Download as PDF, PPTX




![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Some movation for using clustering
Statistical modelling is difficult as the time series
are non stationary, e.g. economic regimes are changing, it
can be misleading to use data from a too distant past
are near efficient, i.e. behaving nearly like random walks (cf.
the efficient-market hypothesis (Fama, 1970) [5])
have a low signal-to-noise ratio, i.e. measure artifacts hide
information in random fluctuations
are in an unfavorable statistical setting, too few relevant
observations (length) wrt the number of variables (time series)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-4-320.jpg)




![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Introduction to the CDS raw dataset
Putting Self-Supervised Token Embedding on the Tables [15]
(ICMLA 2017)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-9-320.jpg)
![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
A ‘tick-by-tick’ dataset
Autoregressive Convolutional Neural Networks for Asynchronous
Time Series [1] (ICML Time Series WS 2017)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-10-320.jpg)
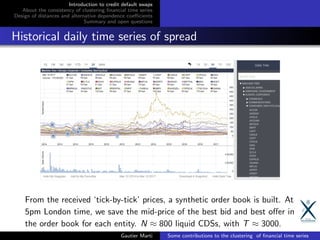

![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Clustering of Financial Time Series
Stylized fact I: Financial time series correlations have a strong
hierarchical block diagonal structure (Mantegna, 1999) [6]
https://gmarti.gitlab.io/ml/2017/09/07/how-to-sort-distance-matrix.html
Stylized fact II: Most correlations are spurious (Bouchaud,
1999) [3]
Motivation for clustering financial time series using correlation as a
similarity measure:
dimensionality reduction ≡ filtering noisy correlations
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-13-320.jpg)

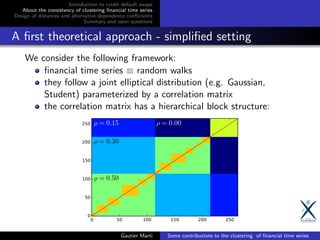
![Hierarchical clustering algorithms - A taxonomy
We consider Hierarchical Agglomerative Clustering algorithms.
Such as single linkage, average linkage, Ward.
Space contracting vs. Space conserving vs. Space dilating [2]
D(t+1)
C
(t)
i
∪ C
(t)
j
, C
(t)
k
≤ min D
(t)
ik
, D
(t)
jk
D(t+1)
C
(t)
i
∪ C
(t)
j
, C
(t)
k
∈
min D
(t)
ik
, D
(t)
jk
, max D
(t)
ik
, D
(t)
jk
D(t+1)
C
(t)
i
∪ C
(t)
j
, C
(t)
k
≥ max D
(t)
ik
, D
(t)
jk
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-16-320.jpg)






![Correlation estimates concentration bounds
number of variables N, observations T, minimum separation d
Concentration bounds [4]
If Σ and ˆΣ are the population and empirical Spearman correlation
matrices respectively, then for N ≥ 24
log T + 2, we have with
probability at least 1 − 1
T2 ,
ˆΣ − Σ ∞ ≤ 24
log N
T
.
P(“correct clustering”) ≥ 1 − 2N2
e−Td2/24
Not sharp enough for reasonable values of N, T, d.
For example, for N = 500, T = 2500, d = 0.2, we obtain
≈ −7750.
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-23-320.jpg)
![Future developments & open questions
Bounds are not sharp enough. We can try to refine them using:
(theoretical) Intrinsic dimension of the HCBM model [16];
(theoretical Use PSD-ness to refine the bounds for the matrix
(theoretical/empirical) A distance between dendrograms
(instead of correct/incorrect) for a finer analysis;
(empirical) A study of ‘correctness’ isoquants:
Precise convergence rates of clustering methodologies can provide
a useful model selection criterion for practitioners!
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-24-320.jpg)

