Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Shota Yasui
PDF, PPTX
1,215 views
Contextual package
Rのcontextual packageの紹介です。
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PDF
DataRobotを用いた要因分析 (Causal Analysis by DataRobot)
by
Yuya Yamamoto
PDF
L 05 bandit with causality-公開版
by
Shota Yasui
PDF
何故あなたの機械学習はビジネスを改善出来ないのか?
by
Shota Yasui
PPTX
重回帰分析で頑張る
by
Shota Yasui
PDF
セレンディピティと機械学習
by
Kei Tateno
PDF
機械学習の課題設定講座
by
幹雄 小川
PDF
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
PDF
動的最適化の今までとこれから
by
Kazuki Baba
DataRobotを用いた要因分析 (Causal Analysis by DataRobot)
by
Yuya Yamamoto
L 05 bandit with causality-公開版
by
Shota Yasui
何故あなたの機械学習はビジネスを改善出来ないのか?
by
Shota Yasui
重回帰分析で頑張る
by
Shota Yasui
セレンディピティと機械学習
by
Kei Tateno
機械学習の課題設定講座
by
幹雄 小川
『手を動かしながら学ぶ ビジネスに活かすデータマイニング』で目指したもの・学んでもらいたいもの
by
Takashi J OZAKI
動的最適化の今までとこれから
by
Kazuki Baba
Similar to Contextual package
PDF
強化学習勉強会・論文紹介(第30回)Ensemble Contextual Bandits for Personalized Recommendation
by
Naoki Nishimura
PDF
Introduction to contexual bandit
by
正志 坪坂
PDF
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
PPTX
Pycon reject banditアルゴリズムを用いた自動abテスト
by
Shoichi Taguchi
PDF
Contexual bandit @TokyoWebMining
by
正志 坪坂
PPTX
バンディット問題について
by
jkomiyama
PDF
バンディットアルゴリズム入門と実践
by
智之 村上
PPTX
Counterfaual Machine Learning(CFML)のサーベイ
by
ARISE analytics
PPTX
Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス
by
Shoichi Taguchi
強化学習勉強会・論文紹介(第30回)Ensemble Contextual Bandits for Personalized Recommendation
by
Naoki Nishimura
Introduction to contexual bandit
by
正志 坪坂
いろんなバンディットアルゴリズムを理解しよう
by
Tomoki Yoshida
Pycon reject banditアルゴリズムを用いた自動abテスト
by
Shoichi Taguchi
Contexual bandit @TokyoWebMining
by
正志 坪坂
バンディット問題について
by
jkomiyama
バンディットアルゴリズム入門と実践
by
智之 村上
Counterfaual Machine Learning(CFML)のサーベイ
by
ARISE analytics
Pydata_リクルートにおけるbanditアルゴリズム_実装前までのプロセス
by
Shoichi Taguchi
More from Shota Yasui
PDF
PaperFriday: The selective labels problem
by
Shota Yasui
PDF
TokyoR 20180421
by
Shota Yasui
PDF
木と電話と選挙(causalTree)
by
Shota Yasui
PDF
計量経済学と 機械学習の交差点入り口 (公開用)
by
Shota Yasui
PDF
Factorization machines with r
by
Shota Yasui
PDF
Estimating the effect of advertising with Machine learning
by
Shota Yasui
PPTX
Prml nn
by
Shota Yasui
PPTX
Xgboost for share
by
Shota Yasui
PDF
Dynamic panel in tokyo r
by
Shota Yasui
PDF
Rで部屋探し For slide share
by
Shota Yasui
PDF
Salmon cycle
by
Shota Yasui
PaperFriday: The selective labels problem
by
Shota Yasui
TokyoR 20180421
by
Shota Yasui
木と電話と選挙(causalTree)
by
Shota Yasui
計量経済学と 機械学習の交差点入り口 (公開用)
by
Shota Yasui
Factorization machines with r
by
Shota Yasui
Estimating the effect of advertising with Machine learning
by
Shota Yasui
Prml nn
by
Shota Yasui
Xgboost for share
by
Shota Yasui
Dynamic panel in tokyo r
by
Shota Yasui
Rで部屋探し For slide share
by
Shota Yasui
Salmon cycle
by
Shota Yasui
Contextual package
1.
contextual package Japan.R Shota Yasui 2018/12/1
2.
Shota Yasui (@housecat442) 所属:
Adtech Studio AILab 経歴: 2013年 CA新卒入社 広告事業本部 2015年 Adtech Studio 異動 DMP 2016年 Dynalyst(DSP)→ProfitX(SSP) 2017年 AILabで研究をスタート 元々は経済学と因果推論をやってました。 アドテクでは機械学習利用の設計や検証をしたり、 機械学習の知識を前提としたデータ分析をやってます。 2
3.
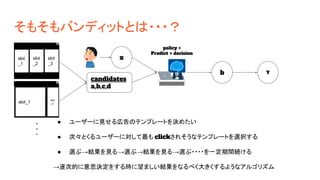
そもそもバンディットとは・・・? x candidates a,b,c,d b Y policy = Predict
+ decision slot _1 slot _2 slot _3 slot_1 slot _2 ● ユーザーに見せる広告のテンプレートを決めたい ● 次々とくるユーザーに対して最も clickされそうなテンプレートを選択する ● 選ぶ→結果を見る→選ぶ→結果を見る→選ぶ・・・・を一定期間続ける →逐次的に意思決定をする時に望ましい結果をなるべく大きくするようなアルゴリズム
4.
