This document provides a summary report of a research study combining multivariate control charts and neural networks to estimate the starting time of process disturbances. The study was conducted by graduate students at Fu Jen Catholic University under the guidance of Dr. Shao Yuehjen. The research aims to address the limitations of traditional univariate and multivariate control charts in identifying the starting point of process faults by leveraging the computational abilities of neural networks. The study develops theoretical frameworks for combining multivariate control charts with neural networks and conducts simulation experiments to demonstrate the advantages of the proposed approach over using control charts alone. The results show the combined method can more accurately and earlier detect the starting fault point, helping reduce costs and resume normal operations.







![IV
LIST OF TABLES
Table 3-1 RMSE for different numbers and learning rates..........................................32
Table 3-2 The correct determine rate in every threshold value ...................................33
Table 3-3 Example testing data ...................................................................................35
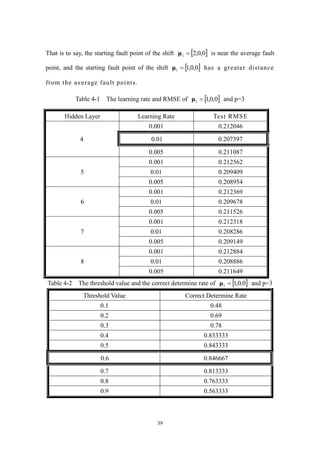
Table 4-1 The learning rate and RMSE of ]0,0,1[1 and p=3...............................39
Table 4-2 The threshold value and the correct determine rate of ]0,0,1[1 and p=3
....................................................................................................................39
Table 4-3 The models in different shifts of p=3 ..........................................................40
Table 4-4 The different starting fault points of p=3 in every Prob..............................40
Table 4-5 The models in different shifts of p=5 ..........................................................42
Table 4-6 The different starting fault points of p=5 in every Prob..............................42
Table 4-7 The models in different shifts of p=8 ..........................................................45
Table 4-8 The different starting fault points of p=8 in every Prob..............................45
Table 4-9 The models in different shifts of p=12 ........................................................48
Table 4-10 The different starting fault points of p=12 in every Prob..........................48
Table 4-11 The small shift outcomes in different quality characteristics
of Hotelling 2
T .......................................................................................51
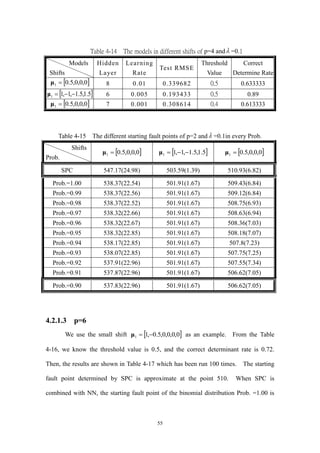
Table 4-12 The models in different shifts of p=2 and =0.1 ....................................53
Table 4-13 The different starting fault points of p=2 and =0.1in every Prob.........54
Table 4-14 The models in different shifts of p=4 and =0.1 ....................................55
Table 4-15 The different starting fault points of p=2 and =0.1in every Prob.........56
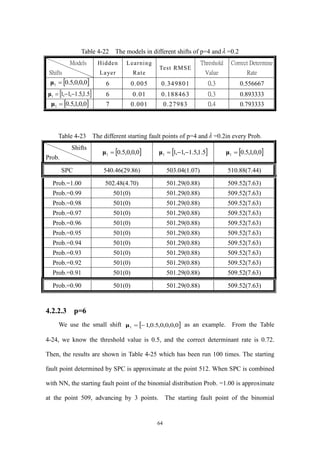
Table 4-16 The models in different shifts of p=6 and =0.1 ....................................57
Table 4-17 The different starting fault points of p=6 and =0.1in every Prob.........58](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-8-320.jpg)


![VII
LIST OF FIGURES
Figure 1-1 Research flow .............................................................................................4
Figure 3-1 Univariate control charts---the mean-standard deviation control chart....13
Figure 3-2 Control ellipse ( 1X , 2X are independent variables)..............................14
Figure 3-3 Control ellipse ( 1X , 2X are dependent variables).................................15
Figure 3-4 The shift 0 = [1, 0, 0] of Hotelling 2
T control chart.............................22
Figure 3-5 The shift 1 =[0.5,0,0] of Hotelling 2
T control chart .............................23
Figure 3-6 The basic construction of NN...................................................................28
Figure 3-7 The process of constructing NN model ....................................................30
Figure 3-8 RMSE trend chart .....................................................................................31](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-11-320.jpg)



















