eric sieverts
VOGIN-IP-lezing
21 maart2019
automatisch
metadateren:
categoriseren &
verrijken van digitale
informatie
http://sieverts.pbworks.com/f/welcome.html | sieverts@gmail.com | @sieverts
2.
automatisch metadateren?
wat verstaanwe daaronder?
het is eigenlijk "verrijken":
• woorden in een document automatisch verrijken met betekenis
• documenten automatisch classificeren (verrijken met metadata)
waarom?
wat? - materialen
hoe? - doelen
- methoden
- technieken
VOGIN-IP-lezing - 21 maart 2019
zie ook:
hoofdstuk 10
van open textbook
"Maak het vindbaar"
3.
waarom
handmatig metadateren/ontsluiten isduur
– vooral inhoudelijk toegankelijk maken kost veel tijd per document
het is te veel om het handmatig te doen
– er komen steeds meer documenten
– er komen steeds meer nieuwsberichten
– er komt steeds meer langs op twitter en sociale media
de aanwas gaat te snel om het
handmatig te kunnen doen
– twitter is niet bij te houden
VOGIN-IP-lezing - 21 maart 2019
4.
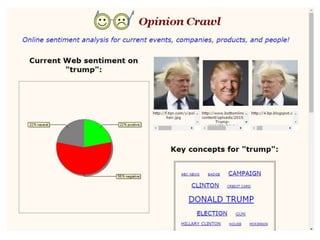
voorbeeld sentiment detection
veel:alles in nieuws en sociale media
snel: kan elk uur veranderen
in principe maar
2 categorieën:
VOGIN-IP-lezing - 21 maart 2019
7.
wat
soorten (digitaal) materiaal:
•tekstdocumenten
– artikelen
– mail
– bedrijfsdocumenten
– social media uitingen
– ....
• “documenten” zonder tekst
– foto's
– video
– geluid
waarom onderscheid?
• omdat je er verschillende
dingen mee kan
• omdat ze verschillende
technieken vereisen
VOGIN-IP-lezing - 21 maart 2019
8.
hoe : doel/ methode / techniek
twee doelen:
• named entity recognition (woorden/namen in documenten
verrijken met betekenis)
• classificatie (documenten verrijken met categorieaanduiding)
twee methoden:
• rule based (door mensen opgestelde indelingsregels)
• training (computer leert zelf uit voorbeelden – machine learning)
technieken:
• taaltechnieken (NLP)
• statistiek (tf*idf)
• machine learning
VOGIN-IP-lezing - 21 maart 2019
9.
doelen
globaal twee doelen(en toepassingen)
• named entity recognition : speciale begrippen
(entiteiten) in documentinhoud ontdekken / herkennen
bepaalde typen woorden (persoonsnaam, plaatsnaam, bedrijfsnaam,
productnaam, gebeurtenis e.d.) worden herkend, gemarkeerd en
eventueel gelinkt aan achtergrondinformatie
• karakterisering aan documenten toevoegen
(thesaurustermen, categorieën, korte beschijvingen)
op basis van analyse van documentinhoud wordt die gematcht met
beschikbare termen of categorieën, zodat document ingedeeld of
van termen voorzien kan worden
VOGIN-IP-lezing - 21 maart 2019
10.
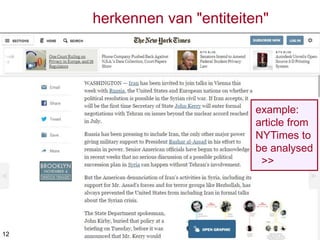
named entity recognition
•speciale begrippen (entiteiten) worden in
documentinhoud herkend
• maakt daartoe gebruik van
– lijsten, databases e.d. met persoonsnamen, plaatsnamen,
bedrijfsnamen, productnamen, gebeurtenissen e.d.
(bijvoorbeeld Wikidata)
– natuurlijke taalanalyse (o.a. voor bepaling woordsoorten)
– machine learning; bijvoorbeeld voor disambigueren
• jaguar: dier / auto
• einstein: albert / alfred
• cricket: dier / sport
VOGIN-IP-lezing - 21 maart 2019
albert alfred
11.
