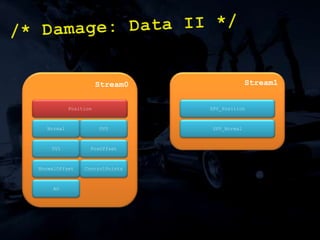
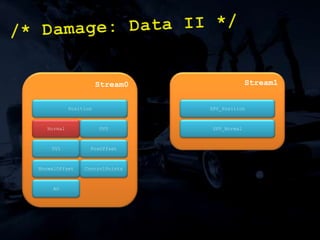
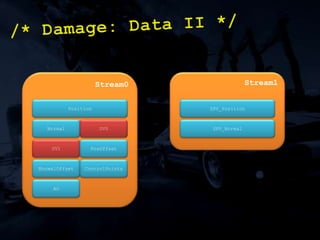
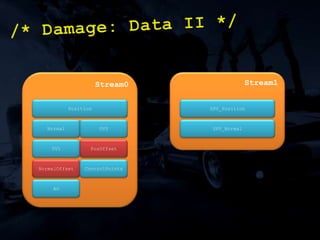
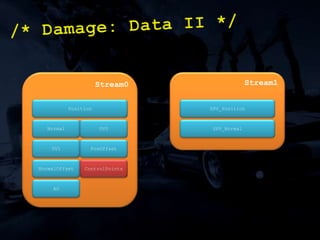
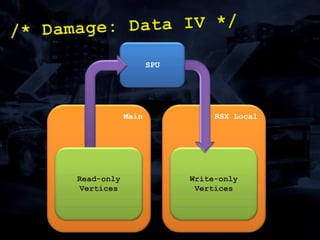
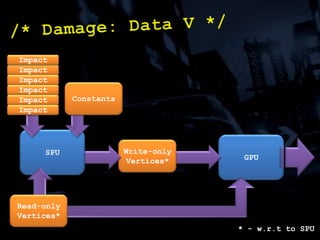
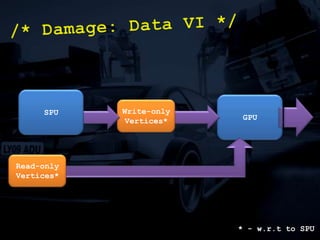
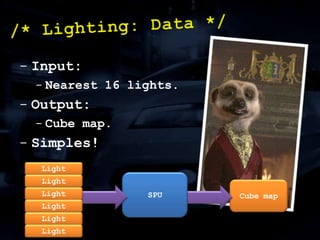
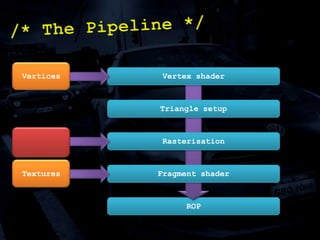
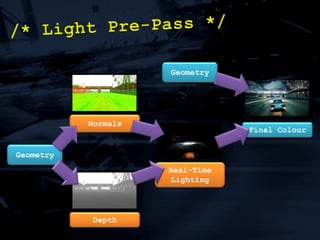
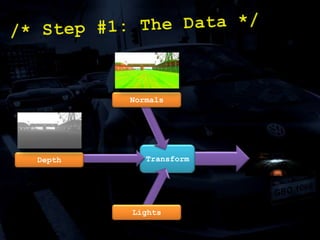
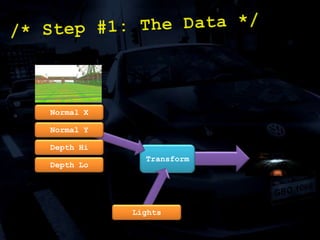
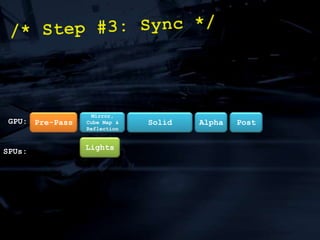
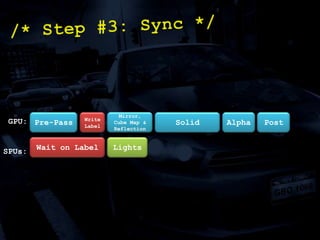
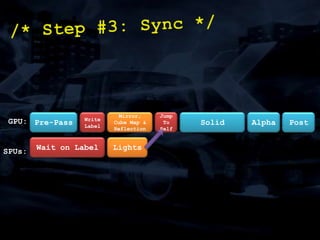
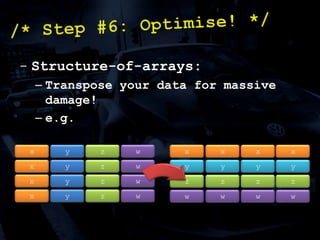
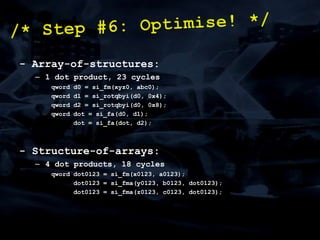
The document discusses 'SPU Assisted Rendering' in the context of the game 'Blur', detailing techniques for car damage rendering and parallelization of fragment shading using the SPUs in a multi-core setup. It covers case studies on optimizing rendering speed and quality, addressing memory considerations and the structure of data for efficient processing. The presentation emphasizes the importance of minimizing synchronization points and dynamically managing workloads to enhance rendering performance.









































































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