![20
Here ,00 Z ,10 jr pj ,...,2,1 。
The MEWMA control chart will be out of control in the condition:
hZZT iZii i
12
0h
The choice of the specific “in control” ARL (Average Run Length) is decided by
process personnel. If the parameters rrrrrr p 4321 , the statistics of
MEWMA can be written as:
,1-iZrIrXZ ii ,...2,1i
)}2/(])1(1[{ 2
rrr i
Zi
Here iZ is the covariance matrix of:
The MEWMA control chart can respond in a timely fashion when the process is out
control, especially the small shift, so producers can find the starting fault point of the
process quickly. Therefore, it would be a better choice when compared with other
multivariate control charts. The weakness of the MEWMA is restricted by the
correlation of data, and it cannot monitor biases or faults in time, so we can pair it with
the control line of the Hotelling 2
T chart and adjust the UCL and LCL. We also
combine the MEWMA with NN in hopes that it will have better differentiation ability
than combing the Hotelling 2
T control chart and NN.](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-31-320.jpg)











































![67
Prob. =0.99 is approximate at the point 511, advanced by 3 points. So the starting fault
point of the binomial distribution Prob. =0.90 is approximate the point 507, advanced
by 7 points. Thus when the quality characteristics p=10, and the shift is small, the
model can find the starting fault point earlier.
This is the same method used for the larger shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the
all shifts 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ cases. Since we previously assumed the
starting fault point is number 501, we cannot find the starting point after combining NN.
The results are all the same from Prob.=0.99 to Prob.=0.90. As mentioned above, the
determined effect of SPC in combination with NN in the big shift and all shift cases do
not appear when the shift is small.
Therefore, when only using SPC chart in p=10 and =0.2, the starting fault point is
far from the assumed point 501. There is a small distance between the starting fault
point found by SPC in combination with NN and point 501, which we assumed for the
study. Different shifts will affect the time needed to determine the starting fault point.
To determine the time needed for a small shift 0,0,0,0,0,0,0,0,0,11 μ is more obvious
than to find it for the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the all shifts
case 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ . In finding the standard deviation, we determine the
standard deviation in the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ to be 2.06, and 9.23 for
the small shift 0,0,0,0,0,0,0,0,0,11 μ , which are shown in Table 4-27. We discover
that the standard deviation in the small shift is greater than for the big shift. That is to
say, the starting fault point of the shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ is near the average
fault point, and the starting fault point of the shift 0,0,0,0,0,0,0,0,0,11 μ has a
greater distance from the average fault points.](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-78-320.jpg)
![68
Table 4-26 The models in different shifts of p=10 and =0.2.
Models
Shifts
Hidden
Layer
Learning
Rate
Test RMSE
Threshold
Value
Correct
Determine
Rate
0,0,0,0,0,0,0,0,0,11 μ 21 0.005 0.318932 0.5 0.61
]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ 21 0.005 0.216299 0.4 0.86
5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ 20 0.005 0.140889 0.3 0.953333
Table 4-27 The different starting fault points of p=10 and =0.2in every Prob.
Shifts
Prob.
0,0,0,0,0,0,0,0,0,11 μ ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ
SPC 513.33(9.23) 504.54(2.06)
Prob.=1.00 511.09(9.25) 502.04(2.23)
Prob.=0.99 510.41(8.94) 502.04(2.23)
Prob.=0.98 509.94(9.21) 502.04(2.23)
Prob.=0.97 509.44(8.77) 502.04(2.23)
Prob.=0.96 508.59(8.69) 502.04(2.23)
Prob.=0.95 508.27(8.59) 502.04(2.23)
Prob.=0.94 507.69(8.36) 502.04(2.23)
Prob.=0.93 507.45(8.24) 502.04(2.23)
Prob.=0.92 506.88(7.90) 502.04(2.23)
Prob.=0.91 506.43(7.65) 502.04(2.23)
Prob.=0.90 506.31(7.67) 502.04(2.23)](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-79-320.jpg)