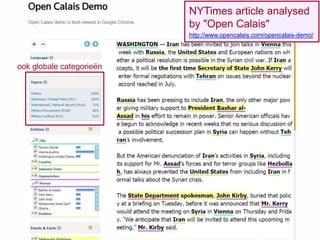
The Calais WebService
automatically creates
rich semantic metadata
Named
Entities
Facts Events
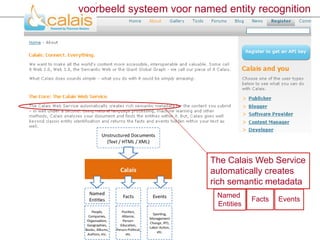
voorbeeld systeem voor named entity recognition
oefening named
entity recognition
•Automatische "entity recognition" met "OpenCalais"
(plus ook onderwerpsclassificatie)
Ga naar http://www.opencalais.com/opencalais-demo/
• Eenvoudig "entity recognition" tool "Annie".
Ga naar http://services.gate.ac.uk/annie/
• Toepassing in onderzoeksportal KB
Ga naar http://www.kbresearch.nl/xportal
Zie uitgedeelde opdrachten voor details
VOGIN-IP-lezing - 21 maart 2019
16.
automatisch classificeren /
verrijkenvan (tekst-)documenten
toevoegen van karakterisering
in feite geautomatiseerde inhoudelijke ontsluiting
vooral gebruikt voor:
– toevoegen van trefwoorden / categorieën / classificatiecodes
daarnaast ook mogelijk voor:
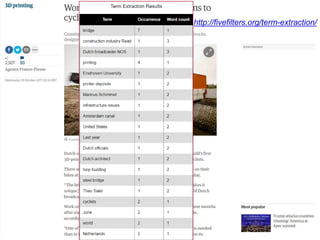
– genereren van “signature”: verzameling van meest identificerende
termen uit een document (zie http://fivefilters.org/term-extraction/)
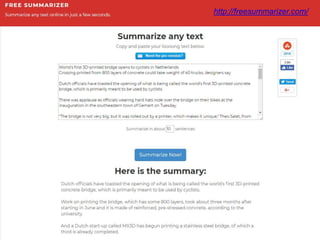
– genereren van samenvatting van tekst (zie http://freesummarizer.com/)
[oefening volgt zo mogelijk later]
VOGIN-IP-lezing - 21 maart 2019
toevoegen van
trefwoorden /categorieën
globaal twee methoden:
• op basis van (vaak handmatig opgestelde) kennisregels
(veel "if .... then ...." of Boolean queries)
• op basis van training door voorbeelddocumenten
"machine learning"
omdat werkelijkheid meestal te complex is, met te veel
afhankelijkheden, om die te beschrijven in een hanteerbaar
aantal "if … then's"
VOGIN-IP-lezing - 21 maart 2019
20.
kennisregel voor klassekan bijv.
complexe boolean query zijn
Childhood Obesity
((child* OR adolescent* OR youth OR girl* OR boy*) NEAR/5 obesity) OR
((obesity NEAR/5 (prevent* OR trend OR challenge OR solving OR solution OR
prevalence)) NEAR/10 (child* OR youth* OR adolescent* OR girl* OR boy*)) OR
(("healthy weight" OR overweight OR obese) NEAR/5 (child* OR adolescent* OR
youth)) OR (("body mass index" OR BMI) NEAR/5 (child* OR adolescent* OR
youth)) OR ((child* OR adolescent* OR youth) NEAR/5 ("healthy habits" OR
"healthy behavior*" OR (health* NEAR/5 eat*))) OR ("dietary guidelines" NEAR/5
(child* OR youth* OR adolescent* OR girl* OR boy*)) ("nutritional standards"
NEAR/5 (school NEAR/5 (meal* OR lunch* OR snack* OR breakfast*))) OR
(("sweet* beverage*" OR (sugar* NEAR/5 drink*)) NEAR/5 school* NEAR/10 (kids
OR child* OR adolescent* OR youth)) OR (obesity NEAR/5 prevent*) OR ((lower
OR reduce) NEAR/5 obesity) OR ("healthy weight commitment" NEAR/5 (child*
OR adolescent* OR youth)) OR ("active living research" NEAR/5 (child* OR
adolescent* OR youth)) OR (("physical activity" OR "physical education" OR
"physically active" OR "physical fitness") NEAR/10 (child* OR adolescent* OR
youth* OR girl* OR boy* OR school*)) OR ((activity OR "activity pattern*") NEAR/5
(child* OR adolescent* OR youth* OR girl* OR boy*))
21.
