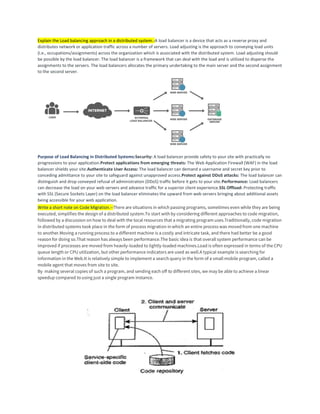
1. Explain the Load balancing approach in a distributed system.-A load balancer is a device that acts as a reverse proxy and
distributes network or application traffic across a number of servers. Load adjusting is the approach to conveying load units
(i.e., occupations/assignments) across the organization which is associated with the distributed system. Load adjusting should
be possible by the load balancer. The load balancer is a framework that can deal with the load and is utilized to disperse the
assignments to the servers. The load balancers allocates the primary undertaking to the main server and the second assignment
to the second server.
Purpose of Load Balancing in Distributed Systems:Security: A load balancer provide safety to your site with practically no
progressions to your application.Protect applications from emerging threats: The Web Application Firewall (WAF) in the load
balancer shields your site.Authenticate User Access: The load balancer can demand a username and secret key prior to
conceding admittance to your site to safeguard against unapproved access.Protect against DDoS attacks: The load balancer can
distinguish and drop conveyed refusal of administration (DDoS) traffic before it gets to your site.Performance: Load balancers
can decrease the load on your web servers and advance traffic for a superior client experience.SSL Offload: Protecting traffic
with SSL (Secure Sockets Layer) on the load balancer eliminates the upward from web servers bringing about additional assets
being accessible for your web application.
Write a short note on Code Migration.--There are situations in which passing programs, sometimes even while they are being
executed, simplifies the design of a distributed system.To start with by considering different approaches to code migration,
followed by a discussion on how to deal with the local resources that a migrating program uses.Traditionally, code migration
in distributed systems took place in the form of process migration in which an entire process was moved from one machine
to another.Moving a running process to a different machine is a costly and intricate task, and there had better be a good
reason for doing so.That reason has always been performance.The basic idea is that overall system performance can be
improved if processes are moved from heavily-loaded to lightly-loaded machines.Load is often expressed in terms of the CPU
queue length or CPU utilization, but other performance indicators are used as well.A typical example is searching for
information in the Web.It is relatively simple to implement a search query in the form of a small mobile program, called a
mobile agent that moves from site to site.
By making several copies of such a program, and sending each off to different sites, we may be able to achieve a linear
speedup compared to using just a single program instance.
2. Write short note on File Caching Schemes.A file-caching scheme for a distributed file system contributes to its scalability and
reliability as it is possible to cache remotely located data on a client node. Every distributed file system use some form of file
caching.The following can be used:1.Cache Location-Cache location is the place where the cached data is stored. There can
be three possible cache locationsi.Servers main memory:A cache located in the server’s main memory eliminates the disk
access cost on a cache hit which increases performance compared to no caching.The reason for keeping locating cache in
server’s main memory-Easy to implement,Totally transparent to clients,Easy to keep the original file and the cached data
consistent.ii.Clients disk: If cache is located in clients disk it eliminates network access cost but requires disk access cost on a
cache hit. This is slower than having the cache in servers main memory. Having the cache in server’s main memory is also
simpler.iii.Clients main memory --A cache located in a client’s main memory eliminates both network access cost and disk
access cost. This technique is not preferred to a client’s disk cache when large cache size and increased reliability of cached
data are desired.2.Modification propagation--When the cache is located on client’s nodes, a files data may simultaneously
be cached on multiple nodes. It is possible for caches to become inconsistent when the file data is changed by one of the
clients and the corresponding data cached at other nodes are not changed or discarded.The modification propagation
scheme used has a critical effect on the systems performance and reliability.
What are different data-centric consistency models?-1)Continuous Consistency---It is true that, there is no best solution
to replicate the data on different machines in network. Efficient solutions can be possible if we consider some
relaxation in consistency. The tolerance while considering the relaxation also depends on application. Applications
can specify their tolerance of inconsistencies in three ways. These are:Variation in numerical values between
replicas.Variation in staleness between replicas.Variation with respect to the ordering of update operations.
2)Consistent Ordering of Operations---In parallel and distributed computing, multiple processes share the resources.
These processes access these resources simultaneously. The semantics of concurrent access to these resources
when resources are replicated led to use of consistency model.
3)Sequential Consistency--The time axis is drawn horizontally and interpretation of read and write operation by
process on data item is given below. Initially each data item is considered as NIL. Wi(x)a: Process P, perform write
operation on data item x with value a R,(x)b :Process Pi perform read operation on data item x which return value b.
4)Causal Consistency-Causal consistency model makes distinction between the events that are causally related and
those that are not causally related. If any event b is caused or occurred by previous event y then every process first
should see y and then x. Causally consistent data store follows the following condition:
5)FIFO Consistency--FIFO consistency is the next step in relaxing the consistency by dropping requirement of seeing
the causally related writes in same order at all the processes. It is also called the PRAM consistency. It is easy to
implement. It says that All the processes must see the writes done by single process in the order in which they were
issued. The writes from different processes, processes may see in different order.
Explain Hadoop Distributed File System (HDFS).--HDFS is a distributed file system that handles large data sets running on
commodity hardware. It is used to scale a single Apache Hadoop cluster to hundreds (and even thousands) of
nodes. HDFS is one of the major components of Apache Hadoop, the others being MapReduce and YARN. HDFS
should not be confused with or replaced by Apache HBase, which is a column-oriented non-relational database
management system that sits on top of HDFS and can better support real-time data needs with its in-memory
processing engine.HDFS follows the master-slave architecture and it has the following elements.Namenode---The
namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software.
It is a software that can be run on commodity hardware. The system having the namenode acts as the master server
and it does the following tasks −Manages the file system namespace.Regulates client’s access to files.It also
executes file system operations such as renaming, closing, and opening files and directories.Datanode------The
datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node
(Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their
system.Datanodes perform read-write operations on the file systems, as per client request.They also perform
operations such as block creation, deletion, and replication according to the instructions of the namenode.Block---
Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more
segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the
3. minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be
increased as per the need to change in HDFS configuration.