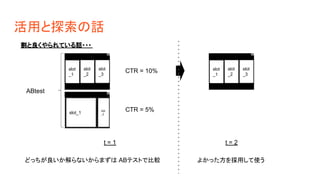
活用と探索の話 slot _1 slot _2 slot _3 slot_1 slot _2 ABtest CTR = 10% CTR
= 5% slot _1 slot _2 slot _3 t = 1 t = 2 割と良くやられている話・・・ どっちが良いか解らないからまずは ABテストで比較 よかった方を採用して使う
5.
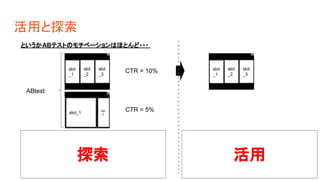
活用と探索 slot _1 slot _2 slot _3 slot_1 slot _2 ABtest CTR = 10% CTR
= 5% slot _1 slot _2 slot _3 t = 1 t = 2 というかABテストのモチベーションはほとんど・・・ どっちが良いか解らないからまずは ABテストで比較 よかった方を採用して使う探索 活用
6.
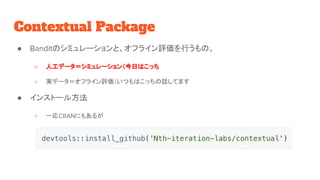
Contextual Package ● Banditのシミュレーションと、オフライン評価を行うもの。 ○
人工データ=シミュレーション(今日はこっち ○ 実データ=オフライン評価(いつもはこっちの話してます ● インストール方法 ○ 一応CRANにもあるが
7.
Epsilon-Greedy ● 選択肢の性能を評価して、最も良さそうなものを一定確率で選ぶ。 a. この確率をEpsilonと呼ぶ ●
選択肢の評価方法 a. 単純に集計する:click回数/表示回数 を選択肢ごとに算出 b. モデルで評価する:選択肢ごとに回帰モデルを作ってユーザーの情報とかを入れる ➡このふたつを比較するシミュレーションを行う
8.
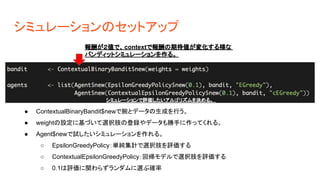
シミュレーションの設定を決める シミュレーションのiteration回数を決める。2000回意思決定させる。 同じシミュレーションを何回繰り返すか決める。 50回 列が選択肢を表す。 →1列目は選択肢1がサンプルタイプ1で0.8の性能があり、他では 0.1しか性能がないことを示している。 行がContextを表す。 →1行目はサンプルタイプ1で、選択肢1が
0.8の性能があり他の選択肢は 0.1しか性能がないことを示す。 三つの腕と、三つのタイプのサンプルで、 それぞれの性能を決める。
9.
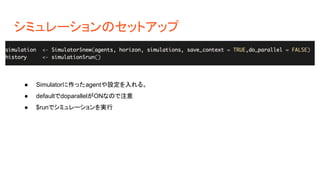
シミュレーションのセットアップ 報酬が2値で、contextで報酬の期待値が変化する様な バンディットシミュレーションを作る。 シミュレーションで評価したいアルゴリズムを決める。 ● ContextualBinaryBandit$newで腕とデータの生成を行う。 ● weightの設定に基づいて選択肢の登録やデータも勝手に作ってくれる。 ●
Agent$newで試したいシミュレーションを作れる。 ○ EpsilonGreedyPolicy:単純集計で選択肢を評価する ○ ContextualEpsilonGreedyPolicy:回帰モデルで選択肢を評価する ○ 0.1は評価に関わらずランダムに選ぶ確率
10.
シミュレーションのセットアップ ● Simulatorに作ったagentや設定を入れる。 ● defaultでdoparallelがONなので注意 ●
$runでシミュレーションを実行
11.
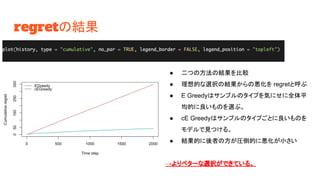
regretの結果 ● 二つの方法の結果を比較 ● 理想的な選択の結果からの悪化を
regretと呼ぶ ● E Greedyはサンプルのタイプを気にせに全体平 均的に良いものを選ぶ。 ● cE Greedyはサンプルのタイプごとに良いものを モデルで見つける。 ● 結果的に後者の方が圧倒的に悪化が小さい →よりベターな選択ができている。
12.
何が嬉しいのか? ● 色々な設定で検証ができる ○ 他の意思決定方法と性能を比較できる ○
Agentを自分で実装しなくて良いので楽 ● 実問題を想定した評価もできる ○ Replay Methodの再現とかもできる ○ ランダムに選択したログをプロダクトからもらえば、バンディットでどの程度改善できそうかは示すこ とができる。
13.
Enjoy!
Download