kennisregels opstellen
• kennisregelsopstellen is arbeidsintensief
• lijkt wat achterhaald door succes van "machine
learning" technieken
• toch soms nog toegepast
bijv. IPTC (International Press
Telecommunications Council)
heeft Media Topics taxonomy
(voor het classificeren van nieuws)
met kennisregels geautomatiseerd
VOGIN-IP-lezing - 21 maart 2019
22.
machine learning techniek
voortoepassing van "machine learning" bestaan allerlei
verschillende technieken
welke de beste is, hangt onder meer af van:
• aard van het materiaal
(voor tekst heel anders dan voor beeldherkenning)
• soort toepassing (bij "sentiment" of "spam" detectie [2 klassen]
heel anders dan bij "topics" [>1000 klassen] )
vooraf blijkt slecht te voorspellen welke van de vele
mogelijke toe te passen technieken voor een bepaalde
taak het beste zal werken
VOGIN-IP-lezing - 21 maart 2019
23.
laat de softwarezelf uitzoeken wat er te herkennen valt
• enkele toepassingen
– rubriceren van nieuws, oktrooien, wetenschappelijke artikelen
(zie: http://www.slideshare.net/suzanv/automatische-classificatie-van-teksten)
– spamdetectie
– taalherkenning
– genreclassificatie
– interpretatie wat zoeker met zoekvraag bedoelt (Google Rankbrain)
– medische diagnose (radiologische beelden, symptomen, …)
– spraakherkenning
– zelfrijdende auto
– predictive policing
– ….
VOGIN-IP-lezing - 21 maart 2019
intermezzo machine learning
24.
laat de softwarezelf uitzoeken wat er te herkennen valt
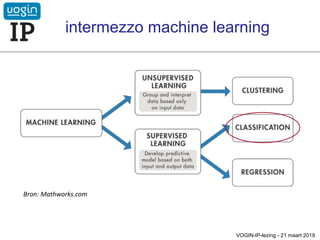
• supervised :
bij elk trainingsitem "zeg je" - expliciet of impliciet - wat het is, tot
welke categorie het behoort
dat zijn de meeste verdere toepassingen in deze workshop
gevaar: bias in trainingsmateriaal kan bijv. vooroordelen aanleren
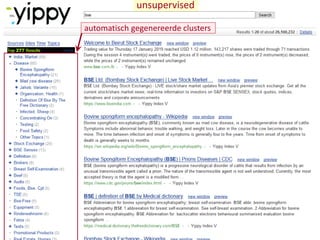
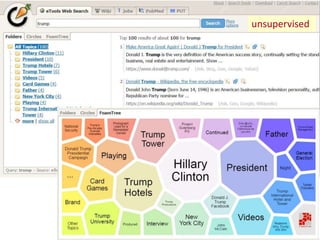
• unsupervised :
de software moet alles zelf uitzoeken, patronen vinden e.d.
bijvoorbeeld documentclustering (zoals bij metazoekmachines
Yippy en Carot2)
VOGIN-IP-lezing - 21 maart 2019
intermezzo machine learning
vaak toegepaste technieken:
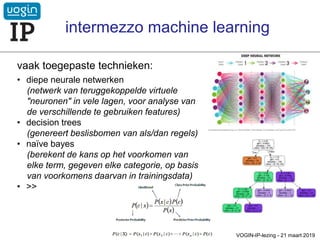
•diepe neurale netwerken
(netwerk van teruggekoppelde virtuele
"neuronen" in vele lagen, voor analyse van
de verschillende te gebruiken features)
• decision trees
(genereert beslisbomen van als/dan regels)
• naïve bayes
(berekent de kans op het voorkomen van
elke term, gegeven elke categorie, op basis
van voorkomens daarvan in trainingsdata)
• >>
VOGIN-IP-lezing - 21 maart 2019
intermezzo machine learning
29.
vaak toegepaste technieken:
•support vector machines
(zoekt verschil tussen twee categorieën door
voorbeelden uit trainingsdata te nemen die als
vectoren net op de grens daartussen liggen)
• k-nearest neighbours
(vindt voorbeelden in de trainingsdata die het
meest lijken op het te classificeren document)
• regressie algoritmes
(o.a. voor numerieke voorspellingen)
VOGIN-IP-lezing - 21 maart 2019
je kunt werken met een experimentele omgeving
waar je methoden kunt vergelijken, bijvoorbeeld Scikit-learn in Python
in Rapidminer-studio data- en textmining applicatie zitten ook diverse
machine learning tools voor tekstclassificatie
intermezzo machine learning
30.
producten waarmee jeuiteenlopende
toepassingen kunt bouwen
• IBM Watson
"suite of enterprise-ready AI
services, applications and tooling"
– versloeg de kampioenen van Jeopardy (2011)
– gebruik voor medische toepassingen
– bij banken, technische bedrijven, ….