![76
approximate at the point 514, advancing by 3 points. The starting fault point of the
binomial distribution Prob. =0.99 is approximate at the point 508, advance by 9 points.
So the starting fault point of the binomial distribution Prob. =0.90 is approximate the
point 504, advanced by 13 points. Thus when the quality characteristics p=10, and the
shift is small, the model can find the starting fault point earlier.
This is the same method used for the larger shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the
all shifts 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ cases. Since we previously assumed the
starting fault point is number 501, we cannot find the starting point after combining NN.
The results are all the same from Prob.=0.99 to Prob.=0.90. As mentioned above, the
determined effect of SPC in combination with NN in the big shift and all shift cases do
not appear when the shift is small.
Therefore, when only using SPC chart in p=10 and =0.2, the starting fault point is
far from the assumed point 501. There is a small distance between the starting fault
point found by SPC in combination with NN and point 501, which we assumed for the
study. Different shifts will affect the time needed to determine the starting fault point.
To determine the time needed for a small shift 0,0,0,0,0,0,0,0,0,11 μ is more obvious
than to find it for the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the all shifts
case 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ . In finding the standard deviation, we determine the
standard deviation in the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ to be 1.71, and 13.16 for
the small shift 0,0,0,0,0,0,0,0,0,11 μ , which are shown in Table 4-35. We discover
that the standard deviation in the small shift is greater than for the big shift. That is to
say, the starting fault point of the shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ is near the average
fault point, and the starting fault point of the shift 0,0,0,0,0,0,0,0,0,11 μ has a](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-87-320.jpg)
![77
greater distance from the average fault points.
Table 4-34 The models in different shifts of p=10 and =0.3
Models
Shifts
Hidden
Layer
Learning
Rate
Test RMSE
Threshold
Value
Correct
Determine
Rate
0,0,0,0,0,0,0,0,0,11 μ 22 0.001 0.311815 0.4 0.603333
]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ 18 0.005 0.227182 0.7 0.853333
5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ 18 0.05 0.140133 0.7 0.946667
Table 4-35 The different starting fault points of p=10 and =0.3 in every Prob.
Shifts
Prob.
0,0,0,0,0,0,0,0,0,11 μ ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ
SPC 516.73(13.16) 503.97(1.71)
Prob.=1.00 513.05(13.18) 502.46(2.00)
Prob.=0.99 507.06(10.68) 502.46(2.00)
Prob.=0.98 504.92(8.17) 502.46(2.00)
Prob.=0.97 504.65(8.18 502.46(2.00)
Prob.=0.96 504.45(8.20) 502.46(2.00)
Prob.=0.95 504.21(8.08) 502.46(2.00)
Prob.=0.94 504.21(8.08) 502.46(2.00)
Prob.=0.93 503.87(7.90) 502.46(2.00)
Prob.=0.92 503.47(7.67) 502.46(2.00)
Prob.=0.91 503.47(7.67) 502.46(2.00)
Prob.=0.90 503.29(7.62) 502.46(2.00)](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-88-320.jpg)






