16Contributing to Embulkproject
・Pull-requests & issues on Github
・Posting blogs
・“I tried Embulk. here is how it worked”
・“I read Embulk code. Here is how it’s written”
・Embulk is good because…but bad because…
・Talking on Twitter with a word “embulk”
・Writing & releasing plugins
・Windows support
・Integration to other software
・ETL, Fluentd, Hadoop, Presto…
https://github.com/embulk/embulk



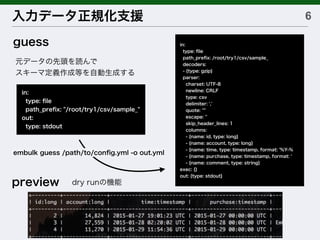
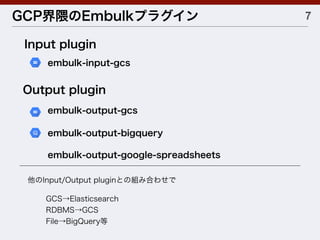


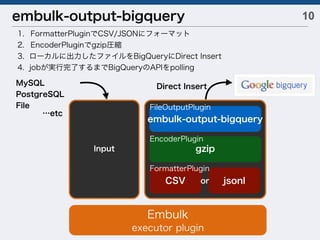






































![[db tech showcase Tokyo 2014] D33: Prestoで実現するインタラクティブクエリ by トレジャーデータ株式会社 斉藤太郎](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014d33presto-141120012543-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] 最新アップデート Google Cloud データ関連ソリューション 2020年5月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=640&height=640&fit=bounds)