• Google TensorFlow
open source framework en
software library
enkele toepassingen door Google:
– Rankbrain – interpreteert o.a. zoekvragen
– Deepmind – gespecialiseerd in games,
versloeg wereldkampioen go, Lee Sedol (2016)
intermezzo machine learning
VOGIN-IP-lezing - 21 maart 2019
31.
machine learning toepassing
stappenbij een supervised learning toepassing
1. taak definiëren
2. bepalen welke kenmerken (features) systeem moet bekijken
3. materiaal voorbewerken
4. trainingsmateriaal selecteren
5. systeem analyseert trainingsdocumenten (feature extraction)
6. systeem wordt getraind door matchen van trainings-
documenten met “klassen” (supervised learning)
7. systeem evalueren door testdocumenten te laten "klasseren"
8. systeem "bijleren" bij probleemgevallen
9. nieuwe documenten laten “klasseren”
VOGIN-IP-lezing - 21 maart 2019
32.
wat moet gekarakteriseerdworden?
– hele documenten
– afzonderlijke hoofdstukken/secties
– afzonderlijke alinea's
– afzonderlijke zinnen
– afbeeldingen
uit welke categorieën/klassen moet gekozen?
– weinig klassen
– flink aantal klassen in platte lijst
– veel klassen in hiërarchische structuur
– te gebruiken taxonomie / thesaurus
1. taak definiëren
VOGIN-IP-lezing - 21 maart 2019
33.
welke kenmerken inhet trainingsmateriaal moeten
geanalyseerd worden voor het leer- en matchingproces
• voor tekstdocumenten zullen dat kenmerken van de tekst in
de documenten zijn
– voor (wetenschappelijke) artikelen of nieuws gewoon de woorden
– voor spamdetectie en sentimentanalyse misschien ook
voorkomen van hoofdletters en leestekens
• voor beeldherkenning zullen dat bijvoorbeeld vormen,
kleuren, contouren, patronen, textuur e.d. zijn
– voor persoonsherkenning bovendien specifieke gezicht-
gerelateerde kenmerken
in kant-en-klare tools is dat al voorgeprogrammeerd
2. features bepalen
VOGIN-IP-lezing - 21 maart 2019
34.
• losse woordenin tekst herkenbaar maken (tokenization)
• stopwoorden of speciale tekens verwijderen? (wel / niet / welke)
• verfijning door taaltechnologische analyse (NLP)
software doet zinsontleding (POS) en herkent o.a. woordsoorten,
woordstammen, samenstellingen, "noun / lexical phrases", enz.
vooral ten behoeve van "normalisatie”:
– Morfologisch: manager, gemanaged
– Decompounding: hockeytoernooi → hockey, toernooi
– Noun phrases: information retrieval, opwarming van de aarde
– Syntactisch: energiebesparing, besparing van energie
– Semantisch: transport, vervoer
o.a. om bij statistische analyse die varianten te kunnen samennemen
in kant-en-klare tools is dat al voorgeprogrammeerd
3. voorbewerken
VOGIN-IP-lezing - 21 maart 2019
35.
• kies materiaalvoor elke categorie
• kies materiaal dat al gecategoriseerd is
• liefst vele tientallen tot enkele honderden
voorbeelden per categorie
• bij moeilijk probleem meer voorbeelden
• liefst geen materiaal dat tot meer categorieën
behoort
4. selecteren trainingsmateriaal
VOGIN-IP-lezing - 21 maart 2019
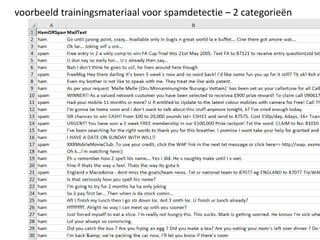
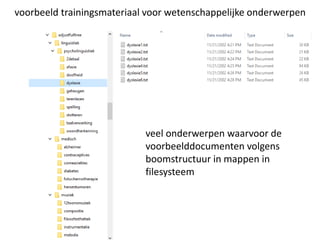
voorbeeld trainingsmateriaal voorwetenschappelijke onderwerpen
veel onderwerpen waarvoor de
voorbeelddocumenten volgens
boomstructuur in mappen in
filesysteem
38.