![84
Table 4-41 The different starting fault points of p=6 and =0.4 in every Prob.
Shifts
Prob.
0,0,0,0,5.0,11 μ 5.1,5.0,0,0,5.0,5.11 μ 1,1,1,1,1,11 μ
SPC 515.2(14.10) 503.8(2.07) 503.06(1.40)
Prob.=1.00 512.91(13.85) 501.72(1.61) 501.45(1.23)
Prob.=0.99 512.26(11.91) 501.72(1.61) 501.45(1.23)
Prob.=0.98 511.79(11.81) 501.72(1.61) 501.45(1.23)
Prob.=0.97 511.44(11.68) 501.72(1.61) 501.45(1.23)
Prob.=0.96 510.89(11.65) 501.72(1.61) 501.45(1.23)
Prob.=0.95 510.84(11.55) 501.72(1.61) 501.45(1.23)
Prob.=0.94 510.66(11.57) 501.72(1.61) 501.45(1.23)
Prob.=0.93 510.6(11.59) 501.72(1.61) 501.45(1.23)
Prob.=0.92 510.55(11.60) 501.72(1.61) 501.45(1.23)
Prob.=0.91 510.5(11.62) 501.72(1.61) 501.45(1.23)
Prob.=0.90 510.47(11.62) 501.72(1.61) 501.45(1.23)
4.2.4.4 p=10
We use the small shift 0,0,0,0,0,0,0,0,0,11 μ as an example. From the Table
4-42, we know the threshold value is 0.5, and the correct determinant rate is 0.646667.
Then, the results are shown in Table 4-43 which has been run 100 times. The starting
fault point determined by SPC is approximate at the point 518. When SPC is combined
with NN, the starting fault point of the binomial distribution Prob. =1.00 is approximate
at the point 513, advancing by 5 points. The starting fault point of the binomial
distribution Prob. =0.99 is approximate at the point 507, advanced by 11 points. So
the starting fault point of the binomial distribution Prob. =0.90 is approximate the point
502, advanced by 16 points. Thus when the quality characteristics p=10, and the shift
is small, the model can find the starting fault point earlier.
This is the same method used for the larger shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-95-320.jpg)
![85
all shifts 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ cases. Since we previously assumed the
starting fault point is number 501, we cannot find the starting point after combining NN.
The results are all the same from Prob.=0.99 to Prob.=0.90. As mentioned above, the
determined effect of SPC in combination with NN in the big shift and all shift cases do
not appear when the shift is small.
Therefore, when only using SPC chart in p=10 and =0.4, the starting fault point is
far from the assumed point 501. There is a small distance between the starting fault
point found by SPC in combination with NN and point 501, which we assumed for the
study. Different shifts will affect the time needed to determine the starting fault point.
To determine the time needed for a small shift 0,0,0,0,0,0,0,0,0,11 μ is more obvious
than to find it for the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ and the all shifts
case 5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ . In finding the standard deviation, we determine the
standard deviation in the big shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ to be 1.81, and 15.89 for
the small shift 0,0,0,0,0,0,0,0,0,11 μ , which are shown in Table 4-43. We discover
that the standard deviation in the small shift is greater than for the big shift. That is to
say, the starting fault point of the shift ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ is near the average
fault point, and the starting fault point of the shift 0,0,0,0,0,0,0,0,0,11 μ has a
greater distance from the average fault points.](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-96-320.jpg)
![86
Table 4-42 The models in different shifts of p=10 and =0.4.
Models
Shifts
Hidden
Layer
Learning
Rate
Test RMSE
Threshold
Value
Correct
Determine
Rate
0,0,0,0,0,0,0,0,0,11 μ 22 0.001 0.308062 0.4 0.646667
]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ 18 0.005 0.225005 0.5 0.866667
5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ 18 0.01 0.120946 0.5 0.966667
Table 4-43 The different starting fault points of p=10 and =0.4 in every Prob.
Shifts
Prob.
0,0,0,0,0,0,0,0,0,11 μ ]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ
SPC 517.88(15.89) 503.9(1.81)
Prob.=1.00 512.39(14.51) 502.18(1.79)
Prob.=0.99 506.41(10.05) 502.18(1.79)
Prob.=0.98 504.89(8.16) 502.18(1.79)
Prob.=0.97 503.49(5.57) 502.18(1.79)
Prob.=0.96 503.15(5.35) 502.18(1.79)
Prob.=0.95 502.26(2.86) 502.18(1.79)
Prob.=0.94 502.09(2.67) 502.18(1.79)
Prob.=0.93 502.05(2.68) 502.18(1.79)
Prob.=0.92 501.80(2.37) 502.18(1.79)
Prob.=0.91 501.70(2.25) 502.18(1.79)
Prob.=0.90 501.70(2.25) 502.18(1.79)](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-97-320.jpg)








![95
In MEWMA section, the starting fault point of =0.1, 0.2 and 0.4 are
close, but =0.3 is different, so we use =0.2 and 0.3 to account for the
conclusion.
Because the MEWMA control chart is designed to monitor the smallest shifts of
the process, it can find the starting fault points effectively after combining with NN.
Especially in the shift 0,0,0,5.01 μ , there are a lot of advance points, which
are shown in Table 5-2. When =0.2 and p=4, the starting fault points of the small
shift 0,0,0,5.01 μ has great advanced by 40 points. Only when =0.3, the
starting fault points has advanced by 10 points. However, the starting fault points
didn’t advance too much, it can precisely find out the starting fault points.
Table 5-2 Different shift outcomes when using MEWMA control chart in combination
with NN ( =0.2 and 0.3)
Advance Points
Shifts
MEWMA ( )
=0.2 =0.3
P=2
0,11 μ 4 9
0,5.11 μ 2 1
5.0,5.11 μ 2 3
P=4
0,0,0,5.01 μ 40 7
0,0,1,5.01 μ 2 9
5.1,5.1,1,11 μ 1 2
P=6
0,0,0,0,5.0,11 μ 6 2
5.1,5.0,0,0,5.0,5.11 μ 2 2
1,1,1,1,1,11 μ 2 2
P=10
0,0,0,0,0,0,0,0,0,11 μ 7 13
]0,5.1,0,1,0,5.0,0,1,0,5.0[1 μ 2 1
5.1,5.0,1,1,5.1,5.1,5.0,5.0,1,11 μ 1 1](https://image.slidesharecdn.com/f1d4dede-536f-4341-b39a-118315d4ace4-160718054338/85/slide-106-320.jpg)

































