai thác dữ liệu và ứng dụng
Bộ Dữ liệu Test:
No Bood Type Give Birth Can Fly Live in water Class Actual Class
1 Cold No No Sometimes ? amphibians
5 Cold No No Yes ? fishes
11 Cold No No No ? reptiles
12 Cold No No Sometimes ? reptiles
6 Cold Yes No Yes ? fishes
2 Warm No No Sometimes ? birds
7 Warm No No No ? mammals
3 Warm No Yes No ? birds
4 Warm Yes No Sometimes ? birds
8 Warm Yes No No ? mammals
9 Warm Yes No Yes ? mammals
10 Warm Yes Yes No ? mammals
B. Thực hành
Tập dữ liệu: Zoo http://archive.ics.uci.edu/ml/datasets/Zoo - tập dữ liệu về động vật.
Câu hỏi:
1. Tạo tập tin Zoo.arff chứa dữ liệu Zoo.
2. Hãy mô tả tổng quát về dữ liệu Zoo:
a. Số mẫu
b. Tên và ý nghĩa các thuộc tính,
c. Đặc điểm về giá trị thiếu
d. Danh sách các phân lớp. Hãy đặt tên ngắn gọn cho mỗi phân lớp và chỉnh sửa file
Zoo.arff sao cho thuộc tính phân lớp gồm các tên mới này thay vì các con số từ 1
đến 7 như trong dữ liệu thô.
3. Trước khi tiến hành phân lớp trên dữ liệu này, hãy trả lời các câu hỏi sau:
a. Nhận xét về sự phân bố dữ liệu vào các lớp.
b. Theo bạn có thuộc tính nào không cần thiết trong bài toán phân lớp? Nếu có hãy
xóa nó đi.
c. Theo bạn cần áp dụng tiền xử lý không? Nếu có thì gồm các thao tác nào, giải
thích và áp dụng vào dữ liệu.
09/2010
4. Khai thác dữ liệu và ứng dụng
4. Phân lớp dữ liệu Zoo.arff: Tiến hành phân lớp với cách phân chia dữ liệu như sau: 50%
train, 50% test.
a. Sử dụng thuật toán Bayes
b. Sử dụng thuật toán ID3
c. Sử dụng thuật toán J48
d. Sử dụng thuật toán SVM (libsvm) 1
e. Trình bày kết quả: Liệt kê vào bảng, với mỗi thuật toán ghi lại kết quả 3 độ đo
(chỉ lấy giá trị tổng – Weighted Avg): precision, recall, f-measure.
Lưu ý: Quy ước khi thực hiện phân lớp cần chọn Preserve order for % Split trong More
Options.
f. Hãy nhận xét kết quả.
g. Với mỗi mô hình phân lớp đã thực hiện bên trên, cho biết kết quả mà mỗi mô
hình dự đoán cho 5 mẫu sau đây:
1. NameIsSecret,1,0,0,1,0,0,0,1,1,1,0,0,4,1,0,1,ClassIsUnknown
2. NameIsSecret,0,1,1,0,1,0,0,0,1,1,0,0,2,1,1,0,ClassIsUnknown
3. NameIsSecret,0,0,1,0,0,0,1,1,1,1,1,0,0,1,0,0,ClassIsUnknown
4. NameIsSecret,0,0,1,0,0,1,1,1,1,0,0,1,0,1,0,0,ClassIsUnknown
5. NameIsSecret,0,0,1,0,0,1,1,1,1,1,0,0,4,1,0,0,ClassIsUnknown
Ghi chú: thuộc tính class đang ghi là ClassIsUnknown
5. Trình bày cách tính giá trị độ đo tổng (Weigted Avg)
6. Thuật toán Bayes của Weka có xử lý được dữ liệu dạng số không? Nếu có trình bày cách
Weka thực hiện thuật toán này khi gặp dữ liệu dạng số1.
Lưu ý: Các yêu cầu đánh dấu 1 là yêu cầu không bắt buộc.
Hết
09/2010