5. analysetechnieken
• hethangt af van de te gebruiken kenmerken (features)
welke analysemethoden moeten worden toegepast
• hier voorlopig even over toepassingen die kenmerken
van tekst gebruiken
in kant-en-klare tools is dat al voorgeprogrammeerd
VOGIN-IP-lezing - 21 maart 2019
39.
analysetechnieken - statistiek
techniekenvoor analyse van tekstdocumenten
1. statistiek
van document wordt “profiel” (soort vingerafdruk) gemaakt
door extractie van meest karakteristieke woorden en
bepaling van hun "gewicht",
meestal op basis van relatieve woordfrequenties
tf idf :
term-frequentie x inverse document frequentie;
levert termen die in document vaker voorkomen maar die
verder zeldzaam zijn
VOGIN-IP-lezing - 21 maart 2019
40.
tfidf analyse
• tf= term frequentie
computer turft van alle woorden in document hoe vaak ze voorkomen
• idf = inverse document frequentie (df)
computer zoekt op in hoeveel andere documenten dat woord voorkomt
• computer deelt term frequentie door document frequentie
("invers = delen door")
compensatie voor hoge tf van algemeen voorkomende woorden
voorbeeld:
in praktijk vaak nog verfijning door logaritmes in formule te verwerken
bijv.: idf = log N/df waar N=totaal aantal documenten
woord tf df tfidf log .
de 30 40.000 0,00075 0,99
in 15 30.000 0,00050 1,14
compensatie 1 40 0,025 3,40
vingerafdruk 2 16 0,125 4,94
technieken voor analysevan documenten
2. regels (ook voor "profiel")
software bepaalt op basis van vaste - handmatig ingestelde -
regels welke termen karakteristiek zijn voor (bepaalde
aspecten van) de inhoud van een document
• omdat ze in de titel staan
• omdat ze met hoofdletters zijn geschreven
• omdat ze in een vastgelegd rijtje woorden voorkomen
• vanwege markup-tags
• …...
analysetechnieken – rule based
VOGIN-IP-lezing - 21 maart 2019
matchen van documenten
metklassen
vergelijking van vingerafdruk van (nieuw) document met
vingerafdrukken van alle klassen (thesaurustermen)
– matching bijvoorbeeld met “vector-model”
ingestelde drempelwaarden bepalen vaak
– betrouwbaarheid van toekenning
– aantal toegekende klassen (maximaal/minimaal)
denk ook hier aan 80/20 regel
– hoe hoger de ingestelde betrouwbaarheidsdrempel,
hoe meer handmatig te verwerken twijfelgevallen (en
omgekeerd)
VOGIN-IP-lezing - 21 maart 2019
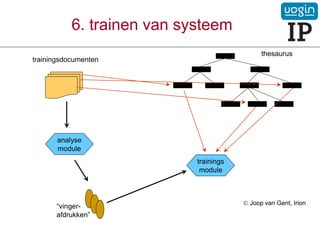
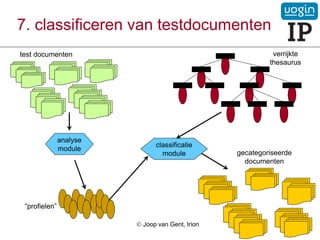
47.
7. classificeren vantestdocumenten
verrijkte
thesaurus
test documenten
analyse
module
“profielen”
classificatie
module gecategoriseerde
documenten
Joop van Gent, Irion
48.
met begrippen recallen precisie
recall = # correct geklasseerd / # relevant (A/A+C)
precisie= # correct geklasseerd / # geklasseerd (A/A+B)
vb: Er zijn totaal 10 documenten over onderwerp X (A+C = 10),
6 daarvan zijn als zodanig geklasseerd (A = 6) >> recall = 60%
Er zijn 8 documenten als X geklasseerd (A+B = 8),
6 daarvan gaan echt over X (A = 6) >> precisie = 75%
beoordeling van test
VOGIN-IP-lezing - 21 maart 2019
relevant
voor klasse
niet relevant
voor klasse
totaal
geklasseerd # correct A # niet correct B
(false positives)
# geklasseerd A+B
niet geklasseerd # niet correct C
(false negatives)
#correct # niet geklasseerd
totaal # relevant A+C # niet relevant
49.