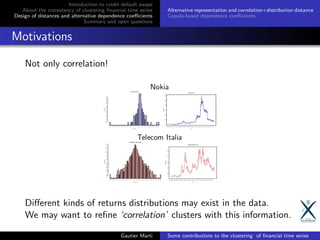

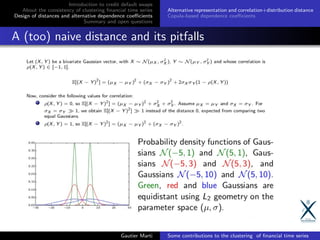


![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
A novel representation for time series
Basically, we transform each time series of returns to a (normalized
ranks, square root of marginal density) vector.
Applying a L2 between two of these vectors is now equivalent to a
distance in Spearman correlation + Hellinger between the densities.
cf. (Marti et al., 2016) [13] (Pattern Recognition Letters) for more
details on this representation and the associated distance.
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-31-320.jpg)
![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Analysing the differences - Using the Sankey diagram
cf. (Marti et al., 2015) [14] (ICMLA 2015) for guidelines on how to
compare several clustering methodologies for financial time series.
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-32-320.jpg)

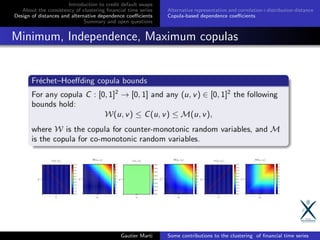
![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Relation to existing dependence coefficients
Some dependence coefficients can be readily expressed as:
deviation from Fr´echet-Hoeffding bounds
Spearman’s ρS = 1 − 6 [0,1]2 (ui − uj )2
dC(ui , uj ),
Gini’s γ,
Kendall distribution distance,
deviation from independence ui uj
Spearman ρS = 12 [0,1]2 (C(ui , uj ) − ui uj )dui
duj
,
Copula MMD,
Schweizer-Wolff’s σ,
Hoeffding’s φ2
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-35-320.jpg)

![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Optimal Transport between empirical copulas
cf. (Marti et al., 2016) [12] (ICASSP 2016)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-37-320.jpg)
![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Why choosing Optimal Transport over f -divergences?
Distances between Gaussian copulas C1, C2, C3:
cf. (Marti et al., 2016) [7] (SSP 2016)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-38-320.jpg)
![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Standard setting: TFDC vs. Spearman
cf. (Marti et al., 2017) [8] (NIPS Time Series WS 2016)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-39-320.jpg)

![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Alternative representation and correlation+distribution distance
Copula-based dependence coefficients
Some applications of the Target/Forget Dependence
Coefficient
Applications in non-standard settings: We can look for particular
associations between random variables.
cf. (Marti et al., 2017) [8] (NIPS Time Series 2016)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-41-320.jpg)
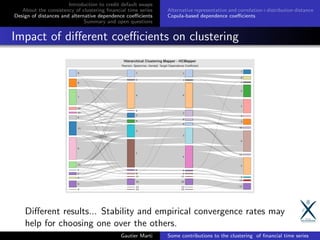

![Introduction to credit default swaps
About the consistency of clustering financial time series
Design of distances and alternative dependence coefficients
Summary and open questions
Summary of contributions
The contribution of the PhD thesis:
bring a greater focus on statistical reliability (convergence
rates and consistency) [9] (IJCAI 2016)
consider alternative representation and distances [13]
(Pattern Recognition Letters), [8] (NIPS Time Series 2016)
visualizations [10] and a framework to test for clustering
stability [14] (ICMLA 2015)
an extensive and regularly updated survey of the literature:
https://arxiv.org/pdf/1703.00485.pdf [11] (350+
references)
Gautier Marti Some contributions to the clustering of financial time series](https://image.slidesharecdn.com/gmartiphddefense-171111143021/85/Some-contributions-to-the-clustering-of-financial-time-series-Applications-to-credit-default-swaps-44-320.jpg)

















This document discusses contributions to clustering financial time series, specifically credit default swap data. It introduces credit default swaps and the raw data set. It then discusses challenges in clustering financial time series due to non-stationarity and noisy correlations. It presents initial work on analyzing the consistency of clustering as the sample size increases, through simulations in a simplified setting. Finally, it proposes a two-step approach to proving consistency, by first identifying geometrical configurations that lead to the true clustering structure.




























































