Downloaded 16 times





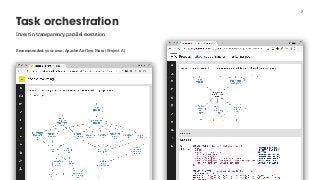
![Target of computation
CREATE TABLE m_dim_next.region (
region_id SMALLINT PRIMARY KEY,
region_name TEXT NOT NULL UNIQUE,
country_id SMALLINT NOT NULL,
country_name TEXT NOT NULL,
_region_name TEXT NOT NULL
);
Do computation and store result in table
WITH raw_region
AS (SELECT DISTINCT
country,
region
FROM m_data.ga_session
ORDER BY country, region)
INSERT INTO m_dim_next.region
SELECT
row_number()
OVER (ORDER BY country, region ) AS region_id,
CASE WHEN (SELECT count(DISTINCT country)
FROM raw_region r2
WHERE r2.region = r1.region) > 1
THEN region || ' / ' || country
ELSE region END AS region_name,
dense_rank() OVER (ORDER BY country) AS country_id,
country AS country_name,
region AS _region_name
FROM raw_region r1;
INSERT INTO m_dim_next.region
VALUES (-1, 'Unknown', -1, 'Unknown', 'Unknown');
Speedup subsequent transformations
SELECT util.add_index(
'm_dim_next', 'region',
column_names := ARRAY ['_region_name', ‘country_name',
'region_id']);
SELECT util.add_index(
'm_dim_next', 'region',
column_names := ARRAY ['country_id', 'region_id']);
ANALYZE m_dim_next.region;
6
SQL as data processing language
@martin_loetzsch
Tables as (intermediate) results of processing steps](https://image.slidesharecdn.com/2017-10-16reducingpainindataengineering-171116231609/85/Reducing-Pain-in-Data-Engineering-Data-Natives-2017-6-320.jpg?cb=1510874884)

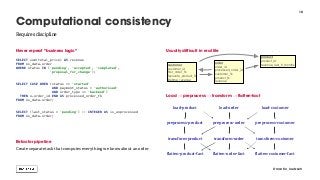
![It’s easy to make mistakes during ETL
DROP SCHEMA IF EXISTS s CASCADE; CREATE SCHEMA s;
CREATE TABLE s.city (
city_id SMALLINT,
city_name TEXT,
country_name TEXT
);
INSERT INTO s.city VALUES
(1, 'Berlin', 'Germany'),
(2, 'Budapest', 'Hungary');
CREATE TABLE s.customer (
customer_id BIGINT,
city_fk SMALLINT
);
INSERT INTO s.customer VALUES
(1, 1),
(1, 2),
(2, 3);
Customers per country?
SELECT
country_name,
count(*) AS number_of_customers
FROM s.customer JOIN s.city
ON customer.city_fk = s.city.city_id
GROUP BY country_name;
Back up all assumptions about data by constraints
ALTER TABLE s.city ADD PRIMARY KEY (city_id);
ALTER TABLE s.city ADD UNIQUE (city_name);
ALTER TABLE s.city ADD UNIQUE (city_name, country_name);
ALTER TABLE s.customer ADD PRIMARY KEY (customer_id);
[23505] ERROR: could not create unique index "customer_pkey"
Detail: Key (customer_id)=(1) is duplicated.
ALTER TABLE s.customer ADD FOREIGN KEY (city_fk)
REFERENCES s.city (city_id);
[23503] ERROR: insert or update on table "customer" violates
foreign key constraint "customer_city_fk_fkey"
Detail: Key (city_fk)=(3) is not present in table "city"
9
Referential consistency
@martin_loetzsch
Only very little overhead, will save your ass](https://image.slidesharecdn.com/2017-10-16reducingpainindataengineering-171116231609/85/Reducing-Pain-in-Data-Engineering-Data-Natives-2017-9-320.jpg?cb=1510874884)






Making the data of a company accessible to analysts, business users and data scientists can be a quite painful endeavor. In the past 5 years, Project A has supported many of its portfolio companies with building data infrastructures and we experienced many of these pains first-hand. In this talk, I will show how some of these pains can be overcome by applying common sense and standard software engineering best practices. Extended version of this talk: http://www.ustream.tv/recorded/109227465 Related: https://www.youtube.com/watch?v=EVMvC9Ov6Vw&t=410s















