het resultaat isnooit perfect:
• > 90% zou erg mooi zijn, maar 60-80% is realistischer
• vaak is er afweging tussen belang van precisie en recall
kwaliteit hangt af van
• moeilijkheid van de taak: hoe meer categorieën, hoe
moeilijker
• hoeveelheid trainingsdocumenten (per categorie tientallen,
maar liever honderden documenten nodig)
• lengte van de documenten: korte documenten zijn moeilijker
te classificeren
analyseer waar de problemen zitten en probeer daar iets
aan te doen (dat was stap 8)
beoordeling van test
VOGIN-IP-lezing - 21 maart 2019
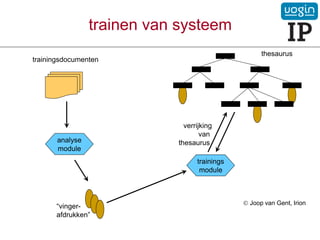
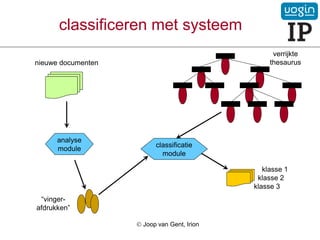
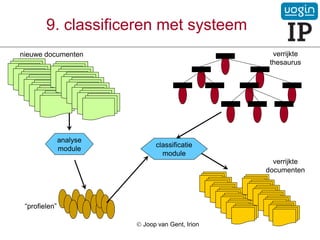
50.
9. classificeren metsysteem
verrijkte
thesaurus
nieuwe documenten
analyse
module
“profielen”
verrijkte
documenten
Joop van Gent, Irion
classificatie
module
uit keynote vanJoseph Busch "The newest technologies for automatic tagging"
(Taxonomy Bootcamp Londen, 10/2017 en VOGIN-IP-lezing Amsterdam, 3/2018)
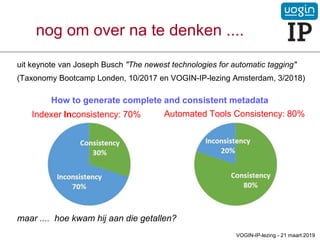
maar .... hoe kwam hij aan die getallen?
nog om over na te denken ....
Indexer Inconsistency: 70% Automated Tools Consistency: 80%
How to generate complete and consistent metadata
VOGIN-IP-lezing - 21 maart 2019
55.
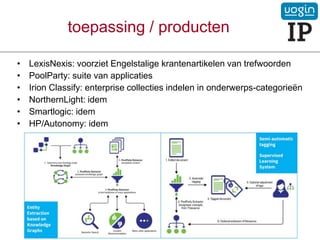
toepassing / producten
•LexisNexis: voorziet Engelstalige krantenartikelen van trefwoorden
• PoolParty: suite van applicaties
• Irion Classify: enterprise collecties indelen in onderwerps-categorieën
• NorthernLight: idem
• Smartlogic: idem
• HP/Autonomy: idem
oefening automatische
classificatie
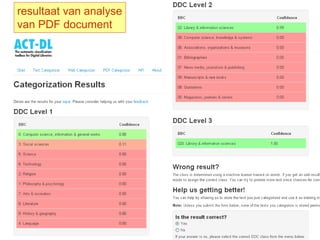
1. Automatischetoekenning van Dewey Decimale Classificatie met ACT-DL
Ga naar http://act-dl.base-search.net/
Engelse of Duitse teksten classificeren met Dewey Decimale Classificatie
2. Automatische trefwoordtoekenning voor een catalogus
Ga naar het Finse Annif http://annif.org/
Aan ingeplakte stukken Engelse (of Finse) tekst trefwoorden toekennen
3. Automatische toekenning van thesaurustermen met Climate Tagger
Ga naar de website http://api.climatetagger.net/demo/
Thesaurustermen toekennen an klimaatgerelateerde teksten
4. Automatische genrebepaling (KB) op http://www.kbresearch.nl/genre/
5. Bepaling leesbaarheidsniveau van teksten op https://wizescan.com/
6. Zie eventueel nog de in de vorige sheet genoemde demo-systemen
Zie uitgedeelde opdrachten voor meer details
VOGIN-IP-lezing - 21 maart 2019
58.
• ook wel:"opinion mining"
• probeert de houding (attitude) van de auteur van een tekst vast te
stellen (in twitterberichten, mailtjes, facebook, blogs e.d.)
• meestal drie mogelijkheden (positief – negatief – onbepaald)
soms ook "polarity" in getal uitgedrukt
• soms maar heel korte teksten (twitter)
• verdere uitdagingen:
– mensen uiten opinies op complexe manier
– tekst is vaak multi-interpretabel
• sarcasme, ironie, insinuatie
• expressiviteit, taalgebruik (‘straattaal’ )
– subjectiviteit
– fake / spam reviews
– ….
sentiment analysis
VOGIN-IP-lezing - 21 maart 2019
oefening sentiment
analysis
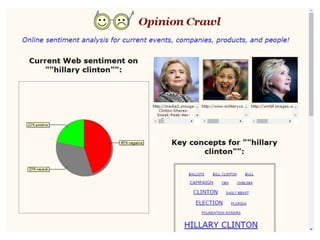
1. Voorbeeldenvan systemen voor "sentiment analysis"
Probeer enkele systemen met eigen tekst of zoekwoorden
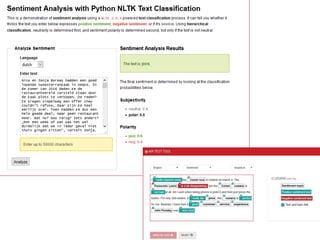
– Python NLTK Text Classification: http://text-processing.com/demo/sentiment/
Analyse van in te plakken stukken Engelse, Nederlandse of Franse tekst
– Opinion Crawl: http://www.opinioncrawl.com/
Nieuwsanalyse op basis van een zoekterm
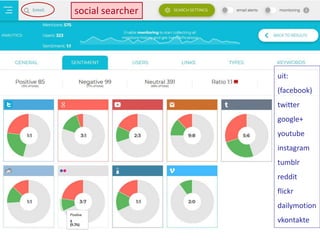
– Social Searcher: https://www.social-searcher.com/
Zoekt in diverse sociale media en toont onder "Detailed statistics" het
"sentiment" van gevonden berichten voor elk van de doorzochte bronnen
– Twinword: https://www.twinword.com/api/sentiment-analysis.php
Analyse van ingeplakte (Engelse) tekst; toont scores op woord niveau.
2. Nog wat meer voorbeelden voor "sentiment analysis"
Zie de uitgedeelde opdrachten voor details daarover
VOGIN-IP-lezing - 21 maart 2019
63.
automatisch categoriseren
van beeldmateriaal
eris (meestal) geen tekst waarop je voorgaande technieken
kunt toepassen
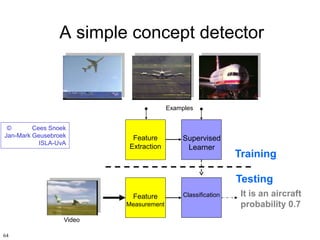
men noemt dit wel "semantische concept detectie"
• op basis van (veel) voorbeelden – soms zowel positieve als
negatieve - leert de computer door machine learning techniek, per
individueel concept hoe die in afbeeldingen (ook in video) te
herkennen zijn
• zoekmachines als Google en Baidu noemen dit "deep learning"
omdat ze voor training diepe neurale netwerken gebruiken
• op internet is veel getagd materiaal beschikbaar dat voor training
gebruikt kan worden
63
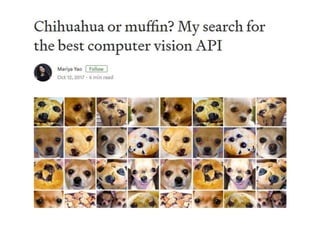
getraind op basisvan miljoenen voorbeelden,
herkent Google in images ook afzonderlijke
objecten en beschrijft het geheel in zinnetjes
Chris Shallue (2016). Show and Tell: image
captioning open sourced in TensorFlow.
Google Research Blog, September 22, 2016.
https://research.googleblog.com/2016/09/show-
and-tell-image-captioning-open.html
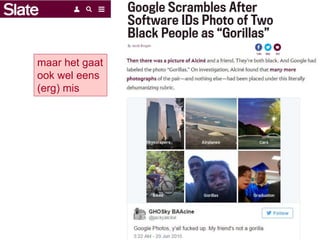
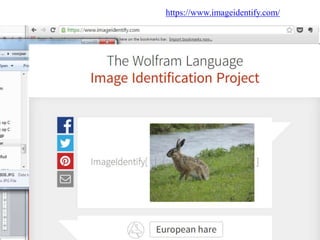
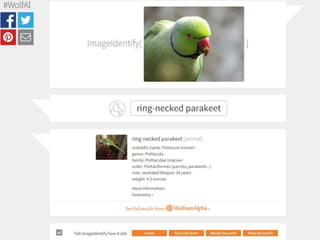
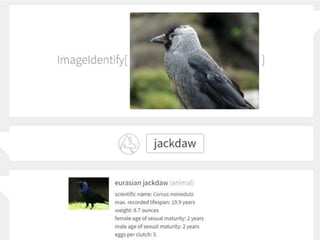
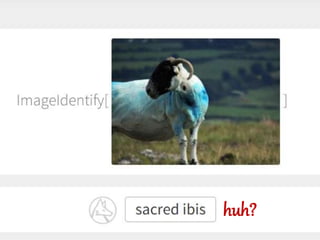
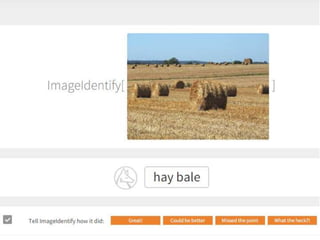
oefening beeldherkenning
• Voorbeeldvan automatische beeldherkenning
Probeer de Wolfram Image Identification:
https://www.imageidentify.com/
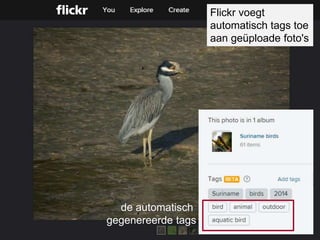
• Voorbeeld van automatisch aan foto's toegekende tags
Bekijk autogenerated tags op de site van Flickr:
https://www.flickr.com/
Zie uitgedeelde opdrachten voor details
VOGIN-IP-lezing - 21 maart 2019
80.
automatisch categoriseren
van beeldmateriaal
voorgezichtsherkenning op het niveau van individuele personen
zijn veel specifiekere methoden nodig, die uitgaan van "features"
van menselijke gezichten en waarbij de methode bestand moet
zijn tegen ruimtelijk transformaties
80
81.
… wel ietsingewikkelder dan het vinden van Waldo …
oefening genereren van
signatureof samenvatting
• Automatische term extractie / genereren van "signature"
Ga naar http://fivefilters.org/term-extraction/
• Automatische tekst summarizer
Ga naar http://freesummarizer.com/ en kies "Summarize Text".
NB: Niet zeker of deze nog gratis gebruikt kan worden.
Zie uitgedeelde opdrachten voor details
VOGIN-IP-lezing - 21 maart 2019
85.
oefening unsupervised
clustering
• Realtime clusteren van zoekresultaten
met Yippy metasearch: https://yippy.com
• Real time clusteren van zoekresultaten
met Carrot2 metasearch: http://search.carrot2.org/
Zie uitgedeelde opdrachten voor details
VOGIN-IP-lezing - 21 maart 2019











![automatisch classificeren /
verrijken van (tekst-)documenten
toevoegen van karakterisering
in feite geautomatiseerde inhoudelijke ontsluiting
vooral gebruikt voor:
– toevoegen van trefwoorden / categorieën / classificatiecodes
daarnaast ook mogelijk voor:
– genereren van “signature”: verzameling van meest identificerende
termen uit een document (zie http://fivefilters.org/term-extraction/)
– genereren van samenvatting van tekst (zie http://freesummarizer.com/)
[oefening volgt zo mogelijk later]
VOGIN-IP-lezing - 21 maart 2019](https://image.slidesharecdn.com/autoclas-voginip-kort-190316124442/85/Automatische-classificatie-16-320.jpg)



![machine learning techniek
voor toepassing van "machine learning" bestaan allerlei
verschillende technieken
welke de beste is, hangt onder meer af van:
• aard van het materiaal
(voor tekst heel anders dan voor beeldherkenning)
• soort toepassing (bij "sentiment" of "spam" detectie [2 klassen]
heel anders dan bij "topics" [>1000 klassen] )
vooraf blijkt slecht te voorspellen welke van de vele
mogelijke toe te passen technieken voor een bepaalde
taak het beste zal werken
VOGIN-IP-lezing - 21 maart 2019](https://image.slidesharecdn.com/autoclas-voginip-kort-190316124442/85/Automatische-classificatie-22-320.jpg)